Boofuzz 源码分析
最近又有需要用到fuzz服务器的需求,找来找去还是觉得boofuzz是最靠谱的,以前就做过boofuzz源码的一些分析,这次就正好整理一下
Boofuzz样例
以一个tftp Fuzzer为例,大概看一下Boofuzz的用法
1 | from boofuzz import * |
在源码中可以看到SocketConnection会在未来版本中移除,现在应该使用BaseSocketConnection
1 | warnings.warn( |
Fuzzer的创建包含三层,Session -> Target -> Connection
Connection
顾名思义,Connection对象是网络连接的代表,Boofuzz支持各种基于socket的连接,从源码部分就可以看到,常用的还是TCP和UDP,这里还支持网络协议栈中2层和3层的原生Socket,不过我还没用过。
1 | def SocketConnection( |
在SocketConnection函数中根据我们传入的proto参数来调用响应Connection类的构造函数
以TCPSocketConnection为例,其继承自BaseSocketConnection
1 | class TCPSocketConnection(base_socket_connection.BaseSocketConnection): |
BaseSocketConnection是一个继承了itarget_connection.ITargetConnection接口的抽象基类
1 | class BaseSocketConnection(with_metaclass(abc.ABCMeta, itarget_connection.ITargetConnection)): |
python元类编程
抽象类和接口都是面向对象里面的概念,抽象类是指一类不可直接实例化,只可被继承的类,接口则定义了继承接口的类必须实现的方法,python是没有这两个概念相关的关键字的,在python中,抽象类是以抽象基类的方式实现的(abstract base classes(ABC))
ABC中提供了@abstractmethod装饰器来指定抽象方法,下面代码中定义了一个抽象类C,并且定义了三个抽象方法,D类则是继承抽象类C然后实现了他的方法。
1 | import abc |
这里BaseSocketConnection的定义中用到了with_metaclass来创建这个类
Python Metaclass : Understanding the ‘with_metaclass()’ - Stack Overflow
这里引入with_metaclass是为了兼容python2和python3,在我的python3.8上with_metaclass如下
1 | def with_metaclass(meta, *bases): |
根据BaseSocketConnection传入的参数,这里meta是ABCmeta,bases是ITargetConnection,这里是定义了一个临时元类metaclass继承自ABCmeta,并重写了其new方法,这样下面return时,就会依次调用其new和init方法来新建一个对象,而元类创建的是一个类,因此结果是一个基类为bases的抽象类,然后BaseSocketConnection就继承自它,不过这里this_bases的含义就很迷,我自己调试的话,这里会因为this_bases等于空而走到第一个return上,这样就不会继承bases,不过后来我添加打印代码后,确实是继承了ITargetConnection的。。迷惑

总之这里BaseSocketConnection继承了ITargetConnection的接口,定义了一些基本方法,open send recv close以及关于延时的变量等
TCPSocketConnection
来看看具体的TCPSocket的实现,
open
1 | def open(self): |
open_socket函数
就是创建一个socket
1 | def _open_socket(self): |
connect_socket
这里可以看到boofuzz支持server被连接的模式,只会接受一个连接,如果是多连接的场景,需要自己修改对应逻辑,主动连接同理
1 | def _connect_socket(self): |
send
就是socketsend
1 | def send(self, data): |
recv
这里可以设定最大接受字节数
1 | def recv(self, max_bytes): |
可以看出Connection这层就已经实现了连接的建立以及数据的收发相关的功能
Target
1 | class Target(object): |
Target注释部分也说了,Target对象主要是在Connection的接口上包上log,可以看到send函数,除了加的repeater功能,基本上就是加了圈log
1 | def open(self): |
另外Target中还有一些Monitor的初始化工作,后面再说,Target中提供了设置Logger的接口函数
1 | def set_fuzz_data_logger(self, fuzz_data_logger): |
在session中会调用这个函数来添加logger,默认是FuzzLoggerText
Session Logger部分
Session对象可以看成整个fuzzer的后端对象,其参数基本上就是涉及到fuzz控制的各种粒度,其函数基本上就是fuzz过程了,fuzz过程后面再分析,这里先看下上面余留的logger的部分,
1 | class Session(pgraph.Graph): |
如果fuzz_loggers没指定的话,这里就设置成FuzzLoggerText,而FuzzLoggerText默认会设置为标注输出,因此就形成了打印到终端,所以如果我们想输出到文件,就可以set自己new的FuzzLoggerText,并设置其file_handle为文件句柄
1 | class FuzzLoggerText(ifuzz_logger_backend.IFuzzLoggerBackend): |
数据格式
boofuzz是基于格式的,因此在开始fuzz前需要先定义目标数据格式,boofuzz有两种数据定义的方式Static Protocol Definition(old)和 Protocol Definition(new),这两种数据定义的方式只是接口不同,其内部存储的格式是类似的,而且每种基本都够用了,所以这里只分析下Static Protocol Definition
Static Protocol Definition — boofuzz 0.4.0 documentation
Protocol Definition — boofuzz 0.4.0 documentation
数据分成三个层次,Request是发出的message,Blocks来组成message,Primitives是组成block的元素
其组成图如下
Request.stack
string1
bytes1
block1
string2
block2
string3
bytes2
s_initialize
s_initialize会创建一个request,我们需要提供一个name来标识这个request,新建的Request会被加到REQUESTS中,并设置为当前操作的Request
1 | def s_initialize(name): |
Request的初始化函数
Request.init
1 | #对图初始化,新建一个root节点 |
s_get s_switch
网络协议一般是各种Request的状态转移图,Boofuzz也支持建立这种图,我们可以再次调用s_initialize来创建一个新的Request,通过s_get可以在不同的Request直接切换,从而改变当前操作的对象
1 | def s_get(name=None): |
connect
connect是连边,即在两个Node(Request)上连边,只填一个参数的话,就是默认把提供的参数node练到root上,node就是Request对象,
1 | def connect(self, src, dst=None, callback=None): |
这个Connection 就是继承自最朴素的Edge (边),只不过其提供了一个callback参数,这个会在状态转移的时候调用,因此可以添加一些自定义的功能
1 | class Connection(pgraph.Edge): |
状态图案例
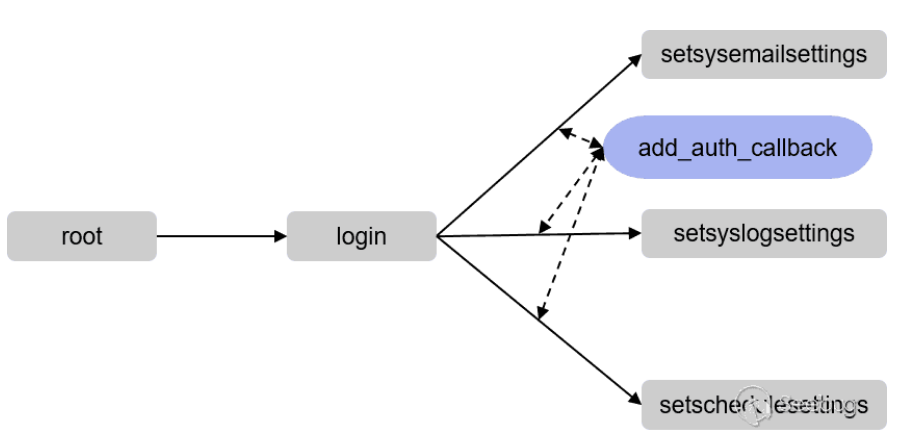
创建完Request之后,接下来就是向里面添加Primitives,根据数据类型划分出多个添加函数,首先看看string类型的函数s_string
函数中新建String对象后,通过Request的push函数填充到request中
s_string
1 | def s_string(value="", size=None, padding=b"\x00", encoding="ascii", fuzzable=True, max_len=None, name=None): |
Request.push
1.首先给传进来的item也就是Primitive添加一些环境信息:
(1)context_path: 调用_generate_context_path产生的字符串,_generate_context_path是将block_stack中的字符串全部拼接在一起产生路径字符串,用于标记item的位置
(2)设置item的request为当前request
2.将item的qualified_name加入到names map中,用于监测重复插入
3.如果当前request还没有block,block_stack就为空,就将item插入到整体的stack中,如果block_stack不为空,就相当于现在还在组建block,就把item插入到栈顶的block中
4.如果item是block,会先把block插入到stack中,然后插入到block_stack中作为当前的open_block,接下来的primitive都会插入到block里面
1 | def push(self, item): |
block
根据doc,有两种插入block的方式with 和startend模式
startend方式
s_block_start 初始化一个block,并将其push
s_block_close 关闭这个block,说明数据已经填充完毕了
1 | if s_block_start("header"): |
s_block_start
1 | def s_block_start(name=None, *args, **kwargs): |
s_block_end
1 | def s_block_end(name=None): |
with方式
1 | with s_block("header"): |
with方式能用是因为s_block中调用的是s_block_start插入block,但是返回的是个ScopedBlock对象,这个对象注册了exit方法
当with范围结束时,就会调用s_block_end方法
1 | def s_block(name=None, group=None, encoder=None, dep=None, dep_value=None, dep_values=None, dep_compare="=="): |
start fuzz
fuzz
fuzz开始于fuzz函数,传入一个request的name的话就会只fuzz这个request,不传就会按建立的图去遍历着fuzz
1 | def fuzz(self, name=None, max_depth=None): |
_main_fuzz_loop
1.首先会开启一个boofuzz的可视化web server
2.调用_start_target启动target,一般测试服务器的时候,是我们手动启动目标服务器,所以用不到这个,但是配合ProcMonitor我们可以设置自启动目标(Windows平台)
3.记录fuzz开始时间
4.开始fuzz大循环,每次循环调用_fuzz_current_case进行fuzz
5.num_cases_actually_fuzzed+1,如果_index_end参数不为空且total_mutant_index>=_index_end的话就结束fuzz
6.记录fuzz结束时间
这里还有个选项是_reuse_target_connection,重用连接,开启这个选项后,整个大循环中只会在这里open一次连接,如果不开这个选项,每次fuzz都会重新open一次连接
1 | def _main_fuzz_loop(self, fuzz_case_iterator): |
1 | try: |
_start_target
内部调用monitor的start_target来启动目标,目标启动后,调用monitor的post_start_target回调函数
1 | def _start_target(self, target): |
_fuzz_current_case
1.打印一些信息
2.调用_open_connection_keep_trying打开连接,在这里可以实现自定义的网络状态monitor
3.调用_pre_send函数,这里会调用monitor中的pre_send回调函数(Session处填的pre_send_callback会复制到CallbackMonitor的on_pre_send中,这里pre_send就会调用它们)具体可以看后面单独对CallbackMonitor的分析
4.调用edge的callback函数,产生callback数据
5.调用transmit_fuzz进行测试数据的收发
6.调用_check_for_passively_detected_failures函数检查是否发生了crash
根据设置的sleep_time参数暂停
1 | def _fuzz_current_case(self, mutation_context): |
_open_connection_keep_trying
在不开启_reuse_target_connection的情况下调用target的open函数,代码中已经实现了自定义的网络状态monitor
1 | def _open_connection_keep_trying(self, target): |
_pre_send
依次调用target的monitor中的回调函数
1 | def _pre_send(self, target): |
_callback_current_node
调用当前边edge的callback函数,并返回callback数据
1 | def _callback_current_node(self, node, edge, test_case_context): |
_check_for_passively_detected_failures
依次调用monitor的post_send函数来获取是否发生了crash,如果发生了crash就继续调用get_crash_synopsis函数来获取crash概要
1 | def _check_for_passively_detected_failures(self, target, failure_already_detected=False): |
transmit_fuzz
进行实际的数据收发
1.判断是否传入了callback数据,如果有callback数据就使用callback数据,否则调用render来产生变异数据
2.发送数据,并将发送的数据保存在last_send中
3.接受数据,并将接受的数据保存在last_recv中
last_send和last_recv都非常重要,last_send可以在监测crash时dump出来作为crash样本,last_recv则可以在边回调中决定状态机的走向,以及产生callback数据
1 | def transmit_fuzz(self, sock, node, edge, callback_data, mutation_context): |
crash dump
上面只介绍到监测crash而没说哪里dump crash,实际上crash的dump在各个Monitor中(在_fuzz_current_case函数中是没有的)
以Procmon的DebugThread为例
1 | def post_send(self): |
到此为止,数据的收发流程基本就了解了,剩下需要看下数据是怎么从request中产生并变异的
数据变异
_generate_mutations_indefinitely这里会产生一个iterator,迭代产生mutation_context
1 | if name is None or name == "": |
_generate_mutations_indefinitely
这里max_path默认传进来是个none
调用_generate_n_mutations来产生mutation_context
depth是在一次fuzz_case中,产生几个变异体,depth为1,那就是一次就变异一个primitive
_generate_mutations_indefinitely
1 | def _generate_mutations_indefinitely(self, max_depth=None, path=None): |
_generate_n_mutations
这里会先得到path再从path里得到要fuzz的node
1 | def _generate_n_mutations(self, depth, path): |
_iterate_protocol_message_paths
先检查下是否有target 以及从root发出的边
如果指定了path,就直接返回指定的path,但是默认都是空
调用_iterate_protocol_message_paths_recursive遍历path
1 | def _iterate_protocol_message_paths(self, path=None): |
_iterate_protocol_message_paths_recursive
这里遍历path的方法使用的是DFS,只不过用yield实现的,看着有些别扭,最终会产生从root出发的所有路径
1 | def _iterate_protocol_message_paths_recursive(self, this_node, path): |
知道path如何产生的之后再回去看MutationContext是怎么产生的,_generate_n_mutations_for_path函数对传进来的path产生mutation_context,mutation_context就是代表这次case的变异体上下文,depth是标识一个fuzz_case使用几个变异体,默认为1
那么MutationContext的mutations就只有一个qualified_name
_generate_n_mutations_for_path
1 | def _generate_n_mutations_for_path(self, path, depth): |
_generate_n_mutations_for_path_recursive
调用_generate_n_mutations_for_path_recursive 产生mutation集合
mutaions由两个部分组成,一个是_generate_mutations_for_request函数产生的
1 | def _generate_n_mutations_for_path_recursive(self, path, depth, skip_elements=None): |
_generate_mutations_for_request
设置fuzz_node为当前路径上的最后一个node,之后调用fuzz_node的get_mutations,fuzz_node是一个request对象,所以这里调用的是request的get_mutations方法
1 | def _generate_mutations_for_request(self, path, skip_elements=None): |
request.get_mutations
Request继承自FuzzableBlock,mutations是FuzzableBlock的方法
1 | def get_mutations(self, default_value=None, skip_elements=None): |
FuzzableBlock.mutations
遍历当前request的stack中的item,也就插入的block和primitive,再调用他们的get_mutations函数得到mutation
primitives都继承自fuzzable,所以这里调用的是fuzzable的get_mutations
1 | def mutations(self, default_value, skip_elements=None): |
fuzzable.get_mutations
这个函数就是对当前item进行变异,并将变异的值传到生成的Mutation里面
Mutation的构造这里就能看到,是由一个值value,一个所属item的qualified_name,以及变异计数index组成的
这里终止变异用的是_halt_mutations标志,而stop_mutations函数是提供的接口,其内部就是设置_halt_mutations为true
itertools.chain的功能就是合并列表,所以这里值得来源就为self.mutations(self.original_value()),self._fuzz_values
其中_fuzz_values在Fuzzable的init函数中是可以作为构造参数传入的,但是String(继承自Fuzzble)的构造函数里并没有这个参数,所以就没找到接口设置这个值(除了手动赋值),所以这里总是空列表
下面会以String为例,分析了其mutations函数
1 | def get_mutations(self): |
stop_mutations
1 | def stop_mutations(self): |
String.mutation
这里进一步可以看到变异值有三个来源:
_fuzz_library 可以理解为预置的容易产生crash的字典
_yield_variable_mutations(default_value) 对default_value进行重叠以产生变异值
_yield_long_strings(self.long_string_seeds) 带点随机性的变异,(随机替换字符为终结符)
1 | def mutations(self, default_value): |
_fuzz_library (只贴了一部分)
1 | # store fuzz_library as a class variable to avoid copying the ~70MB structure across each instantiated primitive. |
_yield_variable_mutations
重叠产生变异值
1 | _variable_mutation_multipliers = [2, 10, 100] |
_yield_long_strings
这个函数有两部分,第一部分仍然是采取重叠的策略来产生变异值,只不过seed来自于long_string_seeds
random.sample(list,size)的功能是随机抽样,从list中抽size个 数
第二部分是先按_long_string_lengths中的长度产生一个D*size的字符串,然后再随机将其中的字符替换成/00,这是整个String的变异过程中唯一随机的部分。替换哪些位置的字符是在String初始化时已经按_long_string_lengths中的长度初始化过了(random_indices)
1 | #传进去的sequences |
总结数据变异流程
一次fuzz_case所用的变异数据来自于mutation_context,mutation_context由message_path和mutations组成
mutations产生于primitive,对primitive的一次变异产生一个mutation,mutation中包含变异值和所属的primitive的qualified_name
根据传入的depth的数值,mutation_context可以包含多个mutation,只不过默认值depth为1,因此mutation_context一般就包含一个mutation
1 | #session._main_fuzz_loop() |
变量total_mutant_index标记产生了多少mutation_context,也就等同于fuzz_case的次数
变量mutant_index标记产生了多少mutant(mutation),在depth为1的情况下,mutant_index就等于total_mutant_index
而mutation的产生则是首先会遍历出状态图的所有path,然后对path中最后一个node中的item进行变异
其他细节
这里再分析下刚才没提到的一些细节,其实整体框架和流程已经分析完了,但是对这些小细节也比较清楚的话,能更好的了解boofuzz
qualified_name
我们创建primitive时一般只给个default_value,这样在Fuzzable里,就会默认赋值个name,格式是类型加计数,例如String1 String2
primitive的context_path是在push的时候赋予的,标记着的是其在request中的位置
最后qualified_name的产生是将context_path和name拼接在一起
1 | #Fuzzable._init() |
path数据发送
前面已经介绍了变异值数据产生和数据发送,但是实际上数据产生和数据发送间还有一些细节没分析
为了贴合网络协议,boofuzz在发送变异数据前,会先把其path上的正常数据先都发送过去,变异mutation都是在path的最后一个node上
1 | #seesion._fuzz_current_case() |
transmit_normal
如果callback_data不为空就发送callback_data,否则发送render(mutation_context)
1 | def transmit_normal(self, sock, node, edge, callback_data, mutation_context): |
request.render
这个函数流程前面也没分析,
1 | def render(self, mutation_context=None): |
request.get_child_data
这个函数遍历request中的item,来拼接出数据,item基本都继承自Fuzzable(除了Block)
1 | def get_child_data(self, mutation_context): |
Fuzzable.render
调用get_value获取值
1 | def render(self, mutation_context=None): |
Fuzzable.get_value
就是如果当前item在mutation_context的qualified_name中,就返回变异值,否则就返回初始值_default_value
1 | def get_value(self, mutation_context=None): |
original_value
因为传进来的都是ProtocolSession对象,所以走else分支返回_default_value
1 | def original_value(self, test_case_context=None): |
继续上面数据发送的位置,path上的正常数据发送完之后才会发送变异数据
1 | prev_node = self.nodes[mutation_context.message_path[-1].src] |
Monitor
boofuzz只提供了三种monitor,
ProcessMonitor大概是和Procman 进行rpc通讯来监控
NetworkMonitor具体用法不太清楚,看doc里说用了wireshark
CallbackMonitor是默认的Monitor,提供回调函数的功能
我们一般需要一个监控连接状态的Monitor,如果连接失败则判定为发生了crash,保存crash样本,前面代码中有我实现的简陋的方案
CallbackMonitor
这个Monitor是以Monitor的形式提供几种callback,在session的init函数中,是把传进来的callback赋值给CallbackMonitor,这个Monitor也是会默认
1 |
|
前面回调函数都是用的target的monitor的回调,在session的init中首先设置了_callback_monitor为刚才创建的CallbackMonitor,其给target设置的有些隐蔽,是在add_target中设置的
add_target
1 | def add_target(self, target): |
pre_send
以CallbackMonitor的pre_send为例,可以看到其遍历on_pre_send函数来调用
1 | def pre_send(self, target=None, fuzz_data_logger=None, session=None): |
Refs
jtpereyda/boofuzz: A fork and successor of the Sulley Fuzzing Framework (github.com)
Monitors — boofuzz 0.4.0 documentation
Boofuzz - A helpful guide (OSCE - CTP) - Zero Aptitude (archive.org)
IoT设备固件分析之网络协议 fuzz (seebug.org)
Network & Process monitoring - practical examples · Issue #315 · jtpereyda/boofuzz (github.com)