Android抓包及爬虫研究 - 1
又忙活了一阵子项目,期间简单回顾了下原先对于Andorid的抓包,以前研究的都比较零散,这里写个总结,为什么是1,因为抓包还是门技术活,这里介绍得是一些通用原理,以及通用方案,后面有机会再学习总结一下更高级的方法。至于爬虫则是最近搞了个小目标,所以记录下怎么写爬虫。
Android抓包原理
https是在Http加了一层SSL/TLS,即在HTTP通信前,进行身份验证,同时对HTTP报文进行加密处理
在此过程中会涉及到对双方的证书认证,客户端对服务端的证书认证是必须的,服务端对客户端的证书认证则是选择的,证书文件是由第三方可信任机构颁发的。
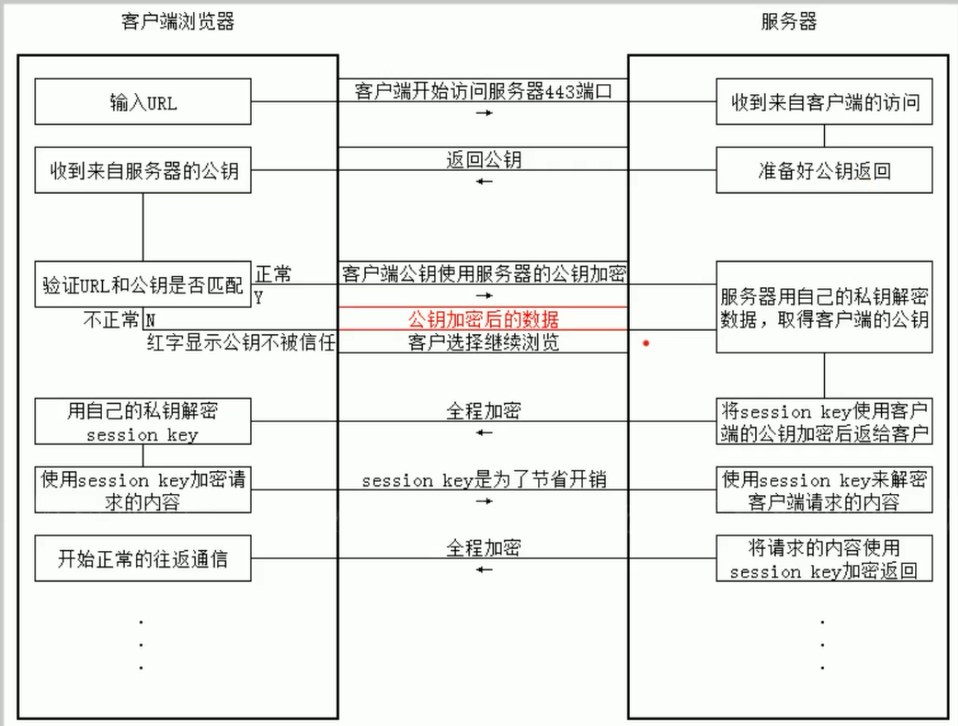
由于HTTP报文是明文的,而且不涉及到任何身份认证,因此只要简单设置代理,即可完成抓包。
对于HTTPS的抓包,也是基于中间人的方式,如下图
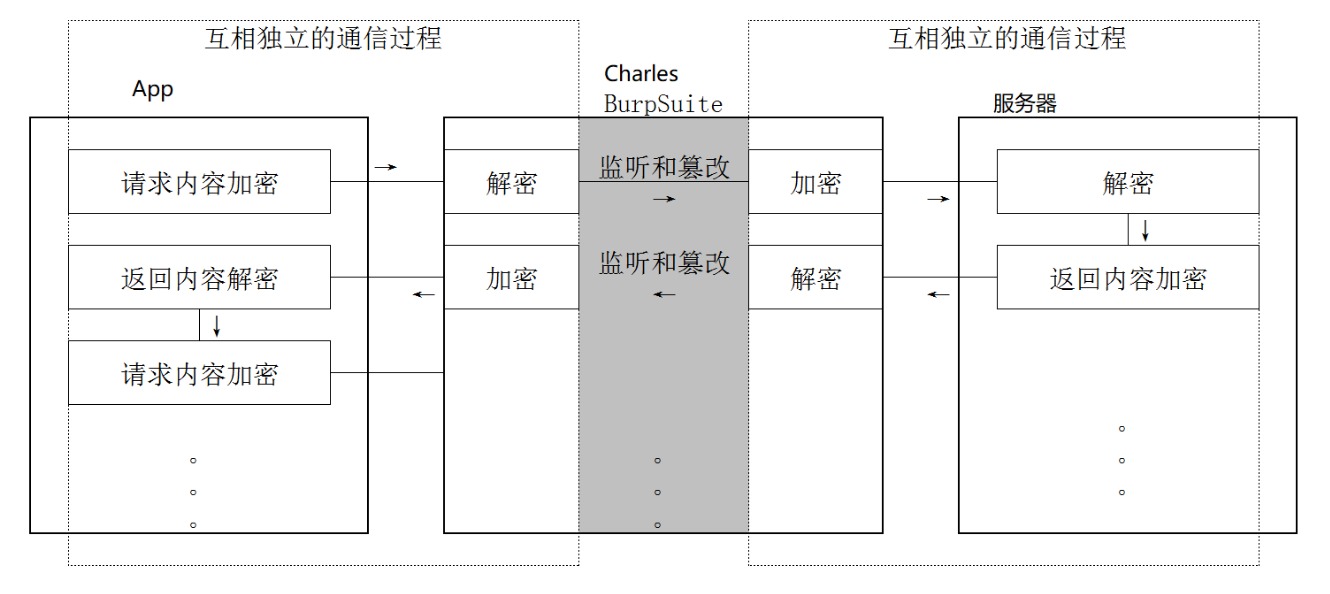
以Charles为例,首先需要让我们的客户端(Android系统)信任Charles,即将Charles证书添加到系统信任证书列表中,这样当Charles被设置成代理后,其会代替我们客户端访问服务器,并将返回服务器返回的内容,此时从客户端的视角来看,Charles是目标服务器,但是由于我们已经信任了Charles,所以可以正常完成HTTPs的通信过程。
对抗策略
SSL Pinning
证书绑定,不仅会校验服务器证书是否是系统中的可信凭证,而只信任APP指定的证书,一旦发现服务器证书为非指定证书即停止通信,所以即便将Charles证书安装到系统信任凭据中也无法生效
由于SSL Pinning的功能是开发者自定义的,并不存在一个通用的解决方案,所以反制手段需要通过Hook校验服务器的代码,使得校验失效
一些相对通用的方法,对常见的校验方式的反制
在objection中可以直接执行下面命令
android sslpinning disable
另外开源项目DroidSSLUnpinning也添加了一部分Objection中没有的Bypass证书校验的方式
服务端校验客户端
这种方式发生Https 验证身份阶段,服务端会验证客户端的证书,如果不是信任的客户端证书就终止通信
Charles操作
Charles安装
Charles证书安装
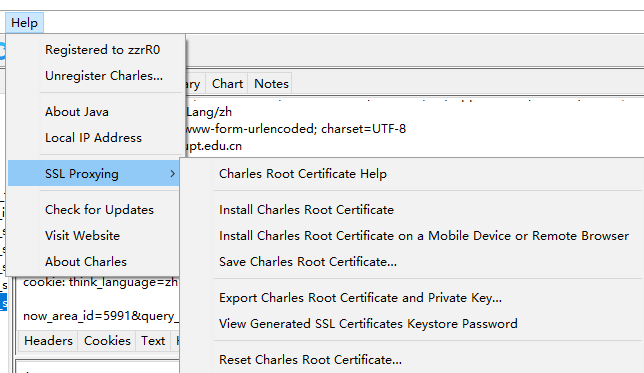
远程安装在手机上需要先设置Charles的代理,然后访问chls.pro/ssl,即可安装证书到Android系统
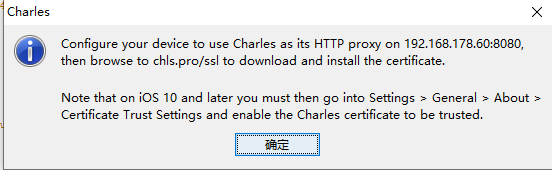
Charles代理设置
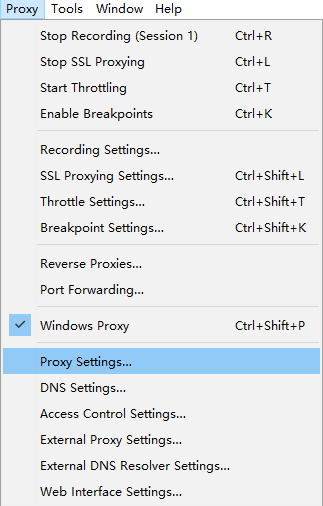
在这里设置代理
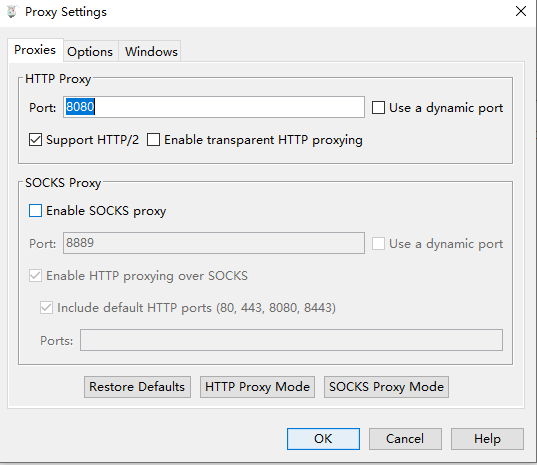
这里设置SSL 代理
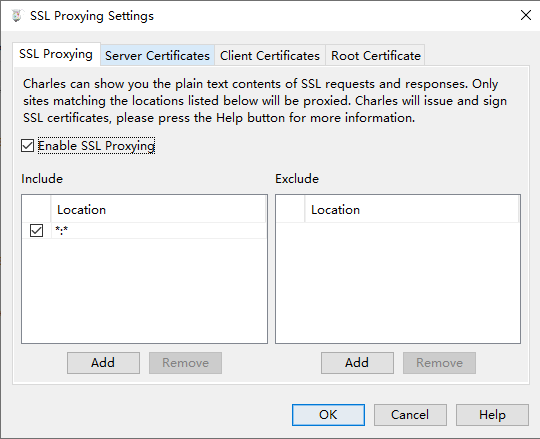
要抓Https的包,这里要开启SSL Proxying,同时添加ip过滤里加上**,就可以抓全部的Https包
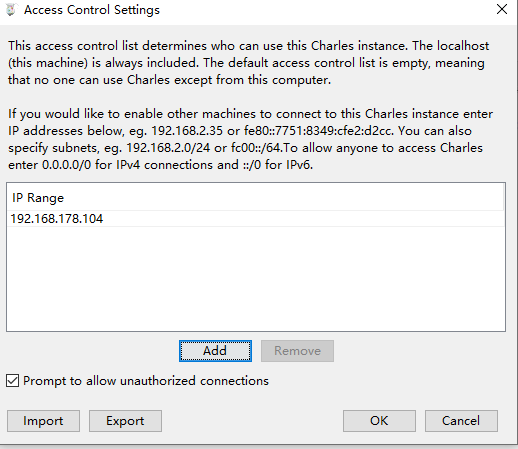
有时候可能误点了Deny ip地址,导致抓不到包,可以在Proxy-> AccessControlSettings里面看到
这里的三个按钮,分别是清空历史,开始抓包,开启SSL
Charles客户端证书
从App中提取出客户端证书后,可以在这里把客户端证书添加进去
手机代理设置
代理原理
代理一般分为两种,Https代理和Socks代理
具体Android是怎么设置代理的,我现在还是太清楚,但是根据现有的知识,Https代理是把代理设置到应用层,假设代理方式是修改hosts,把所有的网址重定向到Charles上,那么App可以轻易检测出当前https被重定向了,
而socks代理则是把代理设置到协议层,也就是TCP/UDP这一层,把所有socket的链接建立重定向到Charles上,Charles这边应该是自己实现的识别上层协议是否是Https,如果是就进行代理,那App进行的一些应用层检测可能就会失效。
总的来说就是代理的越深,能过得检测就越多。
http代理
可以直接通过adb用下面指令设置代理/关闭代理
1 | adb shell settings put global http_proxy ip:端口 |
通过网络,高级设置里面也能设置代理,但是时灵时不灵
ip相关问题
设置代理的前提得部署charles的电脑跟手机是通的,如果是真机的话,只要手机跟电脑连到同一个wifi就行了,当然也可以电脑开热点(没法开热点的电脑需要单独再配个无线网卡)

手机只要连上电脑开的热点就行
手机ip设置比较简单,用模拟器比较麻烦,以雷电模拟器为例
需要先在这里选择桥接模式,然后要装个驱动,选择正确的网卡,当选择桥接模式后,要注意此时不能连到带有那种网页认证的网络上(比如校园网),桥接不一定能连上分配到ip,这种解决方案是手机去连,然后手机开热点,电脑再连手机热点开桥接模式。
另外adb连上shell后,可以直接用ifconfig查看ip
socks代理
socks代理就需要借助软件了,Brook就可以设置socks代理
手机证书设置
Android 7.0以上,SSL证书划分成系统分区和用户分区了,直接访问Charles证书的网址,只会把证书安装到用户分区,如果抓不到包,就需要把Charles证书移到系统分区
1 | adb shell |
这个修改系统分区权限的操作,需要刷的系统是userdebug版本的,要不然会修改不了(自己手动编译的系统就是userdebug版本的),别的下载的系统可能就会出现问题
以夸克浏览器为例,打开charles的网址之后会下载pem证书到/sdcard/Quark/Download
这时候需要进入设置 -> 安全性和位置信息 -> 加密与凭据 -> 从存储设备中安装 -> 选中这个PEM安装
之后再执行上述指令,如果出现下面错误,
1 | walleye:/ # mount -o remount,rw /system |
先尝试下面命令
1 | $adb root |
如果还是不行,那就尝试修改整个/ 而不是/system
1 | # cd /data/misc/user/0/cacerts-added/ |
Android10导入系统证书,这个还没实践过,目前还没刷过Andorid10.0的系统
(32条消息) Android10导入系统证书的方法。fjh1997的博客-CSDN博客安卓导入根证书
这里还有个项目
Magisk-Modules-Repo/movecert: movecert (github.com)
简单爬虫
爬虫库非常的多,只用urllib就能完成请求了
1 | import urllib.request |
Get请求示例
1 | def getMsgUnionId(): |
url 和header我们要先准备好,基本上爬虫就没用不需要定制header的,一般是抓包之后一摸一样的拷贝过来,少字段可能都会导致检测到,get请求不涉及到data,所以一般修改的就是cookie,
1 | request = urllib.request.Request(url,headers=header,method="GET") |
这两句就是构造request,urlopen就是发起请求
获取返回结果要用到下面这个,有的返回是html,有的返回就是json,这里是html,获取正文内容,还需要进行一次utf8解码,主要必须指定ignore,因为有的解码不了(疑惑)就会直接抛出异常,指定ignore之后解码失败的字节就会忽略而不是报错,这里就是不知道为什么会有的字节解码不了????
1 | html_text = response.read().decode("utf8","ignore") |
python - urllib.request.urlopen return bytes, but I cannot decode it - Stack Overflow
还有种情况是,返回的结果是经过gzip压缩的,那么就需要先解压一下
POST请求示例
1 | def RegisterNow(): |
post首先得注意data的类型,一般常见的有json和form-data,像这里就是form-data,有时候给服务器发什么类型都想,完全看服务器是怎么实现的,form-data就要在Content-type里写multipart/form-data,
form-data也比较特殊,需要根据data构造,urllib没提供相关方法,所以这里从网上抄了一段
1 | def encode_multipart(params_dict): |
最后要注意data-length的修改
综上就是怎么实现Get和Post,爬虫还有非常多的技术,以后再研究吧
Refs
《Android Frida 逆向与抓包实战》